La recherche à l’ère de l’IA David Pilato | @dadoonet
Slide 1

Slide 2

Agenda ● La recherche “classique” et ses limites ● Modèle de ML et usages ● La recherche vectorielle ou hybride dans Elasticsearch ● OpenAI ChatGPT ou LLM avec Elasticsearch
Slide 3

Elasticsearch You Know, for Search
Slide 4

Slide 5

Slide 6

These are not the droids you are looking for.
Slide 7
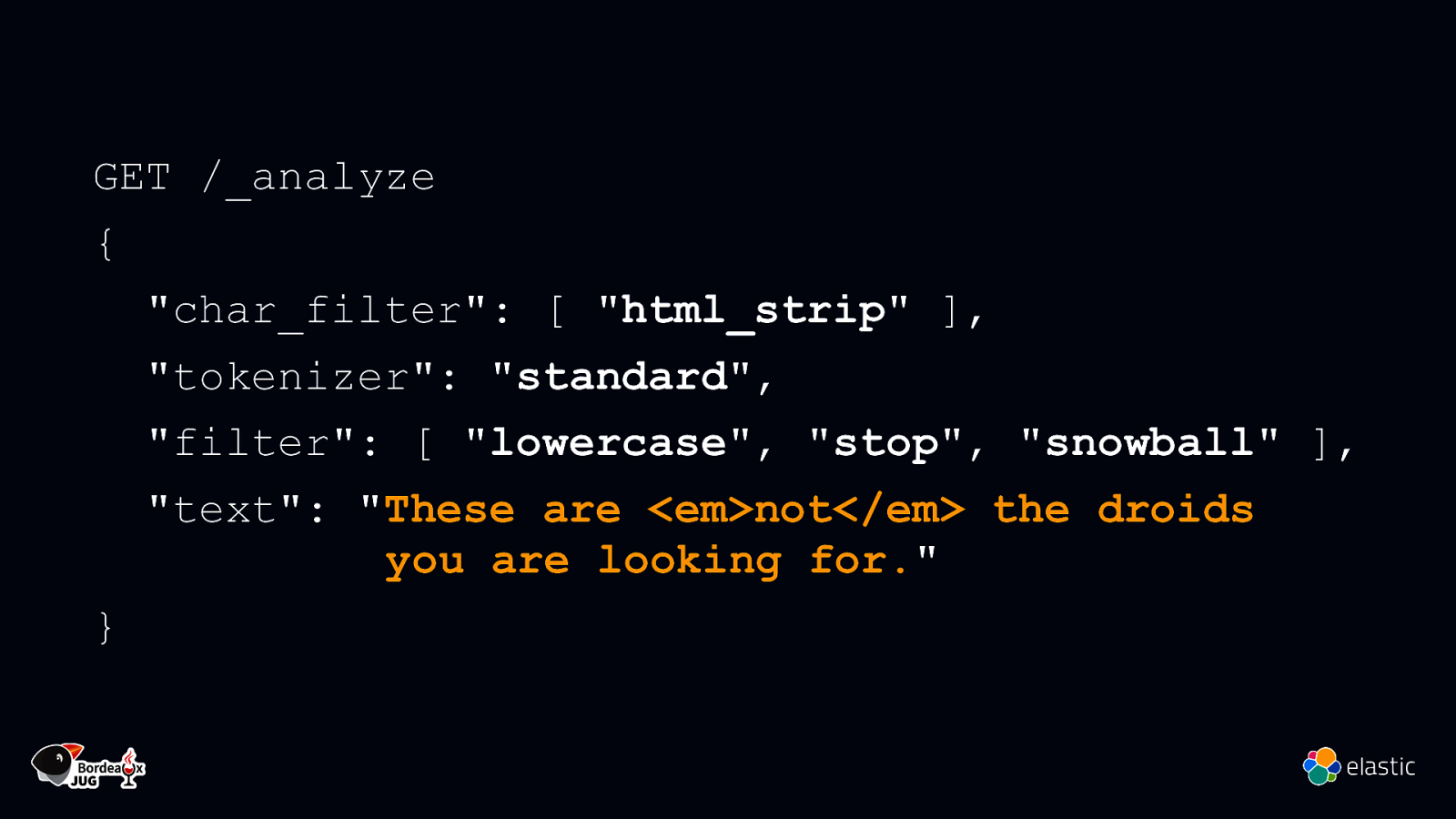
GET /_analyze { “char_filter”: [ “html_strip” ], “tokenizer”: “standard”, “filter”: [ “lowercase”, “stop”, “snowball” ], “text”: “These are <em>not</em> the droids you are looking for.” }
Slide 8
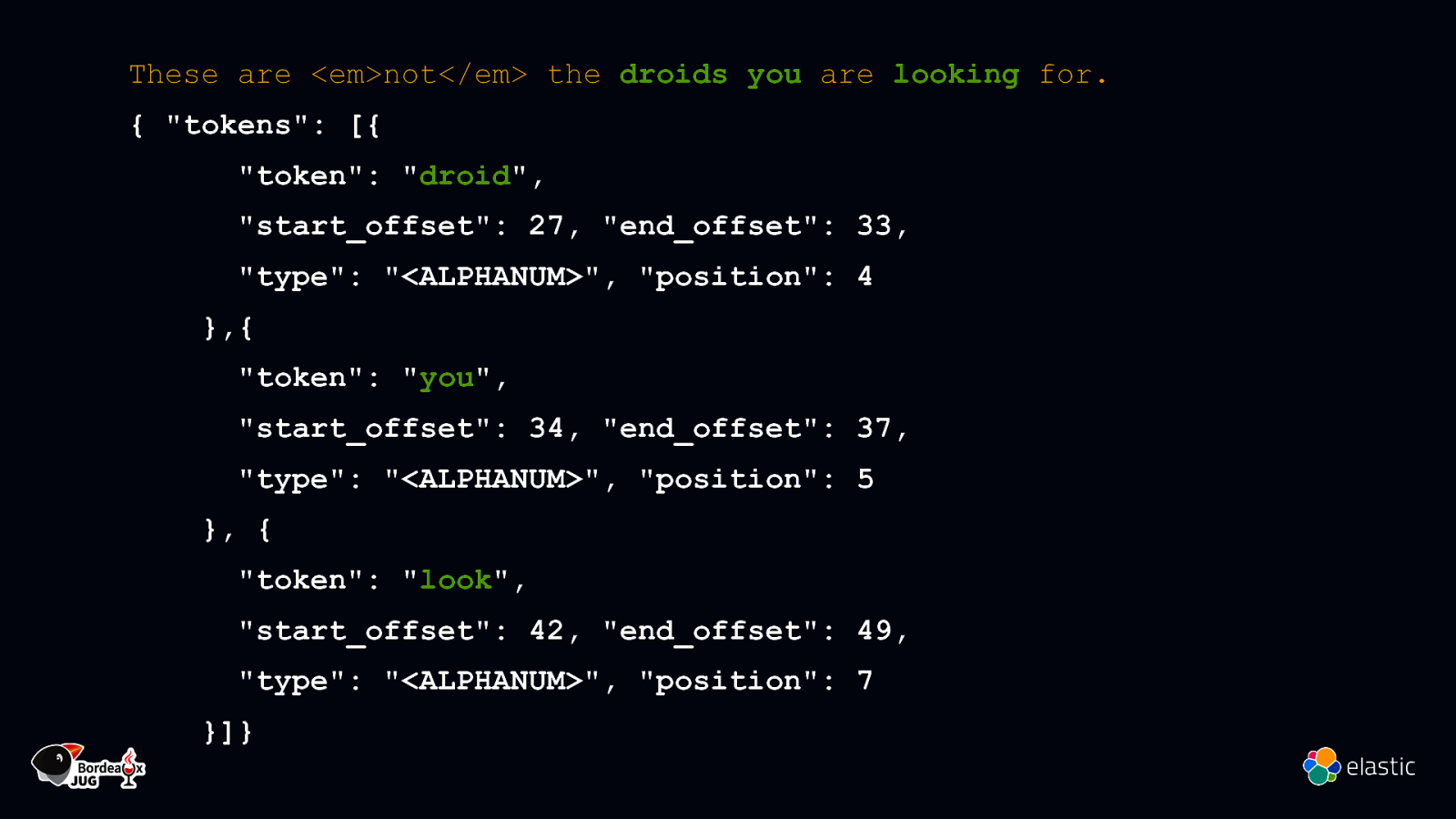
These are <em>not</em> the droids you are looking for. { “tokens”: [{ “token”: “droid”, “start_offset”: 27, “end_offset”: 33, “type”: “<ALPHANUM>”, “position”: 4 },{ “token”: “you”, “start_offset”: 34, “end_offset”: 37, “type”: “<ALPHANUM>”, “position”: 5 }, { “token”: “look”, “start_offset”: 42, “end_offset”: 49, “type”: “<ALPHANUM>”, “position”: 7 }]}
Slide 9

Recherche sémantique ≠ Correspondance littérale
Slide 10

AUJOURD’HUI Escadron de vaisseaux X-wing DEMAIN Quel vaisseaux et équipages faut-il pour détruire une étoile de la mort quasi achevée ? Ou existe-t’il une faiblesse cachée ?
Slide 11

Elasticsearch You Know, for Vector Search
Slide 12

Qu’est-ce qu’un Vecteur ?
Slide 13
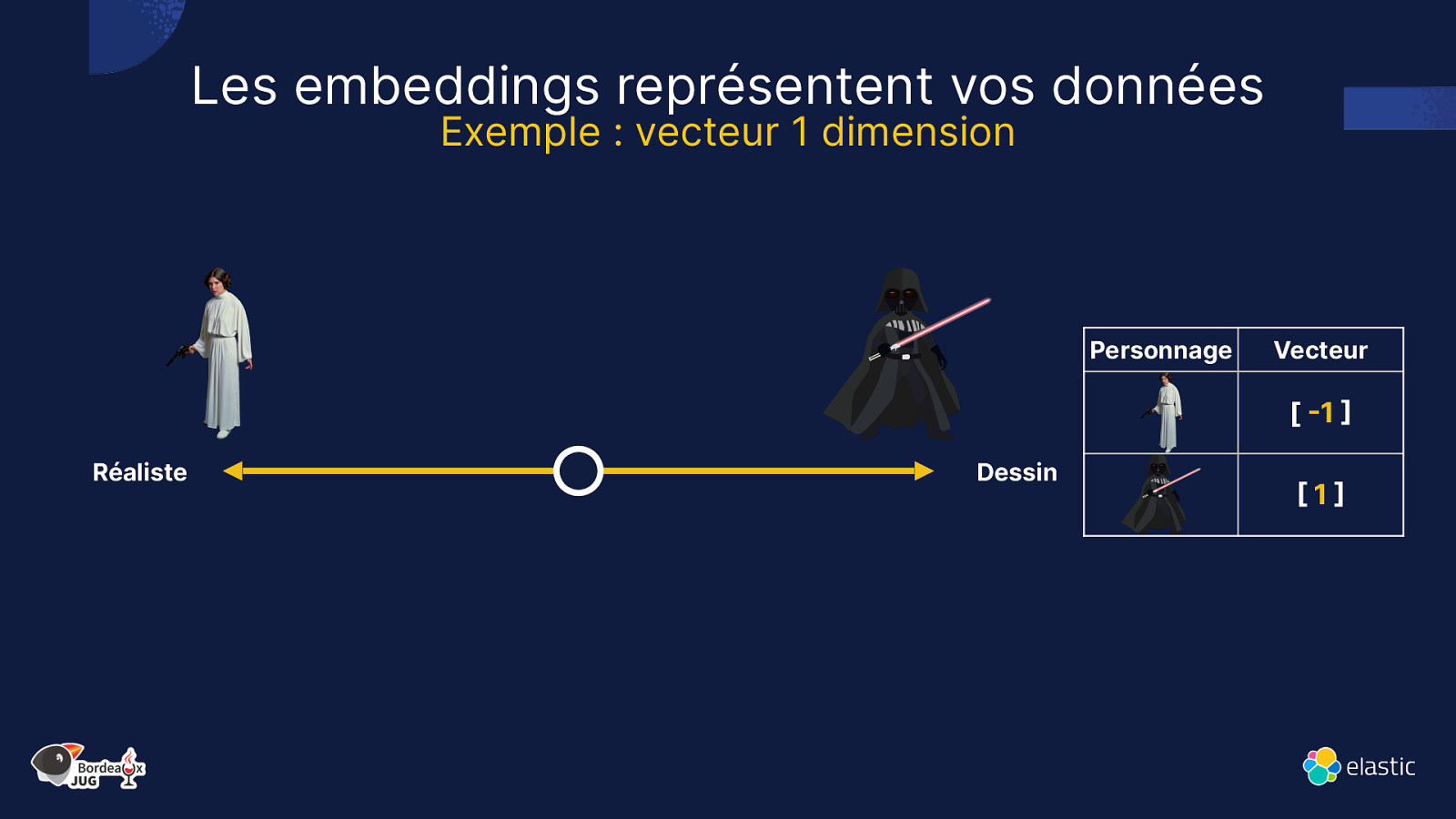
Les embeddings représentent vos données Exemple : vecteur 1 dimension Personnage Vecteur [ -1 ] Réaliste Dessin [1]
Slide 14
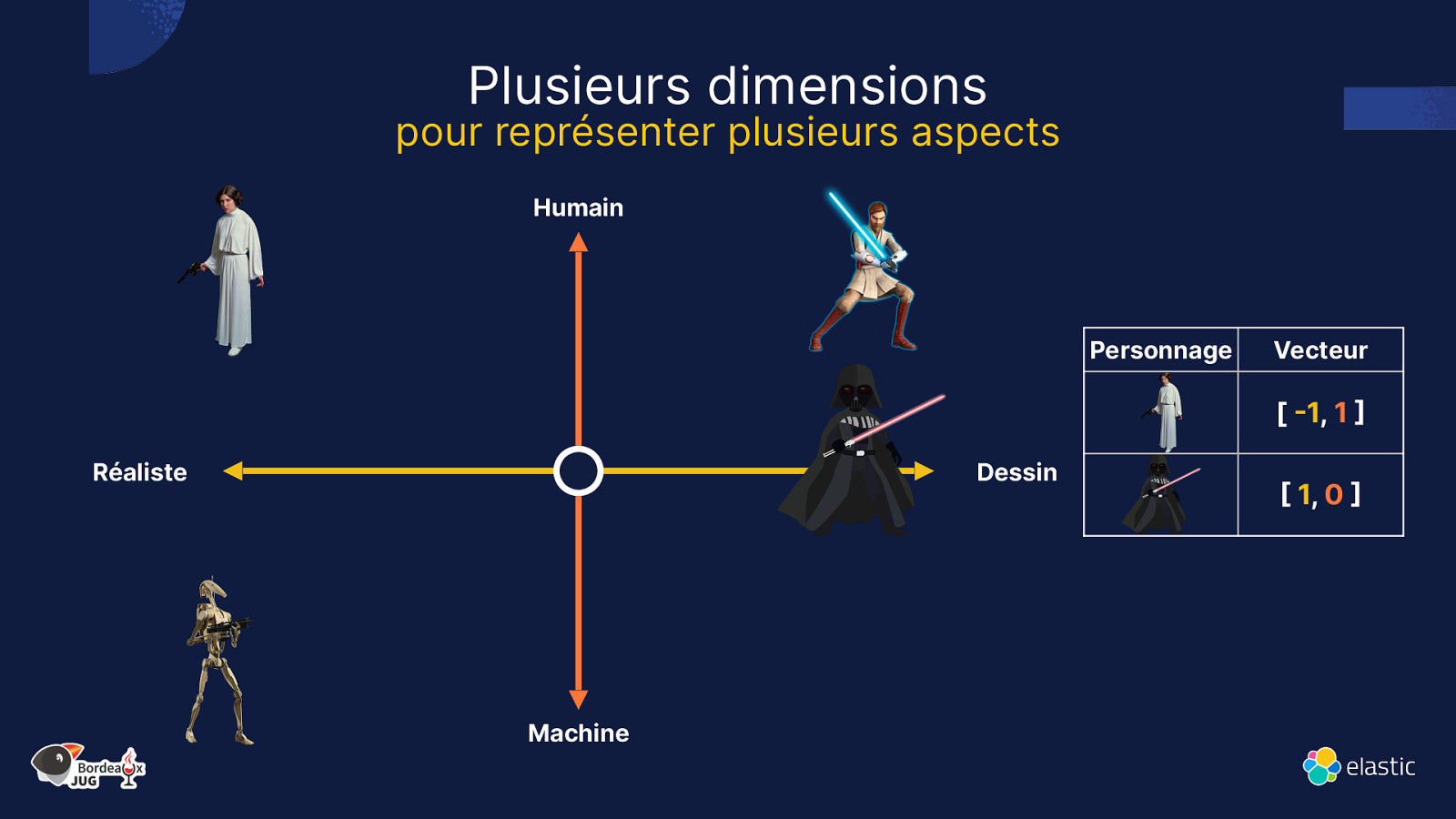
Plusieurs dimensions pour représenter plusieurs aspects Humain Personnage Vecteur [ -1, 1 ] Réaliste Dessin Machine [ 1, 0 ]
Slide 15
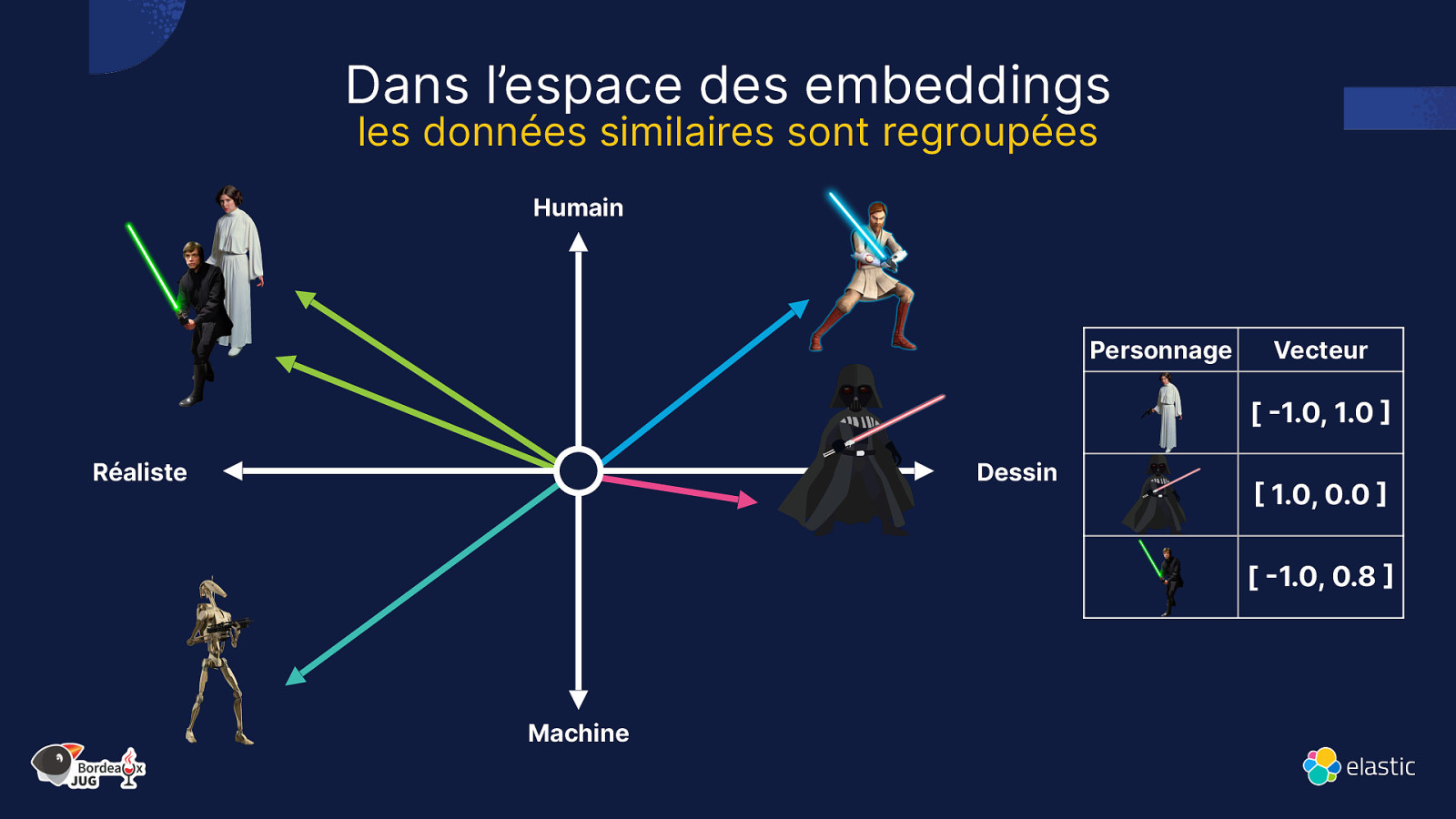
Dans l’espace des embeddings les données similaires sont regroupées Humain Personnage Vecteur [ -1.0, 1.0 ] Réaliste Dessin [ 1.0, 0.0 ] [ -1.0, 0.8 ] Machine
Slide 16

