Search & AI a new era David Pilato | @dadoonet
Slide 1

Slide 2

Agenda ● ● ● ● “Classic” search and its limitations ML model and usage Vector search or hybrid search in Elasticsearch OpenAI’s ChatGPT or LLMs with Elasticsearch
Slide 3

Elasticsearch You Know, for Search
Slide 4

Slide 5

Slide 6

These are not the droids you are looking for.
Slide 7
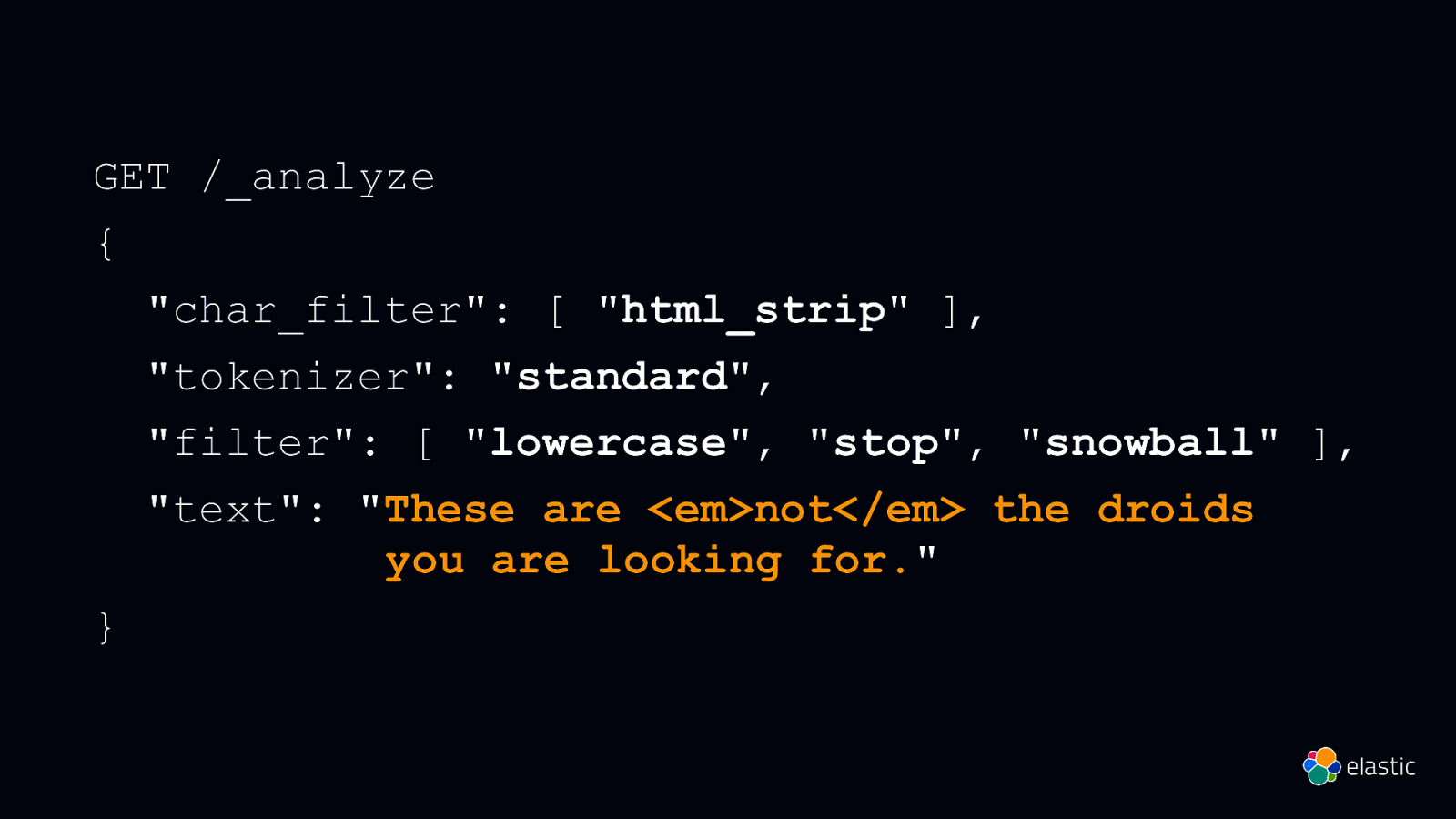
GET /_analyze { “char_filter”: [ “html_strip” ], “tokenizer”: “standard”, “filter”: [ “lowercase”, “stop”, “snowball” ], “text”: “These are <em>not</em> the droids you are looking for.” }
Slide 8
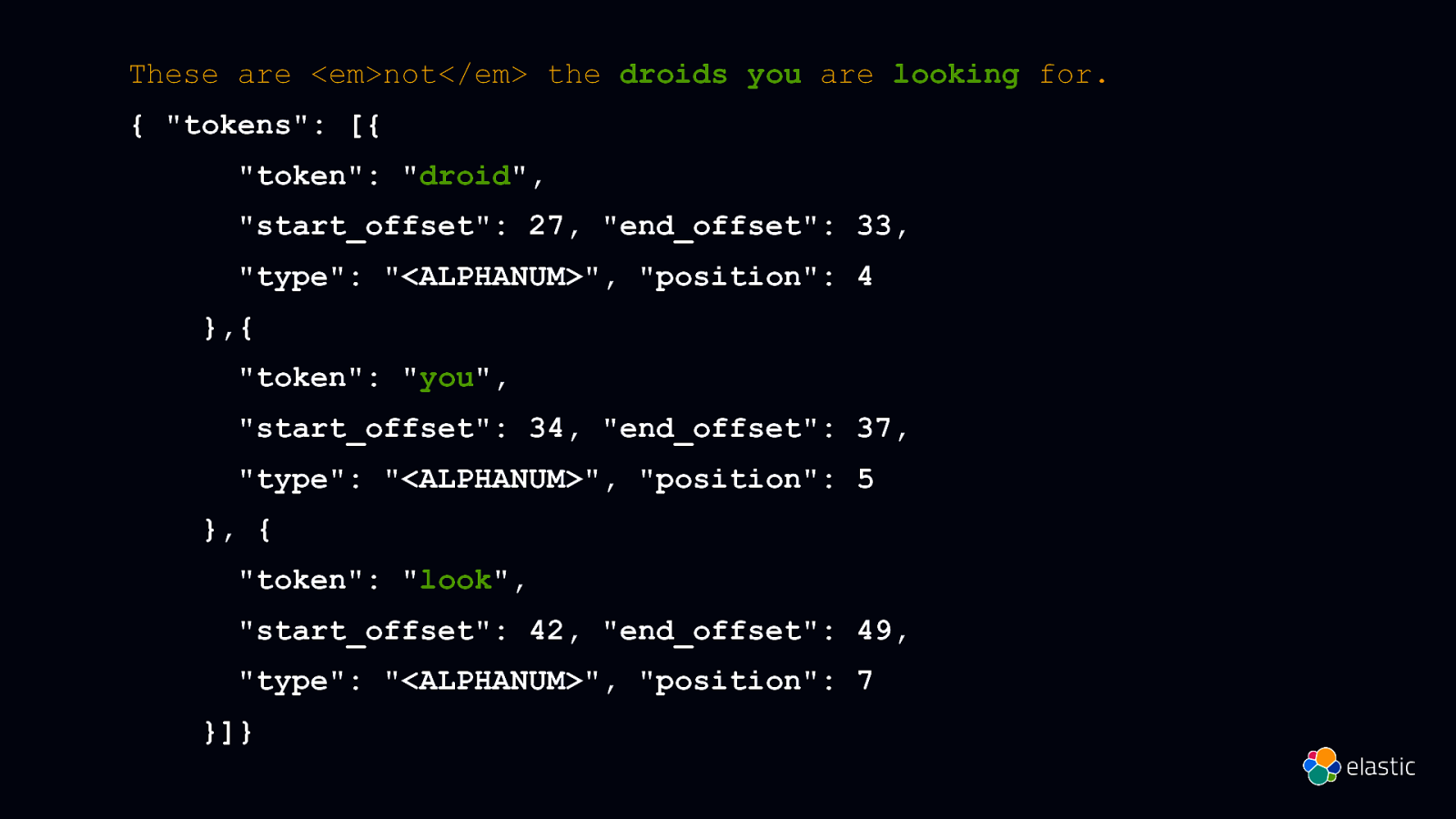
These are <em>not</em> the droids you are looking for. { “tokens”: [{ “token”: “droid”, “start_offset”: 27, “end_offset”: 33, “type”: “<ALPHANUM>”, “position”: 4 },{ “token”: “you”, “start_offset”: 34, “end_offset”: 37, “type”: “<ALPHANUM>”, “position”: 5 }, { “token”: “look”, “start_offset”: 42, “end_offset”: 49, “type”: “<ALPHANUM>”, “position”: 7 }]}
Slide 9