La recherche vectorielle classe les résultats par similarité (~pertinence) Humain Rank Requête 1 Réaliste Dessin 2 3 4 5 Machine Résultat
Slide 17
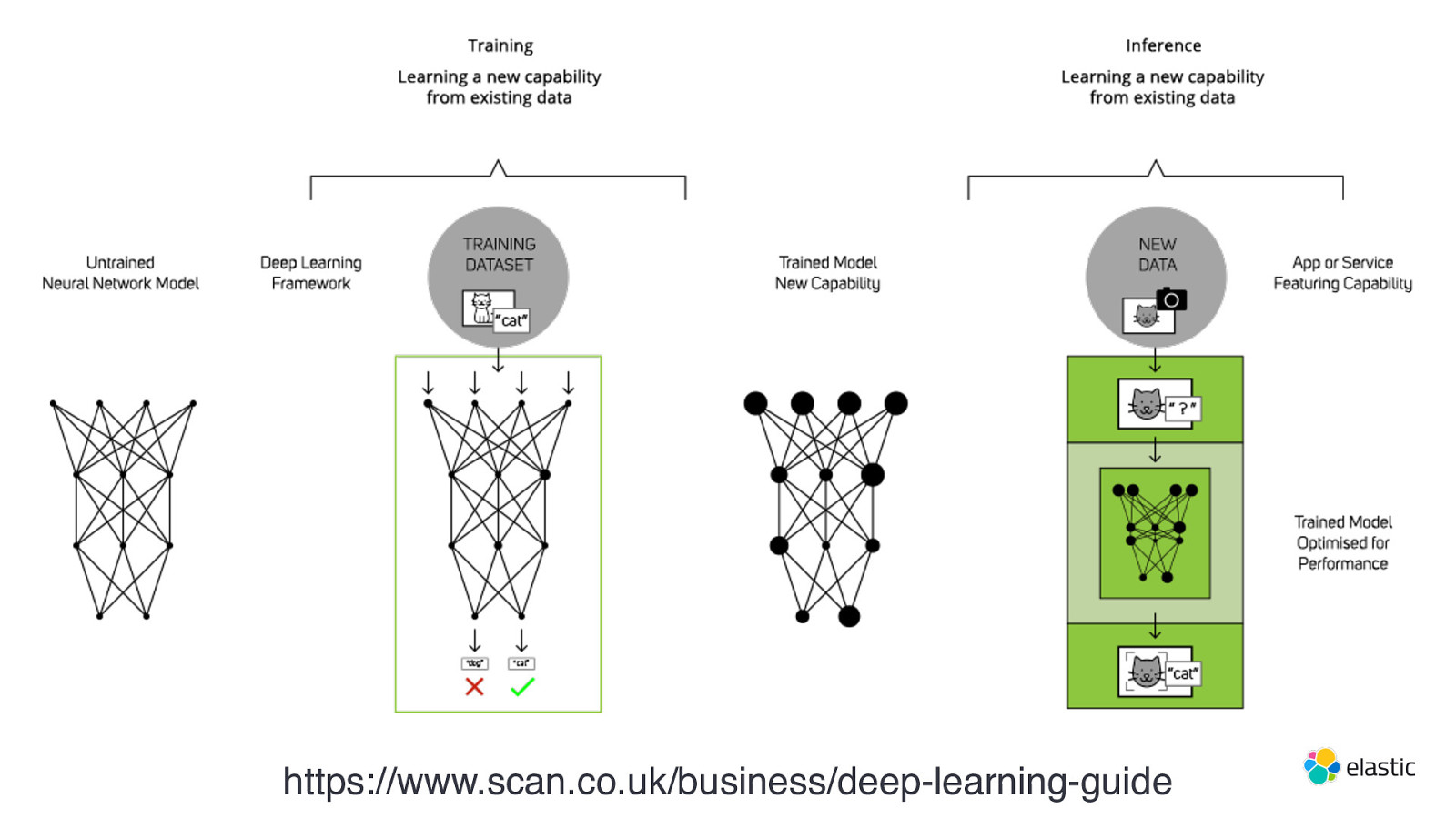
https://www.scan.co.uk/business/deep-learning-guide
Slide 18

Choisir son modèle d’Embedding Commencer avec des modèles sur étagère Développer pour une plus forte pertinence ●Text data: Hugging Face (comme Microsoft E5) ●Appliquer un scoring hybride ●Images: OpenAI’s CLIP ●Bring Your Own Model : nécessite de l’expertise + des données labelisées
Slide 19

Problème entraînement vs cas d’utilisation réel
Slide 20
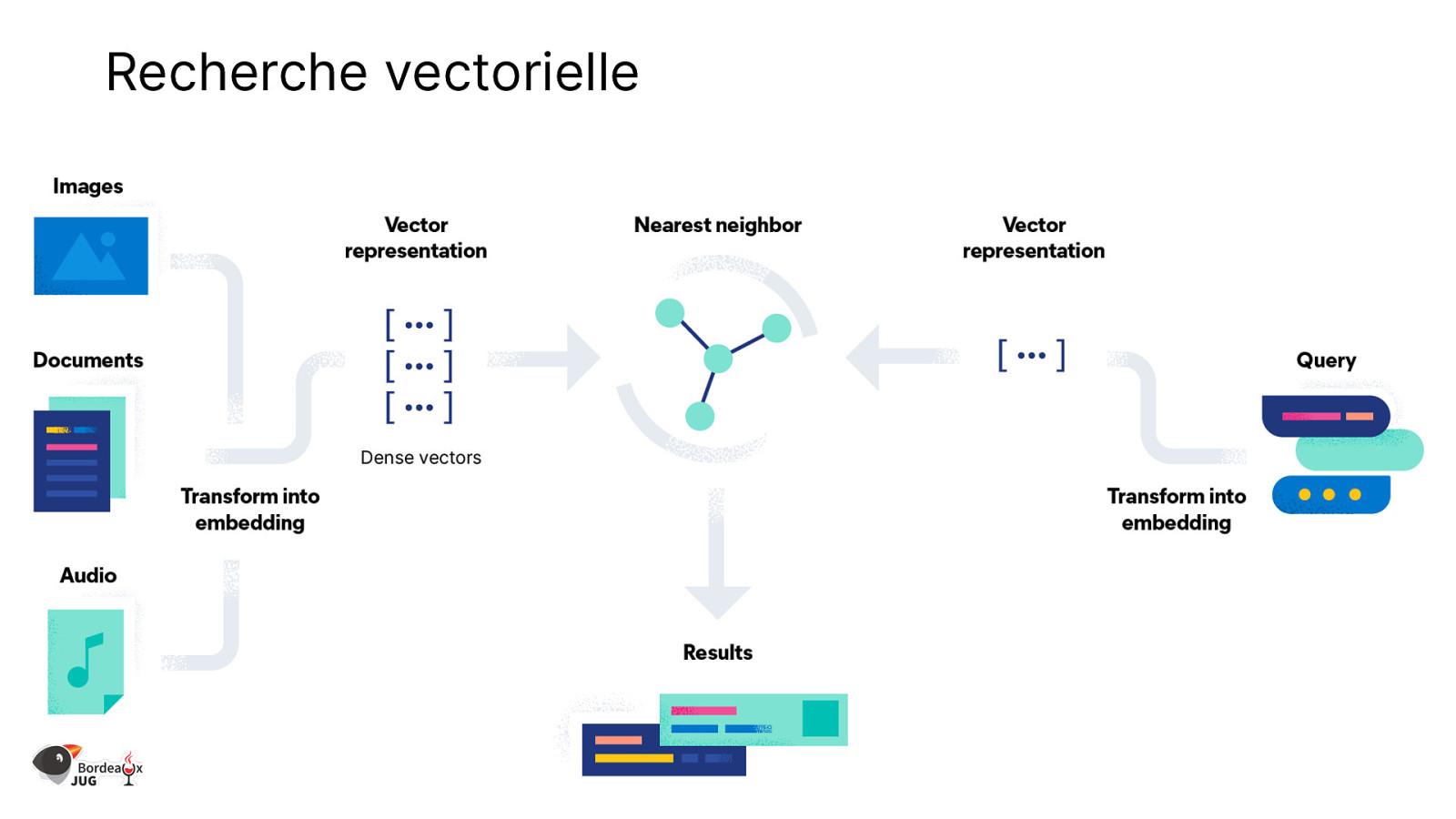
Recherche vectorielle
Slide 21

Comment indexer avec des vecteurs ?
Slide 22
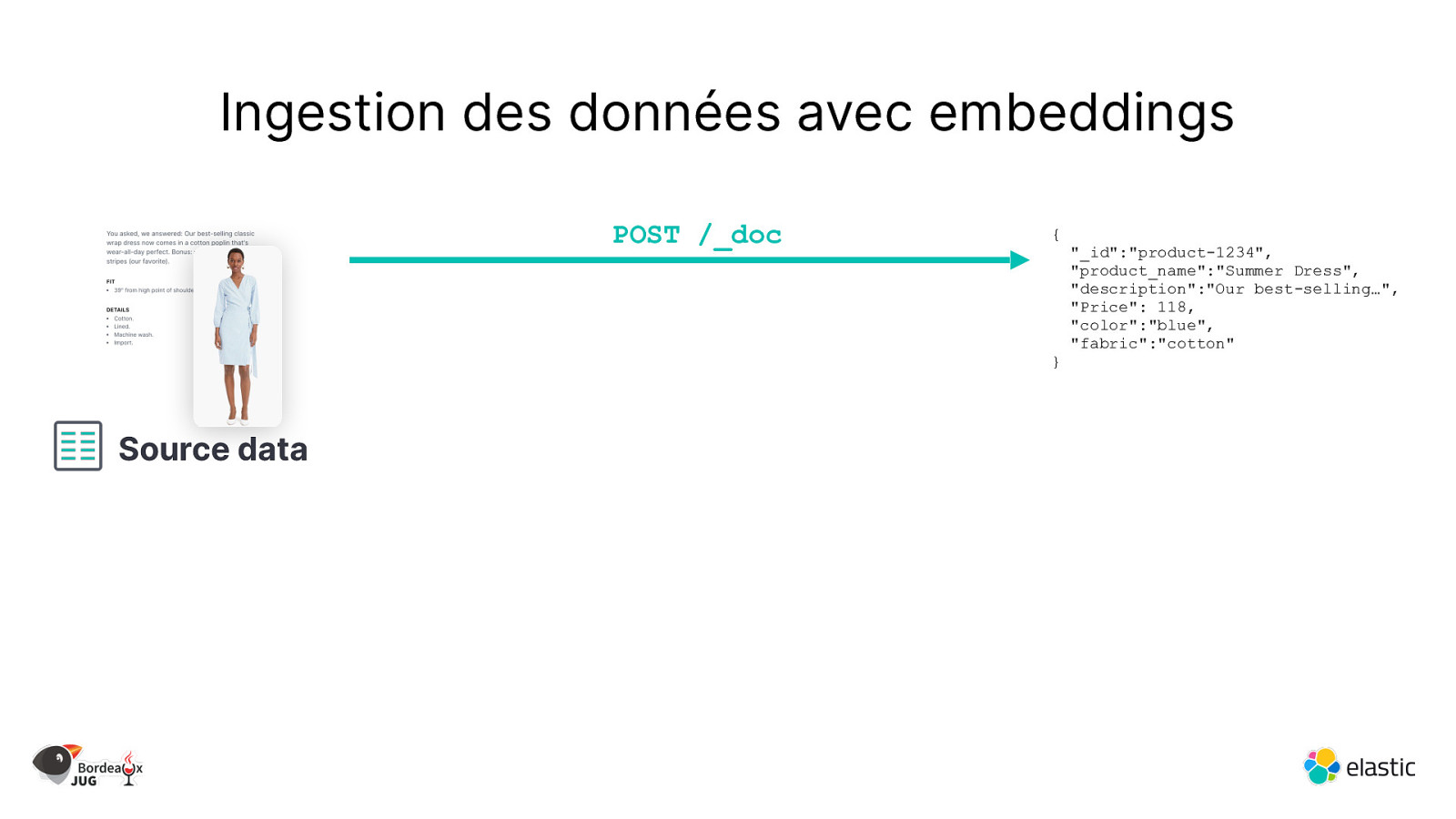
Ingestion des données avec embeddings POST /_doc { } Source data “_id”:”product-1234”, “product_name”:”Summer Dress”, “description”:”Our best-selling…”, “Price”: 118, “color”:”blue”, “fabric”:”cotton”
Slide 23
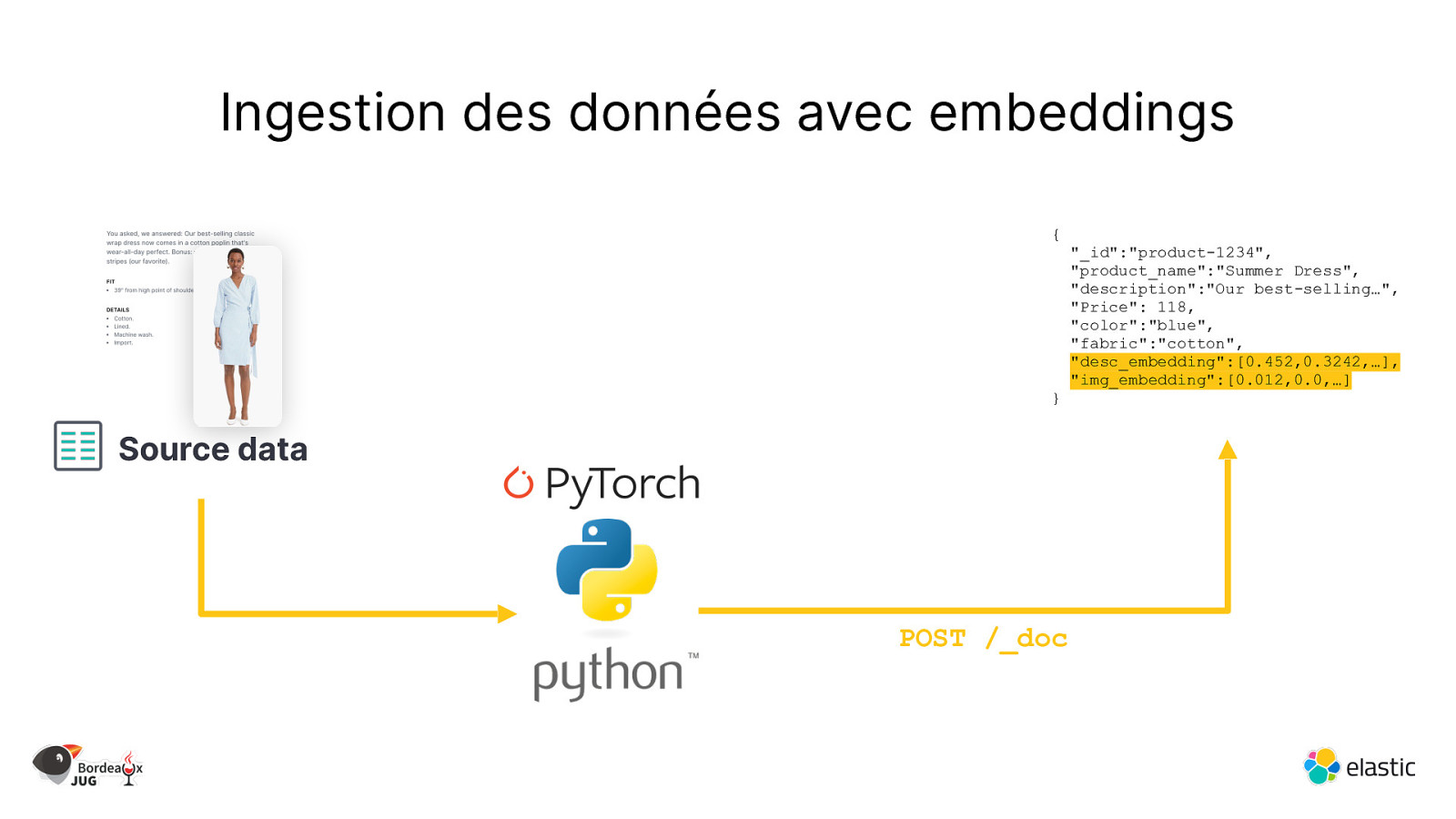
Ingestion des données avec embeddings { } Source data POST /_doc “_id”:”product-1234”, “product_name”:”Summer Dress”, “description”:”Our best-selling…”, “Price”: 118, “color”:”blue”, “fabric”:”cotton”, “desc_embedding”:[0.452,0.3242,…], “img_embedding”:[0.012,0.0,…]
Slide 24
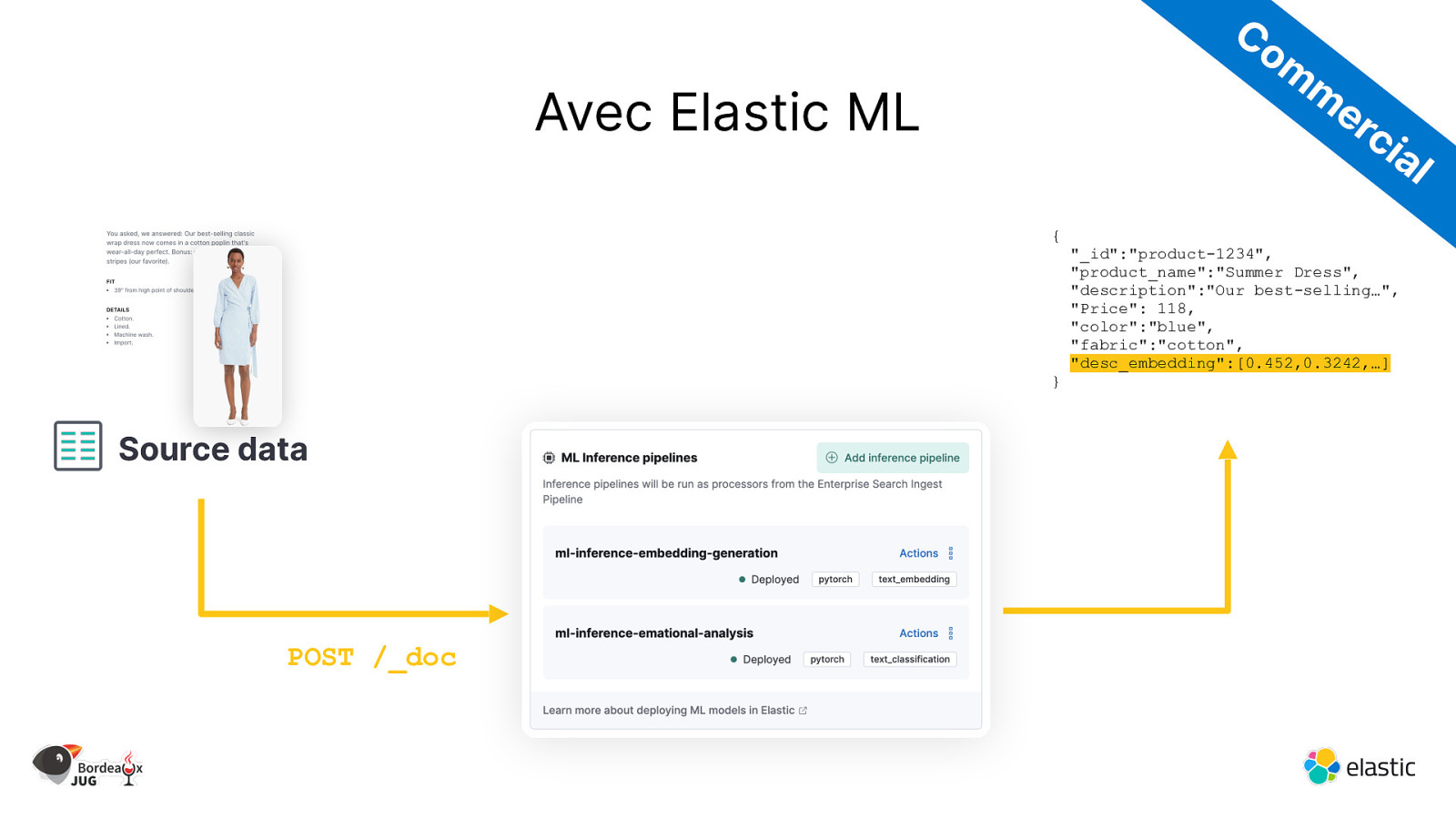
Co m m er ci Avec Elastic ML al { } Source data POST /_doc “_id”:”product-1234”, “product_name”:”Summer Dress”, “description”:”Our best-selling…”, “Price”: 118, “color”:”blue”, “fabric”:”cotton”, “desc_embedding”:[0.452,0.3242,…]
Slide 25
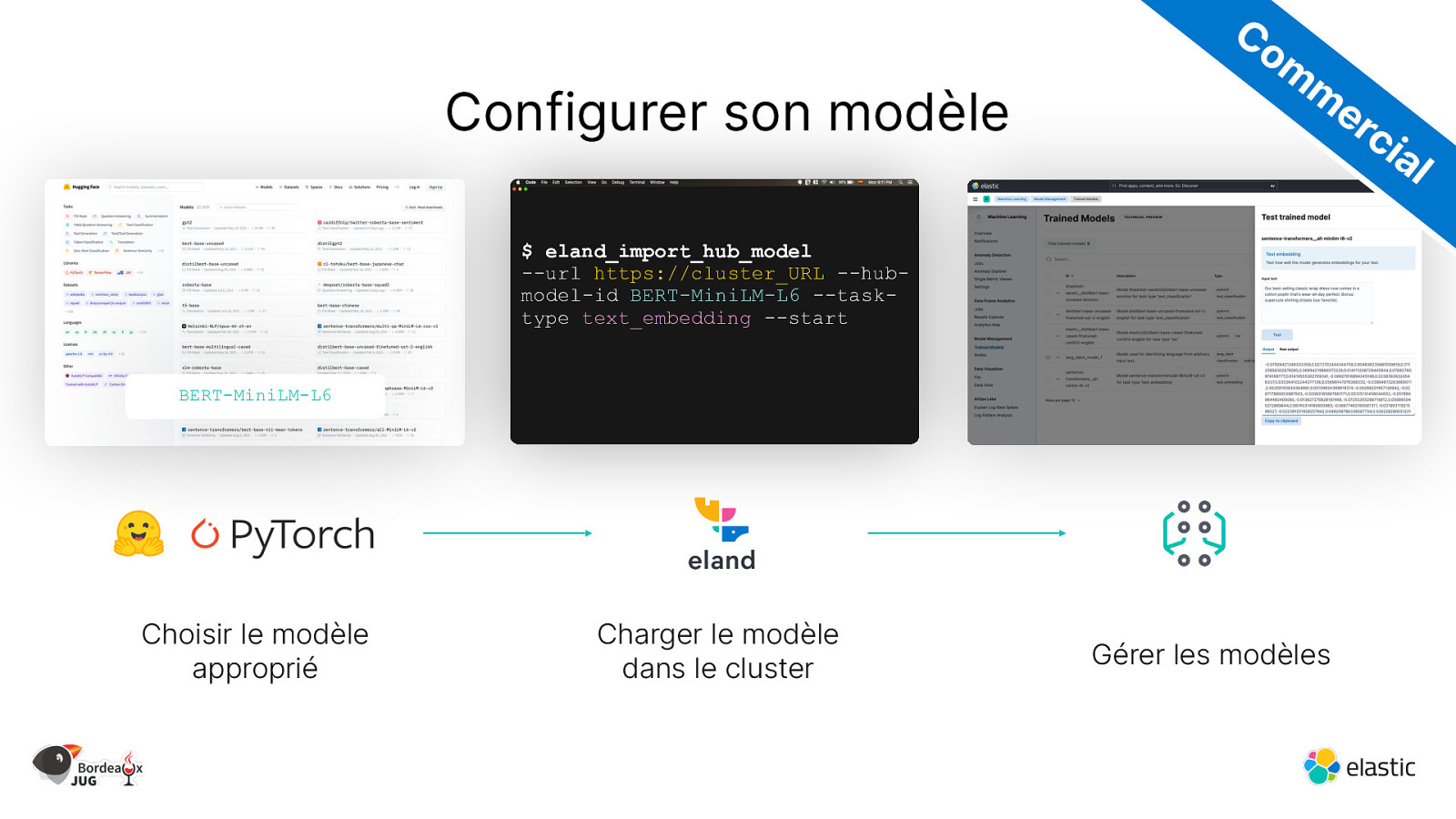
Configurer son modèle Co m m er ci al $ eland_import_hub_model —url https://cluster_URL —hubmodel-id BERT-MiniLM-L6 —tasktype text_embedding —start BERT-MiniLM-L6 Choisir le modèle approprié Charger le modèle dans le cluster Gérer les modèles
Slide 26

Gestion des modèles ● C’est un domaine qui évolue rapidement. La flexibilité vous permet de vous adapter facilement. ● Utilisation des modèles tiers PyTorch ● Support de plusieurs types de modèles NLP Co m m er ci al Liste complète des modèles supportés par Elastic : ela.st/nlp-supported-models
Slide 27

Comment chercher avec des vecteurs ?
Slide 28
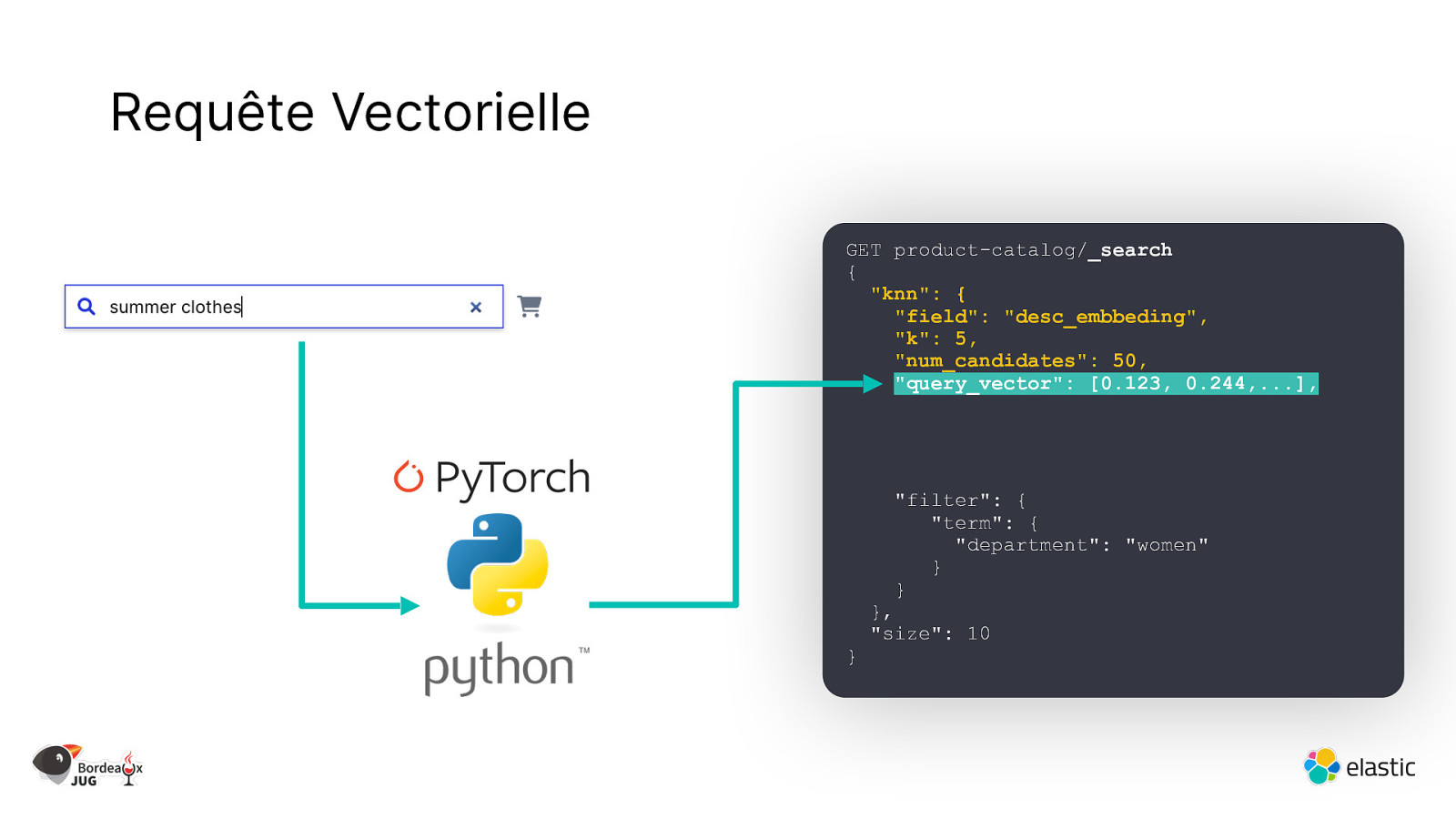
Requête Vectorielle GET product-catalog/_search { “knn”: { “field”: “desc_embbeding”, “k”: 5, “num_candidates”: 50, “query_vector”: [0.123, 0.244,…], “filter”: { “term”: { “department”: “women” } } } }, “size”: 10
Slide 29
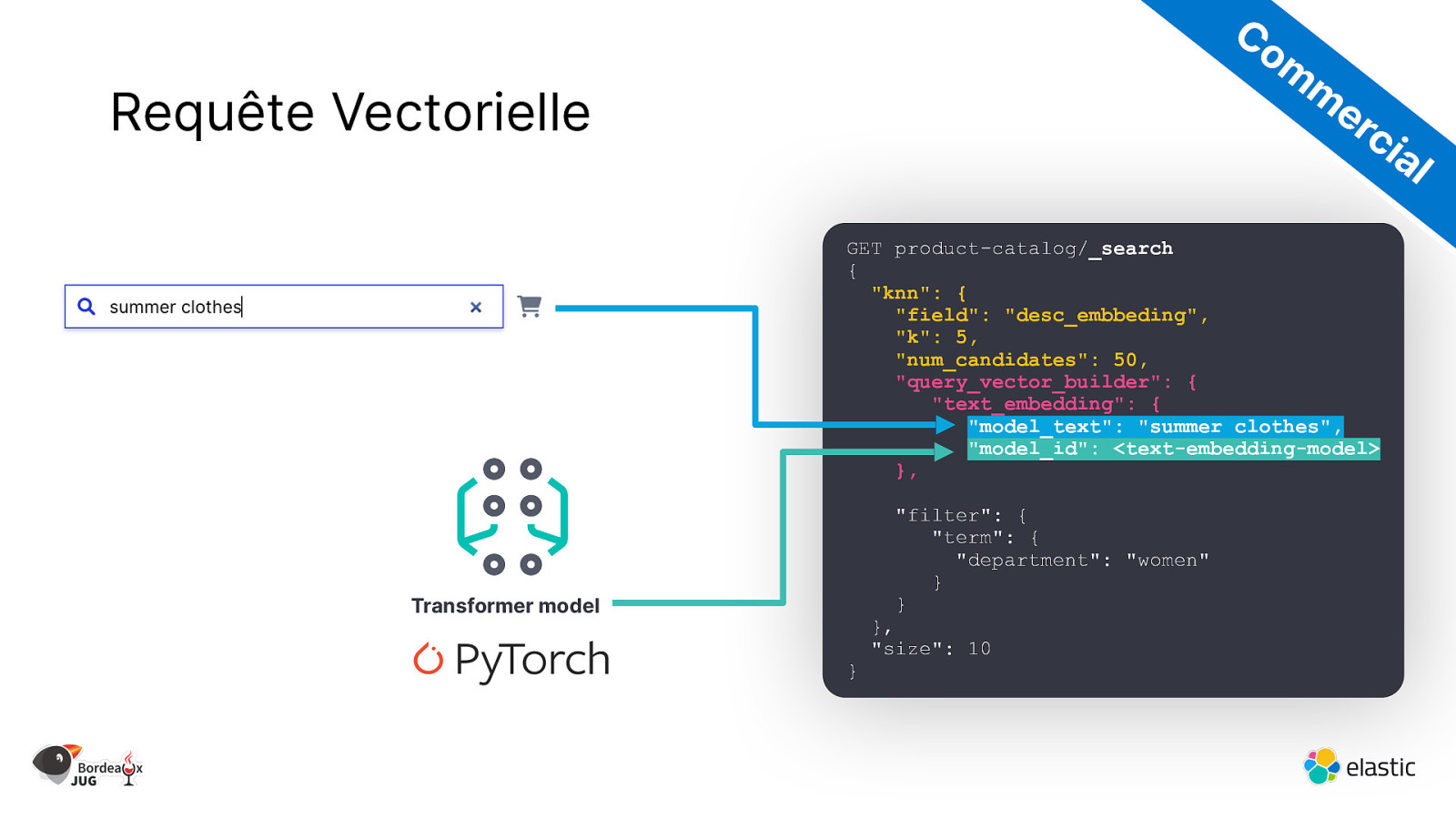
Co m m er ci Requête Vectorielle al GET product-catalog/_search { “knn”: { “field”: “desc_embbeding”, “k”: 5, “num_candidates”: 50, “query_vector_builder”: { “text_embedding”: { “model_text”: “summer clothes”, “model_id”: <text-embedding-model> }, “filter”: { “term”: { “department”: “women” } } Transformer model } }, “size”: 10
Slide 30
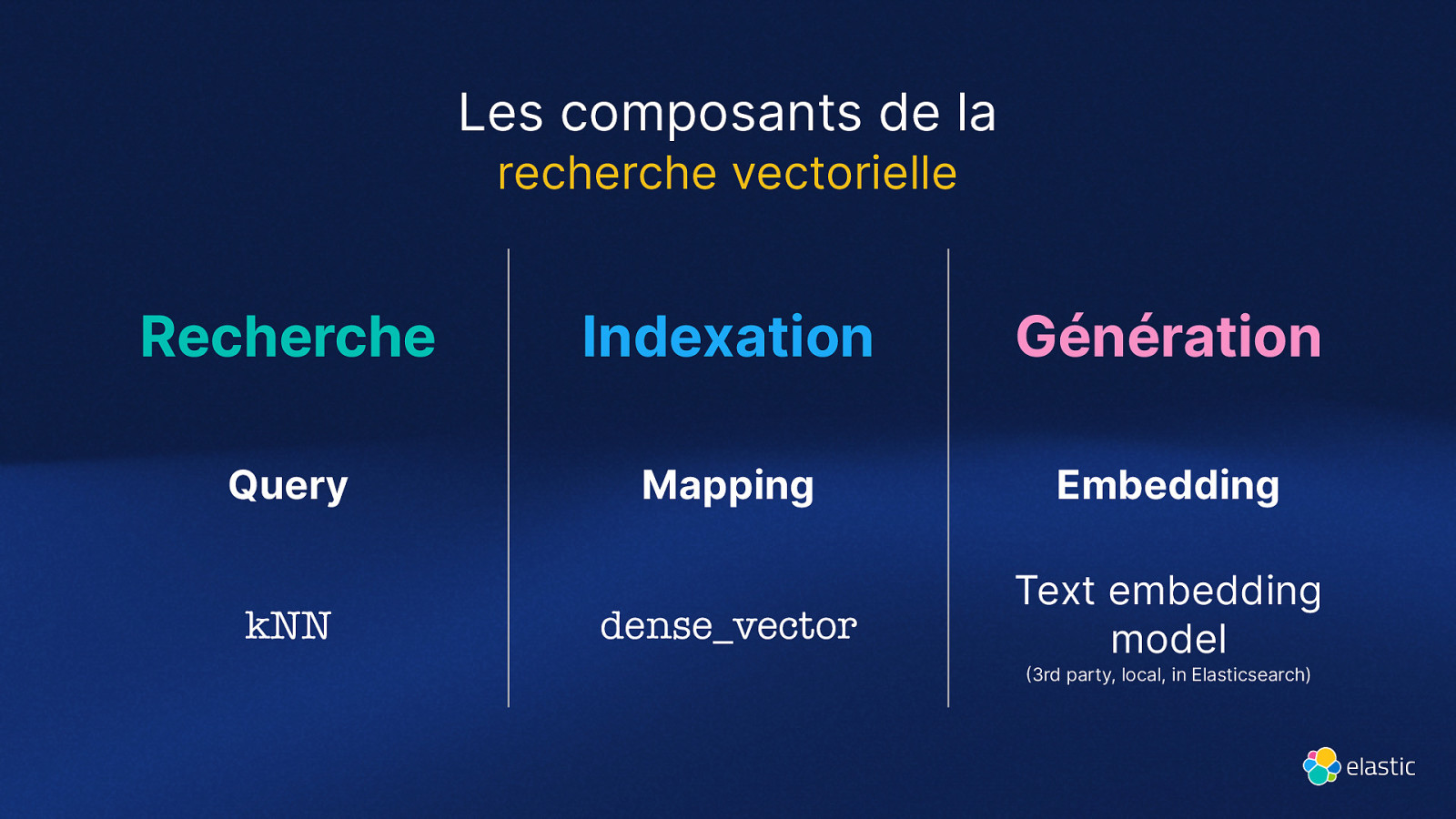
Les composants de la recherche vectorielle Recherche Indexation Génération Query Mapping Embedding dense_vector Text embedding model kNN (3rd party, local, in Elasticsearch)
Slide 31

Mais comment ça fonctionne en vrai ?
Slide 32
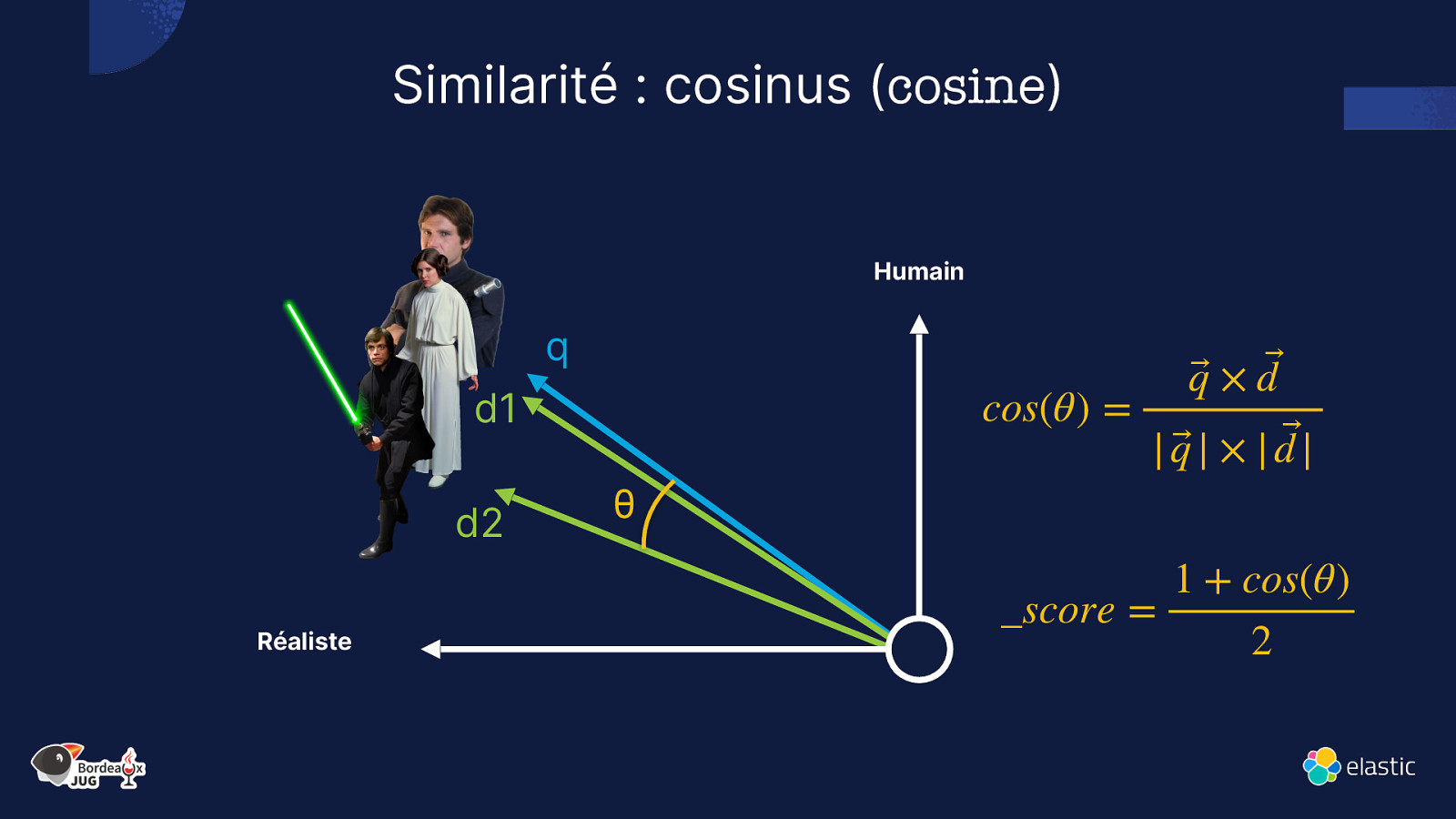
Similarité : cosinus (cosine) Humain q cos(θ) = d1 d2 Réaliste θ q⃗ × d ⃗ | q⃗ | × | d |⃗ _score = 1 + cos(θ) 2
Slide 33
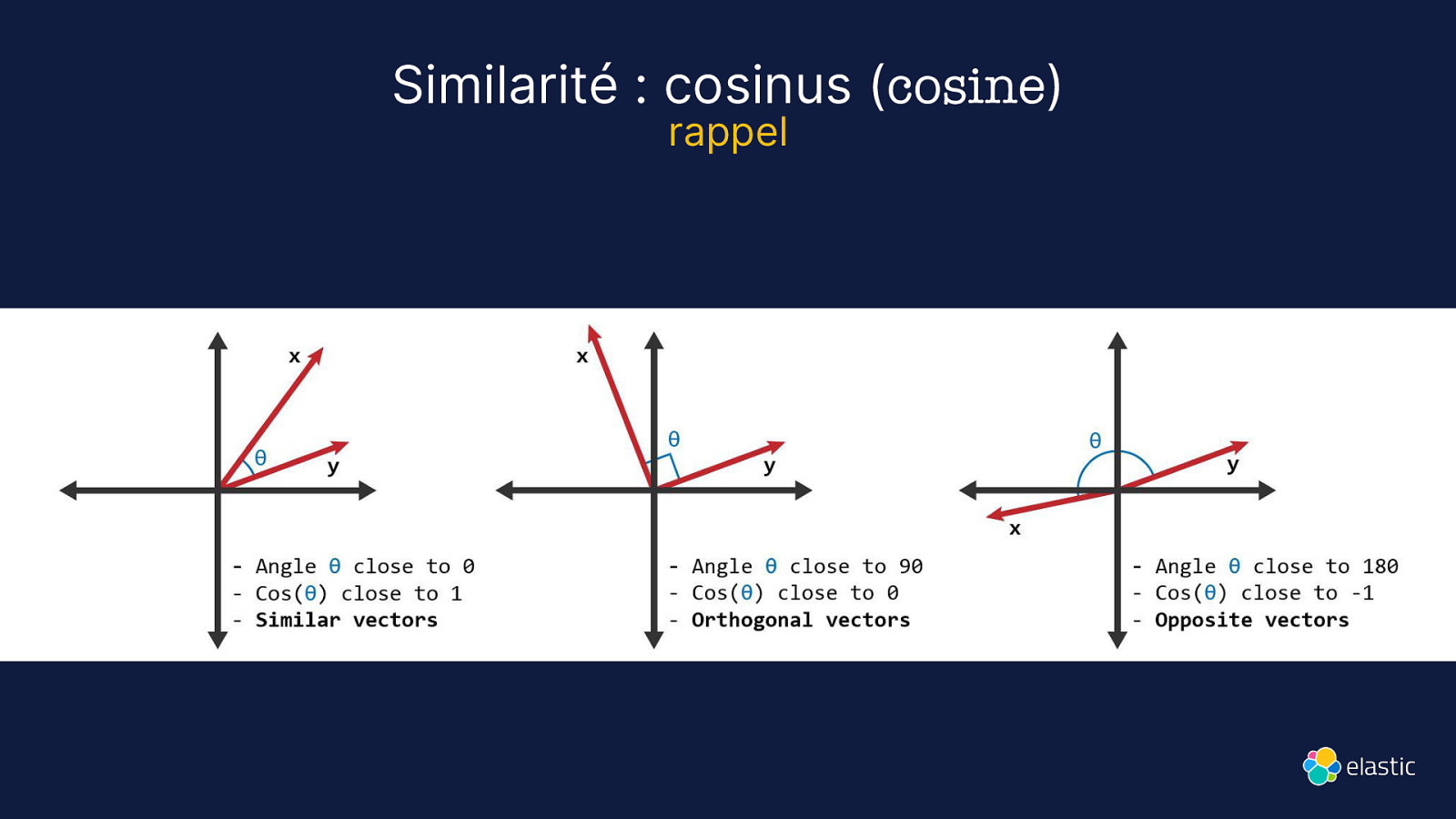
Similarité : cosinus (cosine) rappel
Slide 34
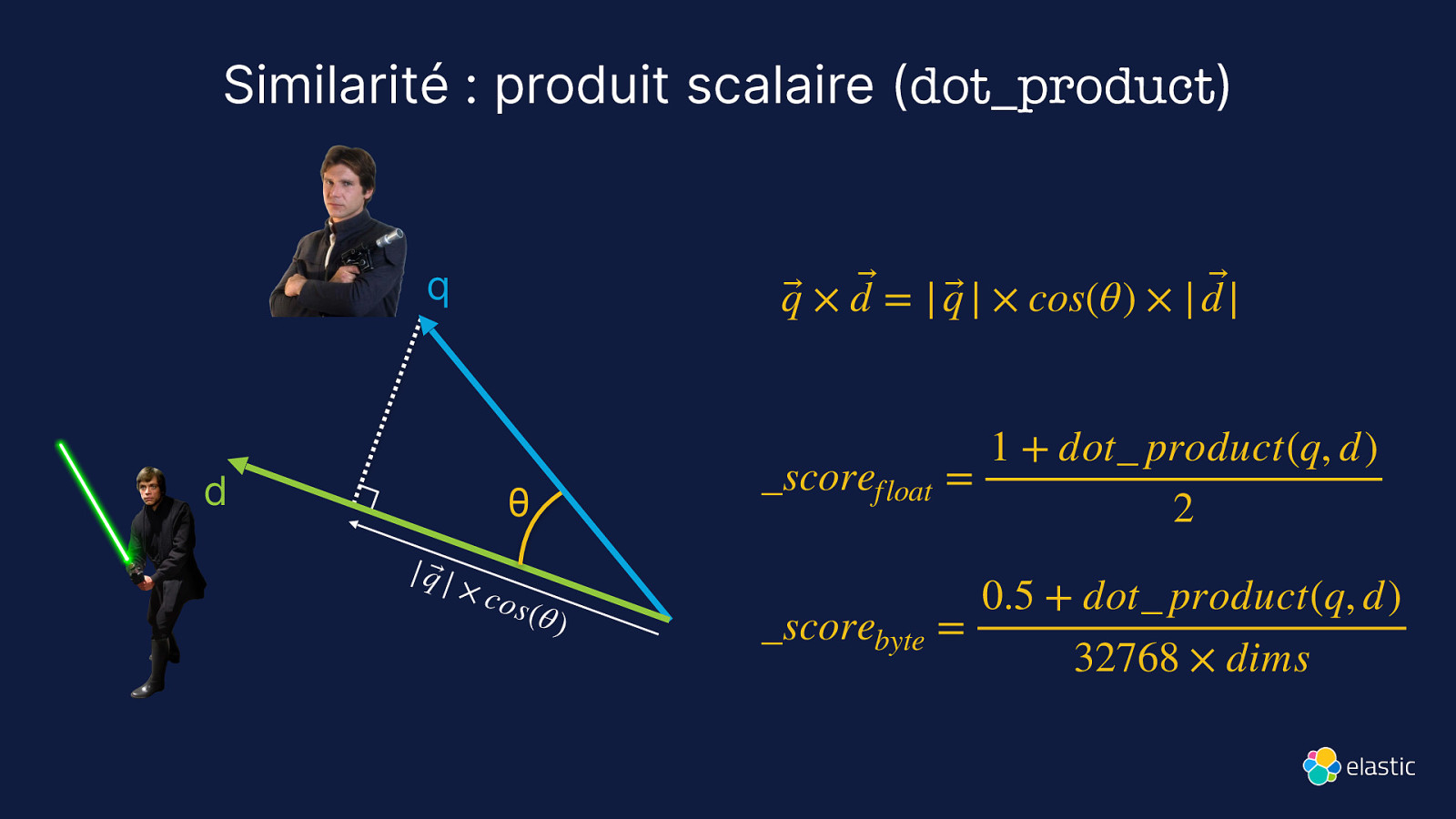
Similarité : produit scalaire (dot_product) q d q⃗ × d ⃗ = | q⃗ | × cos(θ) × | d |⃗ θ | q⃗ | × co s (θ ) 1 + dot_ product(q, d) scorefloat = 2 0.5 + dot product(q, d) _scorebyte = 32768 × dims
Slide 35
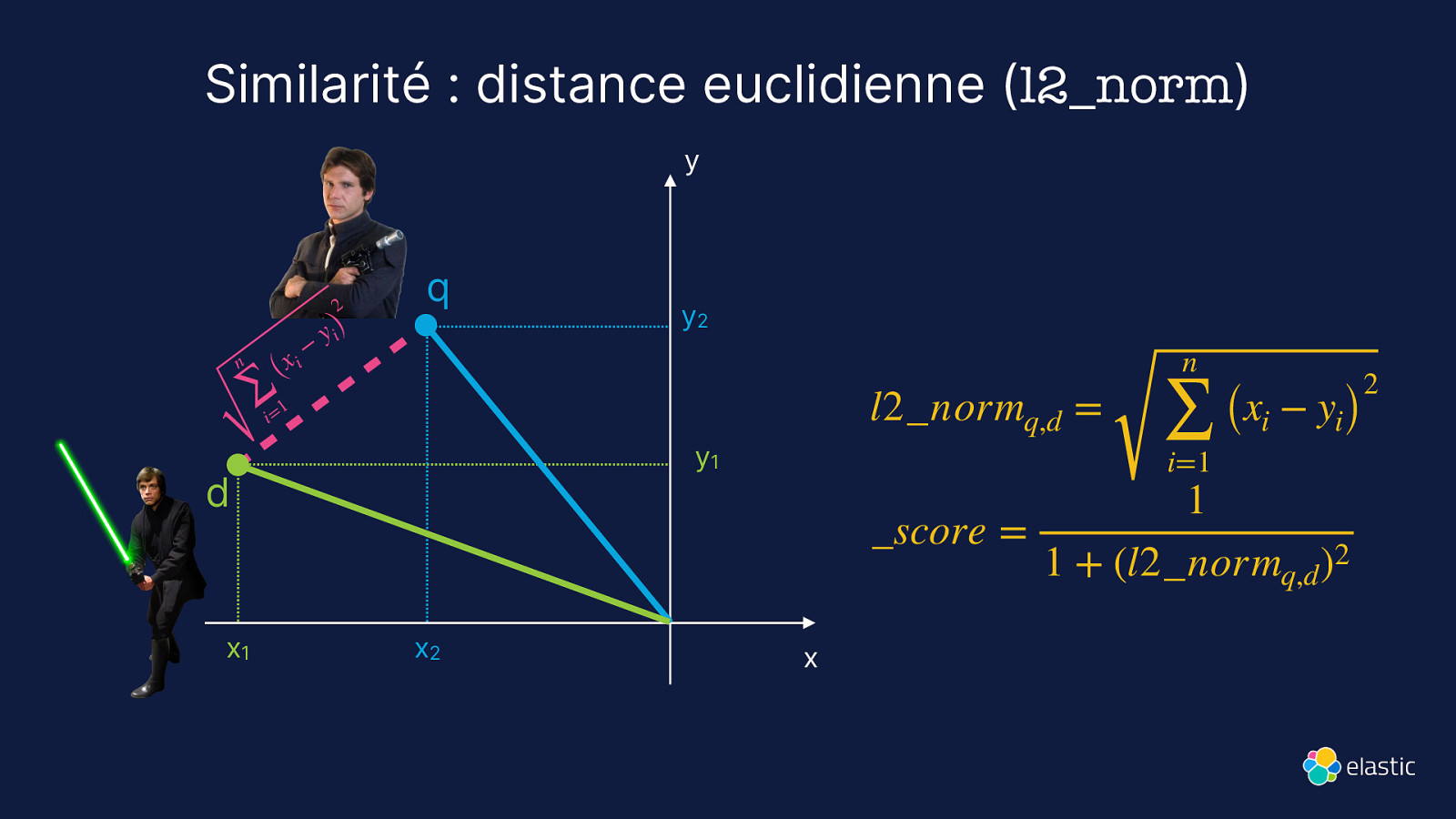
Similarité : distance euclidienne (l2_norm) y 2 n i (x ∑ 1 i= − y i) q l2_normq,d = y1 d x1 y2 x2 n ∑ i=1 (xi − yi) 1 _score = 1 + (l2_normq,d )2 x 2
Slide 36

Brute Force
Slide 37

Hierarchical Navigable Small Worlds (HNSW) HNSW: a layered approach that simplifies access to the nearest neighbor Tiered: from coarse to fine approximation over a few steps Balance: Bartering a little accuracy for a lot of scalability Speed: Excellent query latency on large scale indices
Slide 38

brute force ou HNSW ? Brute force (not real numbers; used only to demonstrate the linearity) HNSW Au pire : 2*(brute force) • Brute force : O(n) des documents filtrés • HNSW : ~O(log(n)) de tous les documents
Slide 39
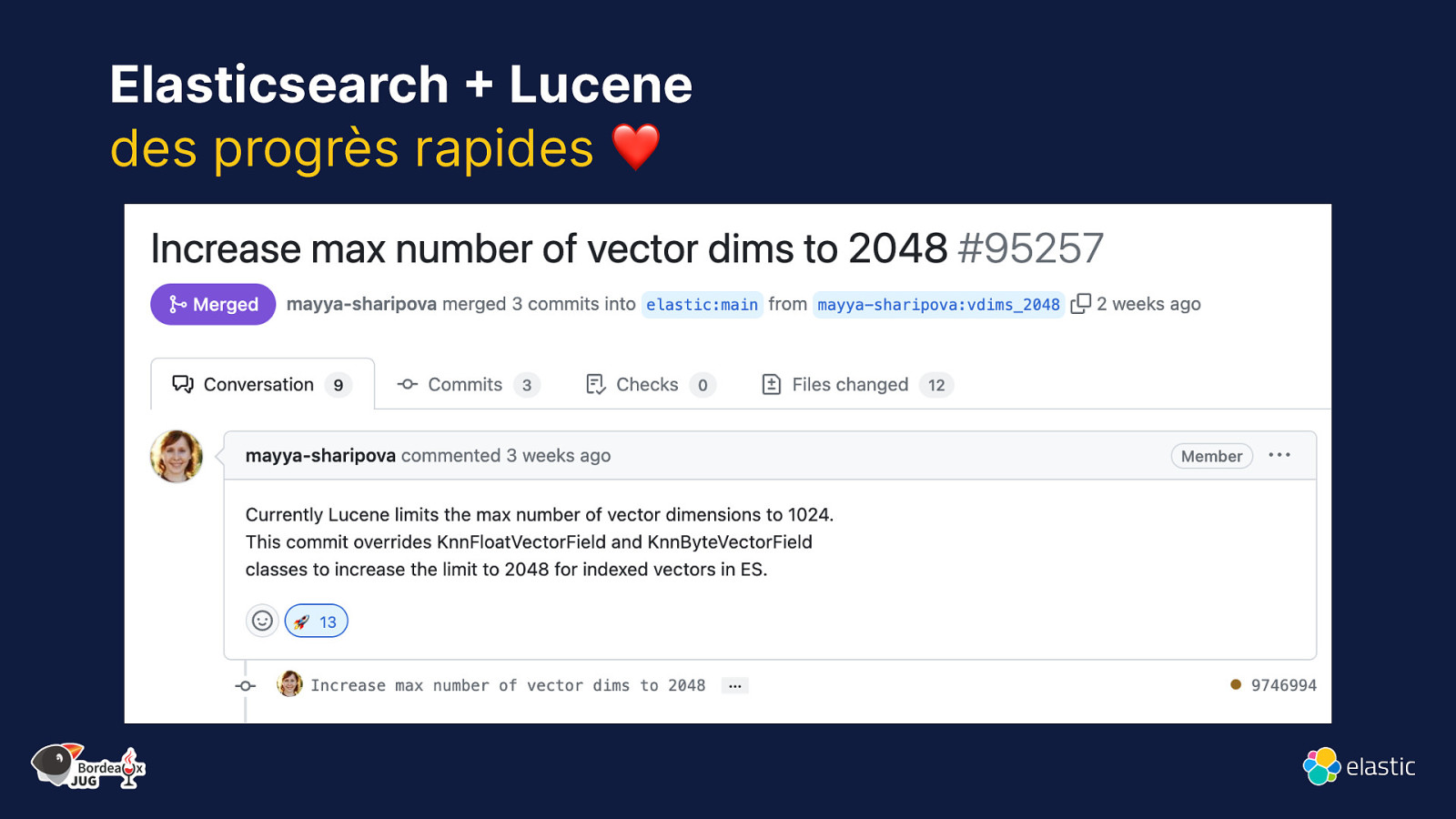
Elasticsearch + Lucene des progrès rapides ❤
Slide 40

“Scaler” la recherche vectorielle Recherche vectorielle Bonnes pratiques
- Besoin énorme de mémoire
- Eviter les recherches pendant l’indexation
- Indexation plus lente
- Exclure les vecteurs du champ _source
- Merge est plus lent
- Réduire le nombre de dimensions des vecteurs 4. Utiliser des bytes plutôt que des float
- Améliorations permanentes dans Lucene et Elasticsearch
Slide 41
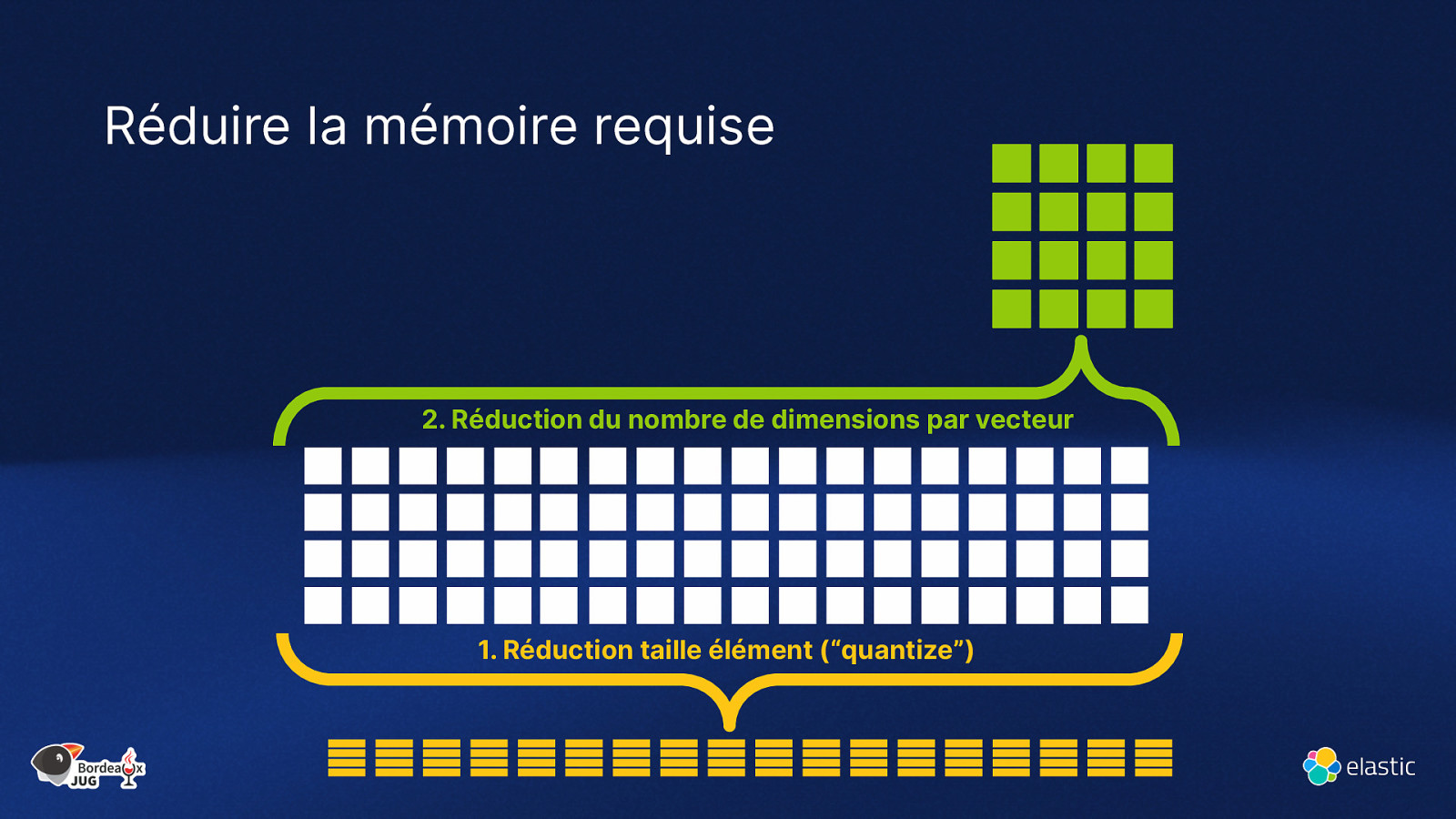
Réduire la mémoire requise 2. Réduction du nombre de dimensions par vecteur
- Réduction taille élément (“quantize”)
Slide 42

Base de données vectorielles ● Stockage efficace de vecteurs numériques, support des opérations CRUD ● Recherche rapide de vecteurs ● Conçu pour de la recherche vectorielle à grande échelle (scalable)
Slide 43

Elasticsearch bien plus qu’une base de données vectorielles Elasticsearch est capable de : ● Créer des vector embeddings (représentations numériques des données) ● Est optimisé pour stocker des vecteurs éparpillés et denses, en volume Elasticsearch a aussi : ● Filtres et agrégations : sur l’ensemble des résultats ● Sécurité native au niveau document* : utilisé en production par les clients enterprise ● Types de données : Geo, full text, support des langues ● Outils d’ingestion : connecteurs, API, crawler web et des intégrations tierces ● Communité, adoption massive par les enterprises, Track record, Elastic stack… * nécessite une license commerciale
Slide 44

Benchmarketing
Slide 45

Elasticsearch You Know, for Hybrid Search
Slide 46
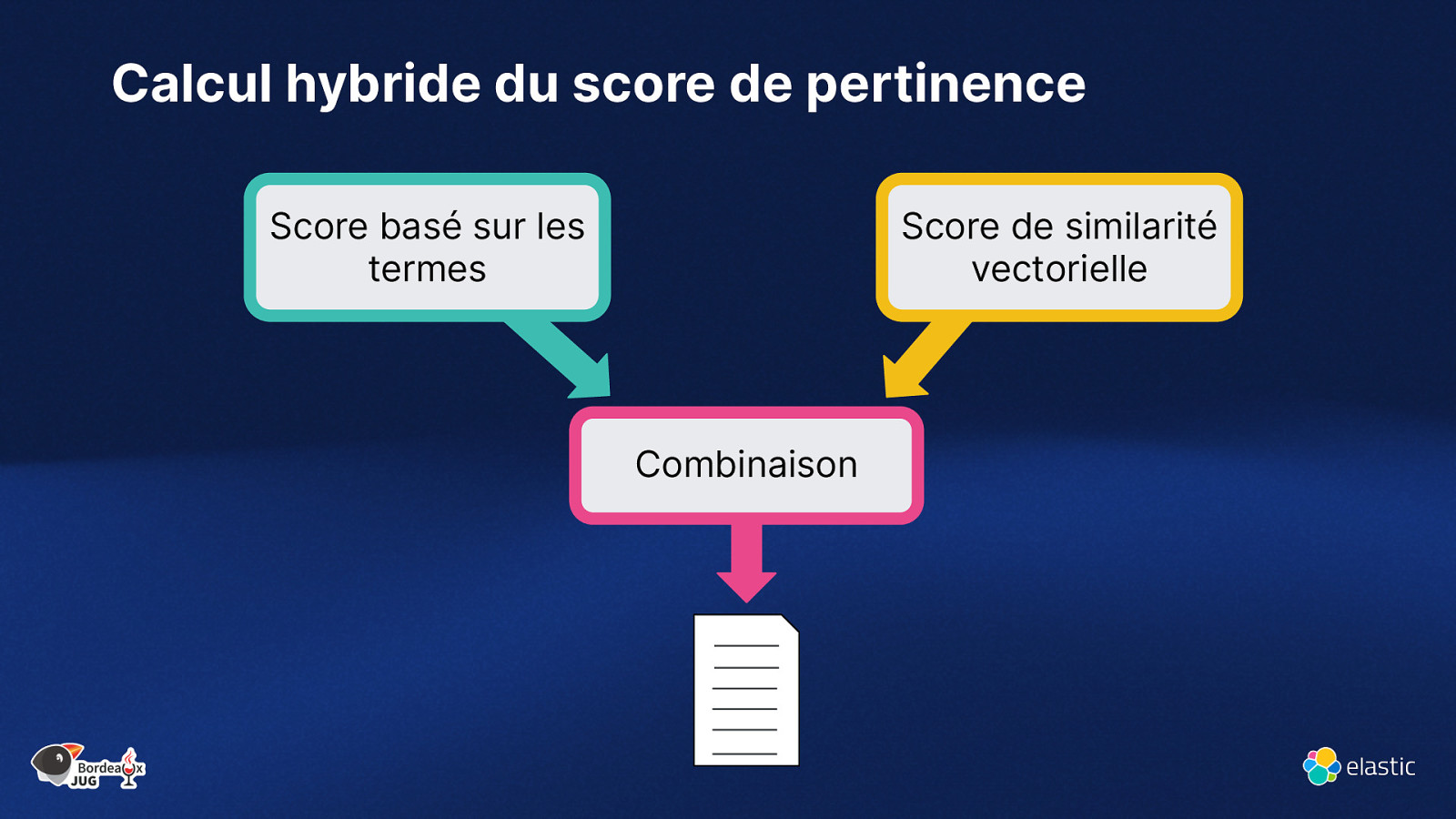
Calcul hybride du score de pertinence Score basé sur les termes Score de similarité vectorielle Combinaison
Slide 47
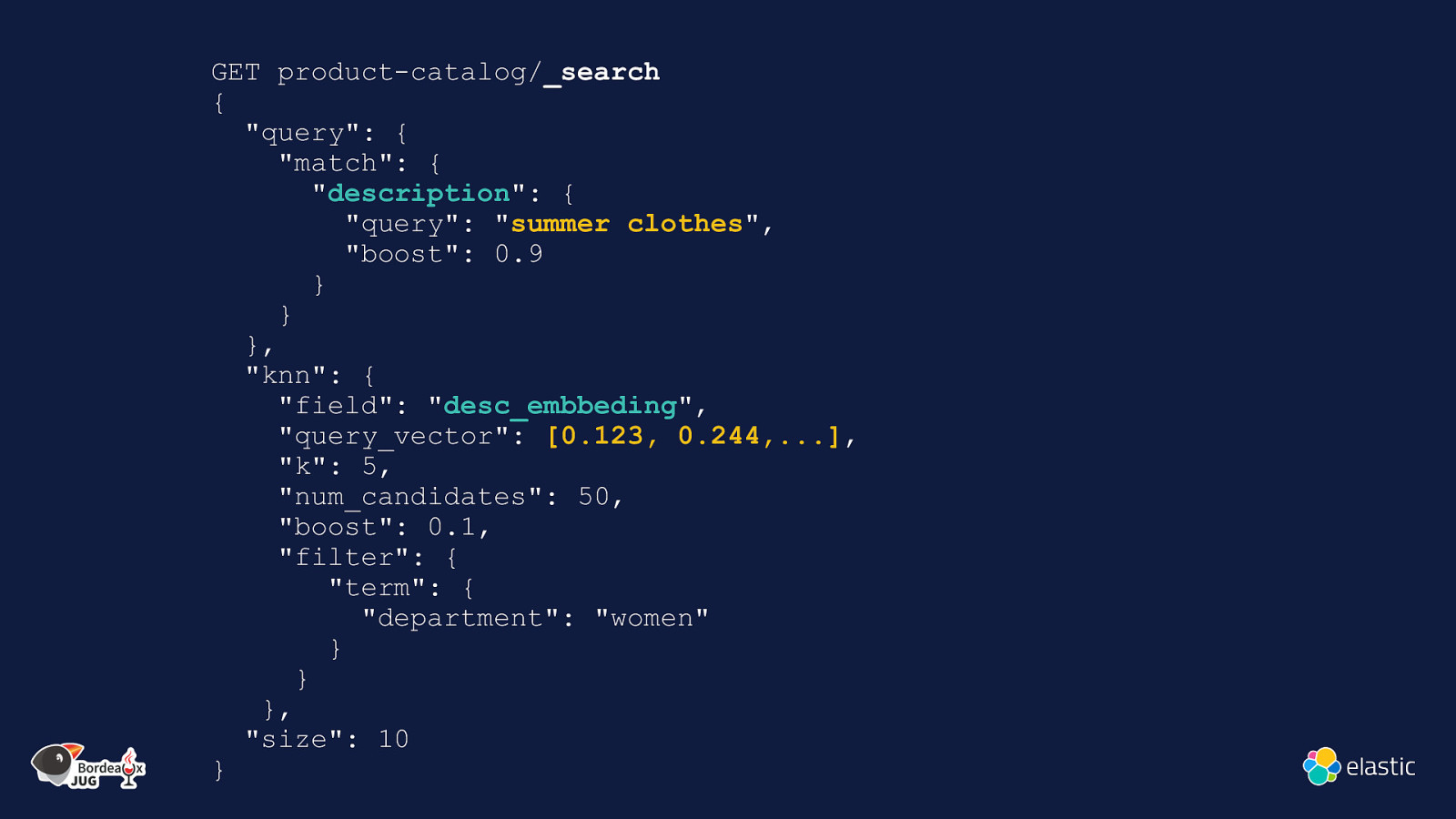
GET product-catalog/_search { “query”: { “match”: { “description”: { “query”: “summer clothes”, “boost”: 0.9 } } }, “knn”: { “field”: “desc_embbeding”, “query_vector”: [0.123, 0.244,…], “k”: 5, “num_candidates”: 50, “boost”: 0.1, “filter”: { “term”: { “department”: “women” } } }, “size”: 10 }
Slide 48
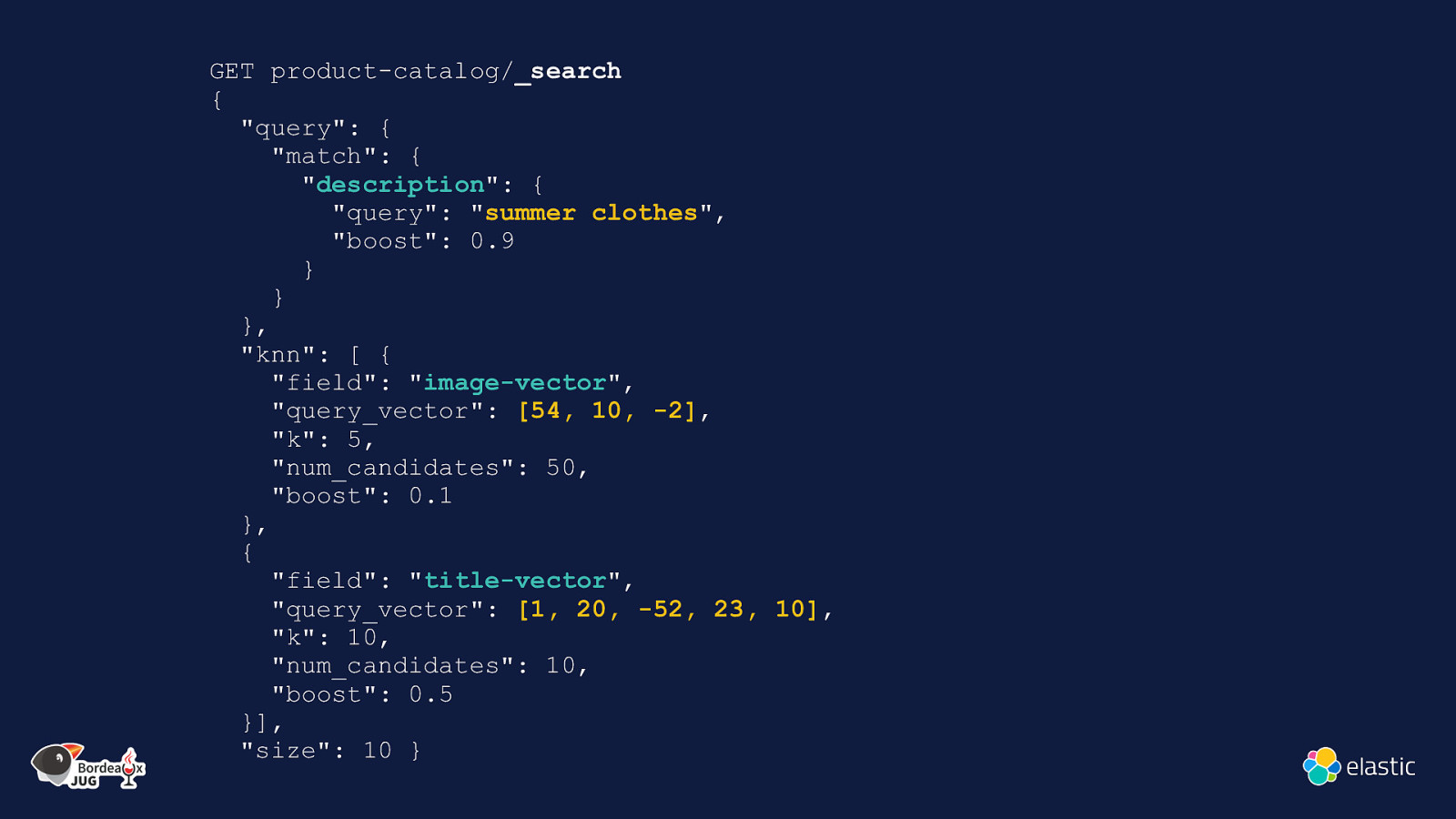
GET product-catalog/_search { “query”: { “match”: { “description”: { “query”: “summer clothes”, “boost”: 0.9 } } }, “knn”: [ { “field”: “image-vector”, “query_vector”: [54, 10, -2], “k”: 5, “num_candidates”: 50, “boost”: 0.1 }, { “field”: “title-vector”, “query_vector”: [1, 20, -52, 23, 10], “k”: 10, “num_candidates”: 10, “boost”: 0.5 }], “size”: 10 }
Slide 49

ELSER Elastic Learned Sparse EncodER text_expansion Not BM25 or (dense) vector Sparse vector like BM25 Stored as inverted index Co m m er ci al
Slide 50

Co m m er ci ELSER - pertinence sur étagère, multi domaines al ● Permet d’implémenter la recherche sémantique sans avoir à entraîner votre propre modèle ● Généraliste : plein de domaines sans entraînement ● Excellente pertinence, sur étagère Démo
Slide 51
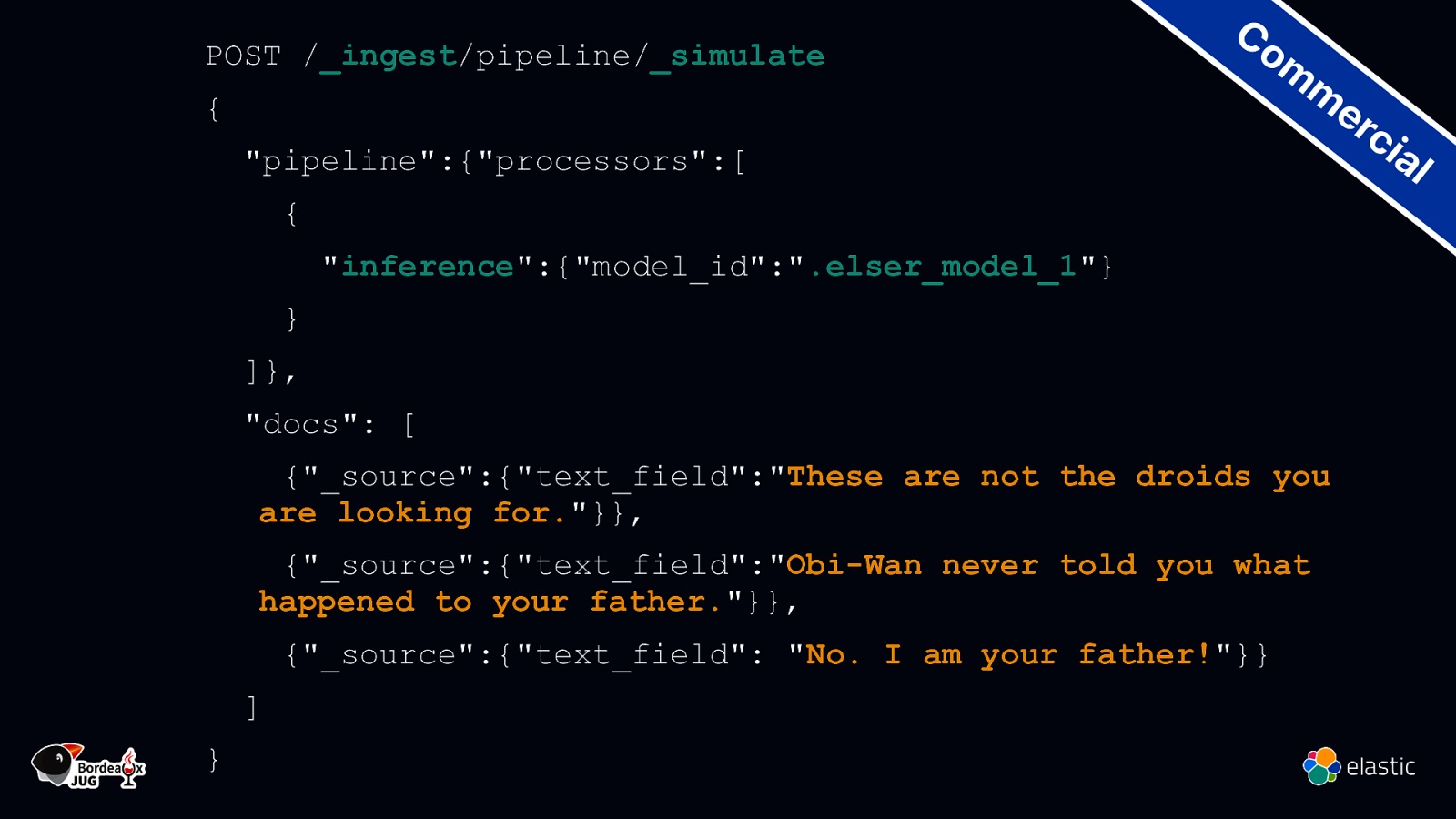
POST /_ingest/pipeline/_simulate { “pipeline”:{“processors”:[ Co m m er ci { “inference”:{“model_id”:”.elser_model_1”} } ]}, “docs”: [ {“_source”:{“text_field”:”These are not the droids you are looking for.”}}, {“_source”:{“text_field”:”Obi-Wan never told you what happened to your father.”}}, {“_source”:{“text_field”: “No. I am your father!”}} ] } al
Slide 52

Co m m er ci al These are not the droids you are looking for. “ml”: { “inference”: { “predicted_value”: { “lucas”: 0.50047517, “ship”: 0.29860738, “dragon”: 0.5300422, “quest”: 0.5974301, “dr”: 2.1055143, “space”: 0.49377063, “robot”: 0.40398192, …
Slide 53
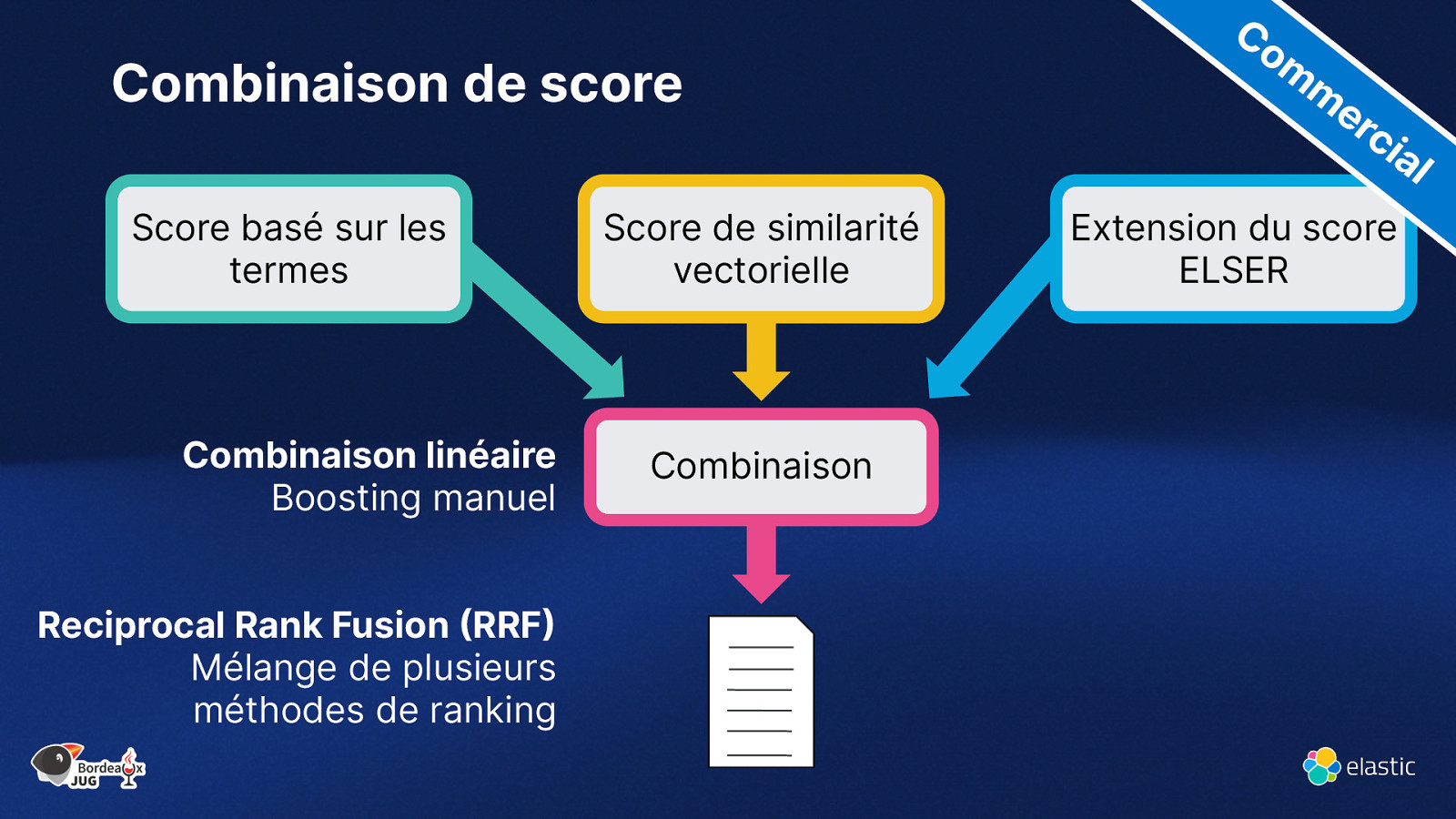
Combinaison de score Co m m er ci al Score basé sur les termes Combinaison linéaire Boosting manuel Reciprocal Rank Fusion (RRF) Mélange de plusieurs méthodes de ranking Score de similarité vectorielle Combinaison Extension du score ELSER
Slide 54

Reciprocal Rank Fusion (RRF) D - set of docs R - set of rankings as permutation on 1..|D| k - typically set to 60 by default Ranking Algorithm 1 Doc Ranking Algorithm 2 Score r(d) k+r(d) A 1 1 B 0.7 C D E Doc Score r(d) k+r(d) 61 C 1,341 1 61 2 62 A 739 2 62 0.5 3 63 F 732 3 63 0.2 4 64 G 192 4 64 0.01 5 65 H 183 5 65 Doc RRF Score A 1/61 + 1/62 = 0,0325 C 1/63 + 1/61 = 0,0323 B 1/62 = 0,0161 F 1/63 = 0,0159 D 1/64 = 0,0156
Slide 55
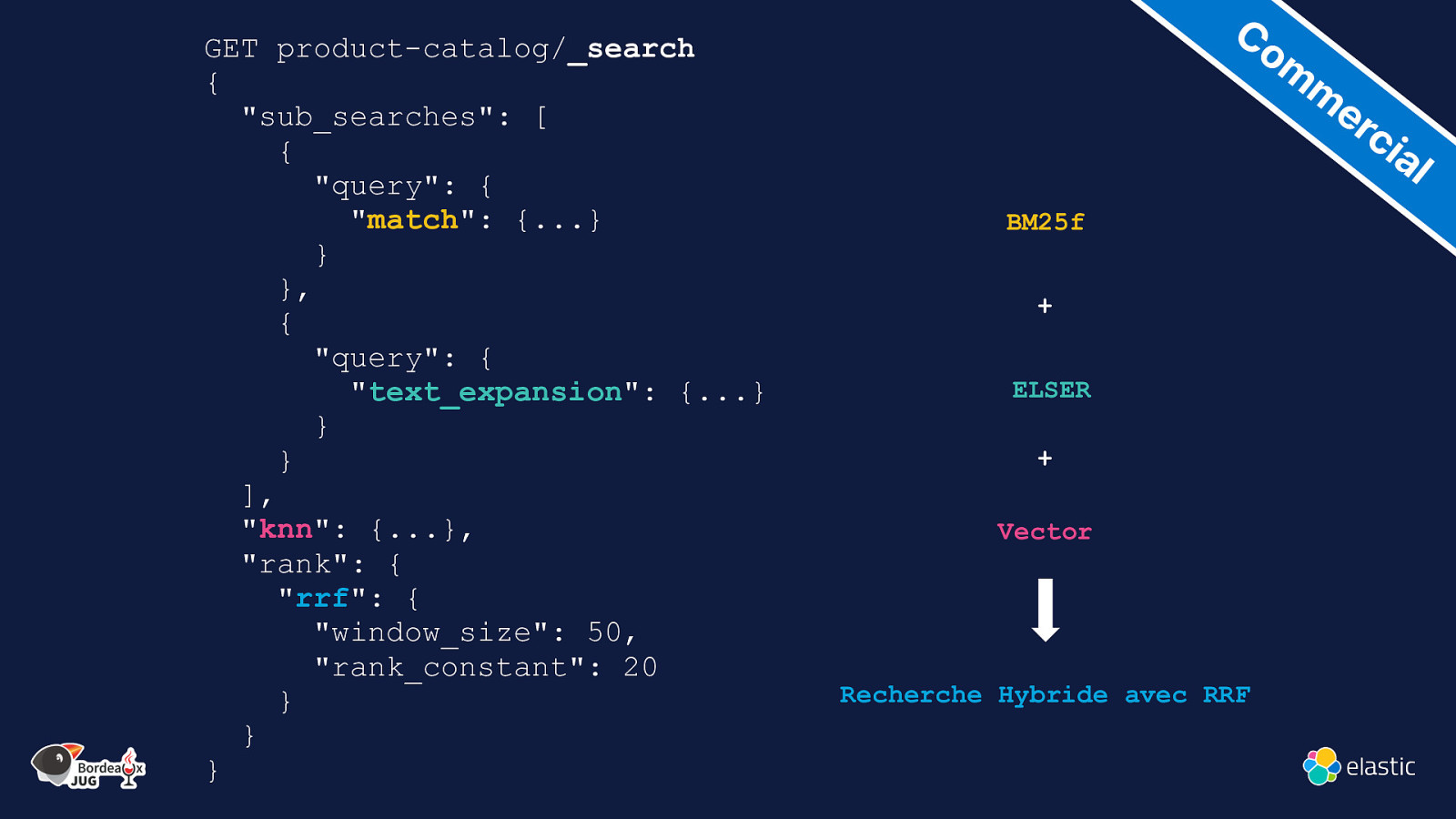
GET product-catalog/_search { “sub_searches”: [ { “query”: { “match”: {…} } }, { “query”: { “text_expansion”: {…} } } ], “knn”: {…}, “rank”: { “rrf”: { “window_size”: 50, “rank_constant”: 20 } } } Co m m er ci al BM25f + ELSER + Vector Recherche Hybride avec RRF
Slide 56

Gratuit vs Payant (platinum) kNN with HNSW
- Fournissez vos propres embeddings 2. Attention à la mémoire requise pour faire tenir les vecteurs en RAM (off-heap) Inference in Elasticsearch 1. Génération des embeddings (transformers HuggingFace, autres) 2. ELSER
Slide 57
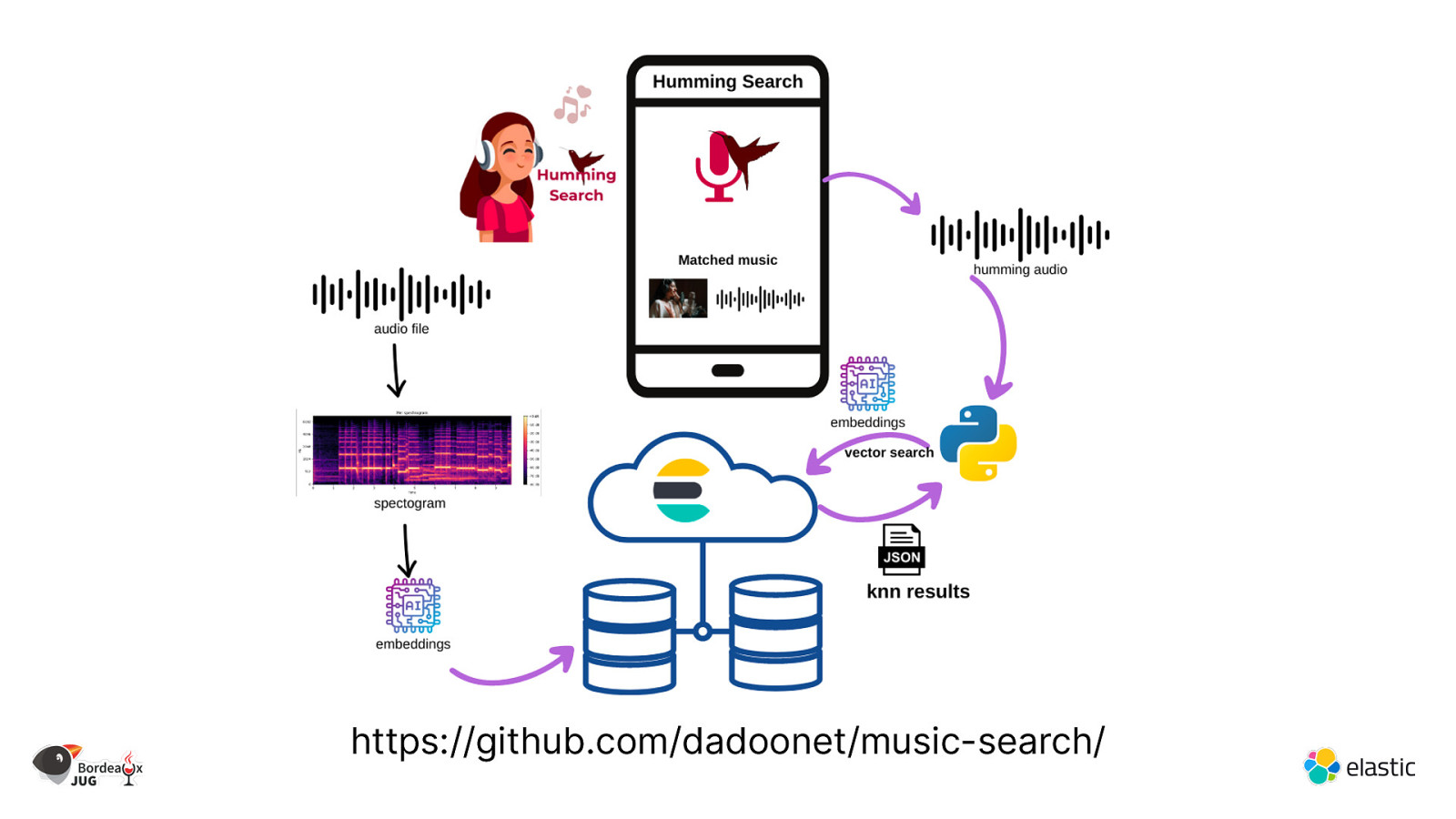
https://github.com/dadoonet/music-search/
Slide 58

ChatGPT Elastic et les LLMs
Slide 59
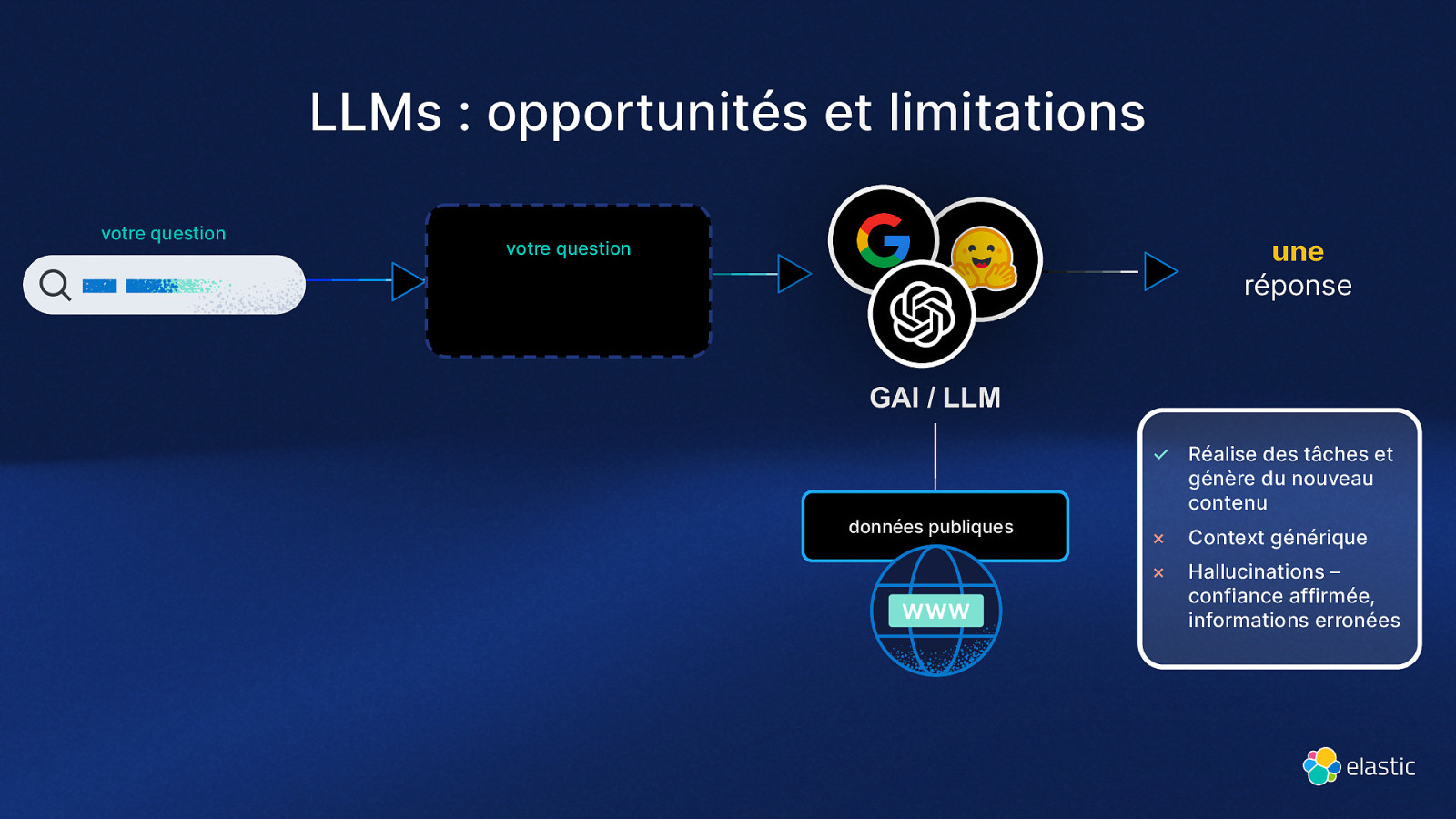
LLMs : opportunités et limitations votre question une réponse votre question GAI / LLM données publiques ✓ Réalise des tâches et génère du nouveau contenu × Context générique × Hallucinations – confiance affirmée, informations erronées
Slide 60
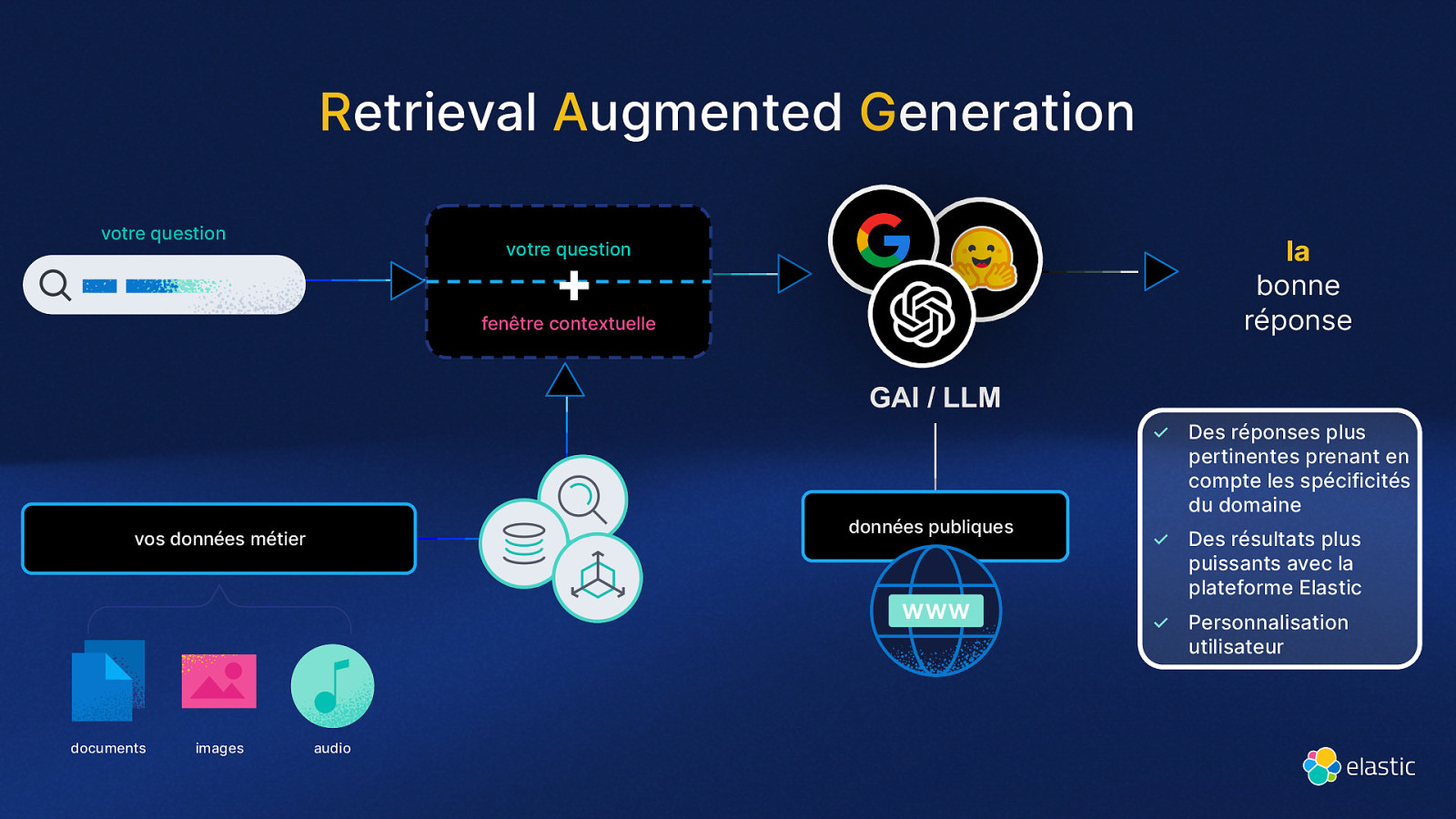
Retrieval Augmented Generation votre question la bonne réponse votre question + fenêtre contextuelle GAI / LLM données publiques vos données métier ✓ Des réponses plus pertinentes prenant en compte les spécificités du domaine ✓ Des résultats plus puissants avec la plateforme Elastic ✓ Personnalisation utilisateur documents images audio
Slide 61

Démo
Slide 62

Conclusion
Slide 63
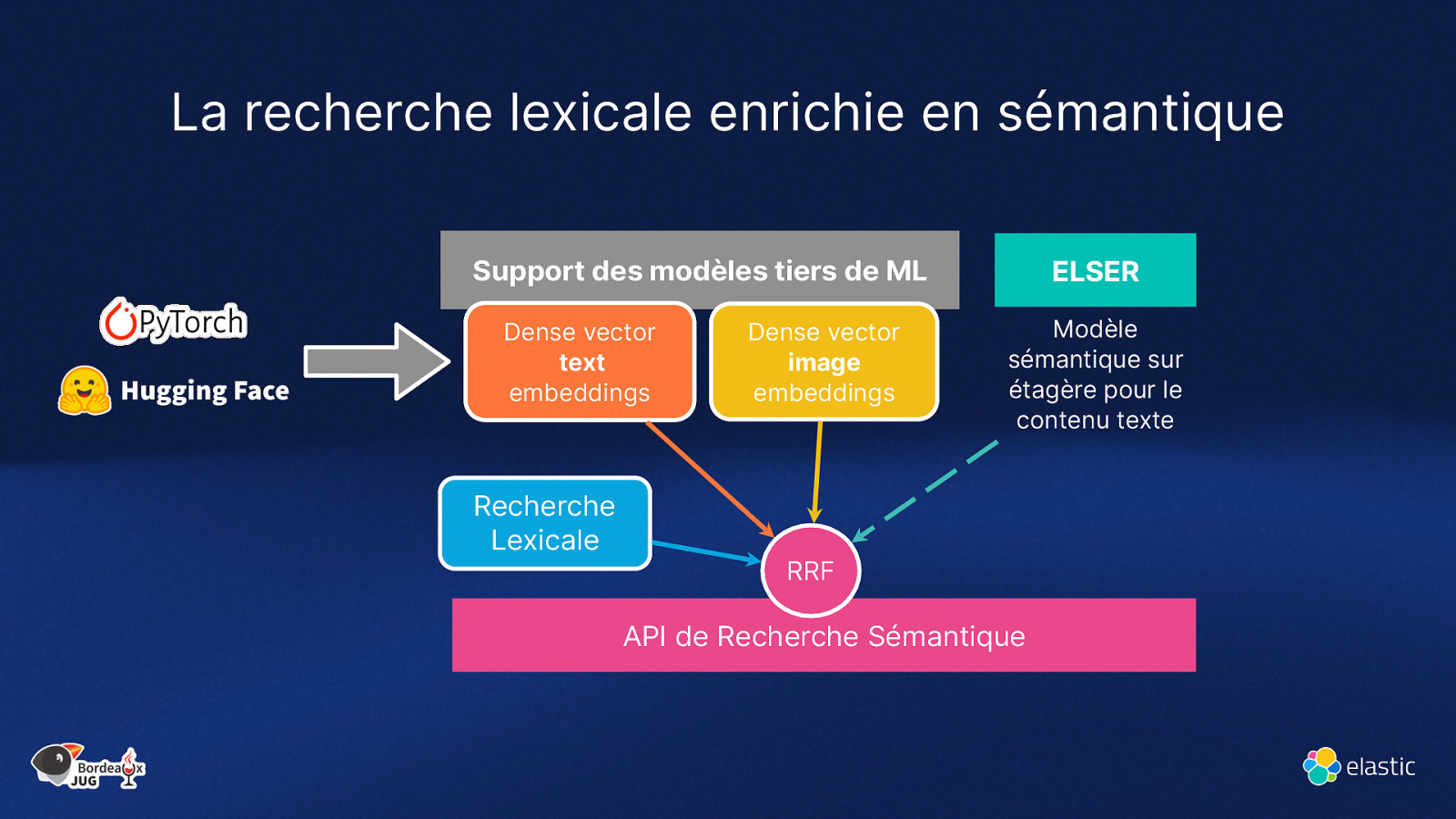
La recherche lexicale enrichie en sémantique Support des modèles tiers de ML Dense vector text embeddings Recherche Lexicale Dense vector image embeddings ELSER Modèle sémantique sur étagère pour le contenu texte RRF API de Recherche Sémantique
Slide 64

Données corporate: texte, images, docs Les ingrédients nécessaires pour la recherche IA… Recherche textuelle, vectorielle Capacités en langage naturel Usage des LLMs et de modèles ML publiques / propriétaires
Slide 65

… sont les fonctionnalités que nous livrons en standard Ingestion, Sécurité niveau document pour les données corporate Recherche Hybride (BM25, Vecteur..) Recherche Vectorielle permettant l’usage du langage naturel Flexibilité des Modèles pour rester à jour : nouveaux modèles tiers et LLM
Slide 66

La recherche à l’ère de l’IA David Pilato | @dadoonet