Semantic search ≠ Literal matches
Slide 10

TODAY X-wing starfighter squadron TOMORROW What ships and crews do I need to destroy an almost finished death star? Or is there a secret weakness?
Slide 11

Elasticsearch You Know, for Vector Search
Slide 12

What is a Vector ?
Slide 13
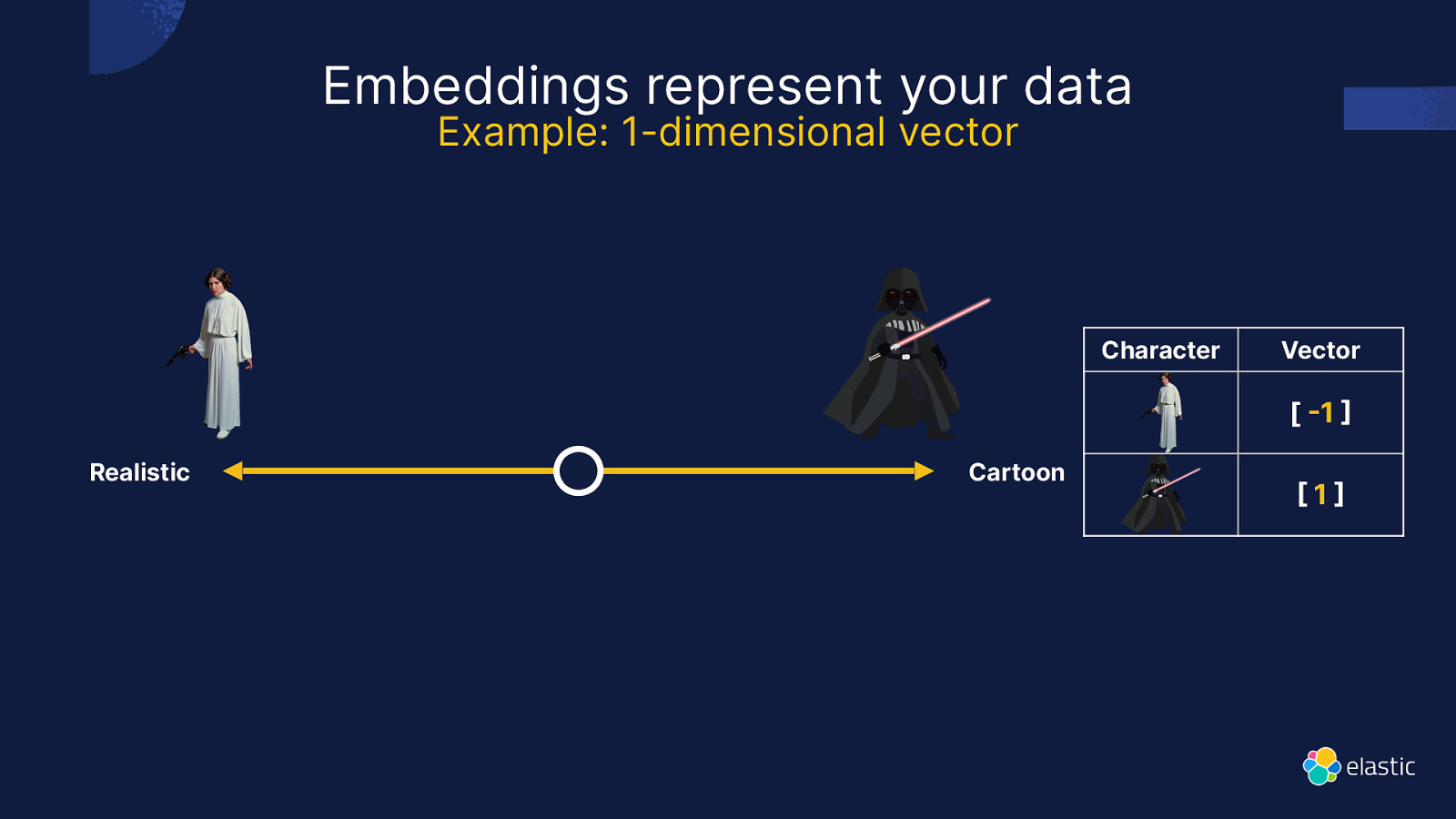
Embeddings represent your data Example: 1-dimensional vector Character Vector [ 1 Realistic Cartoon 1
Slide 14
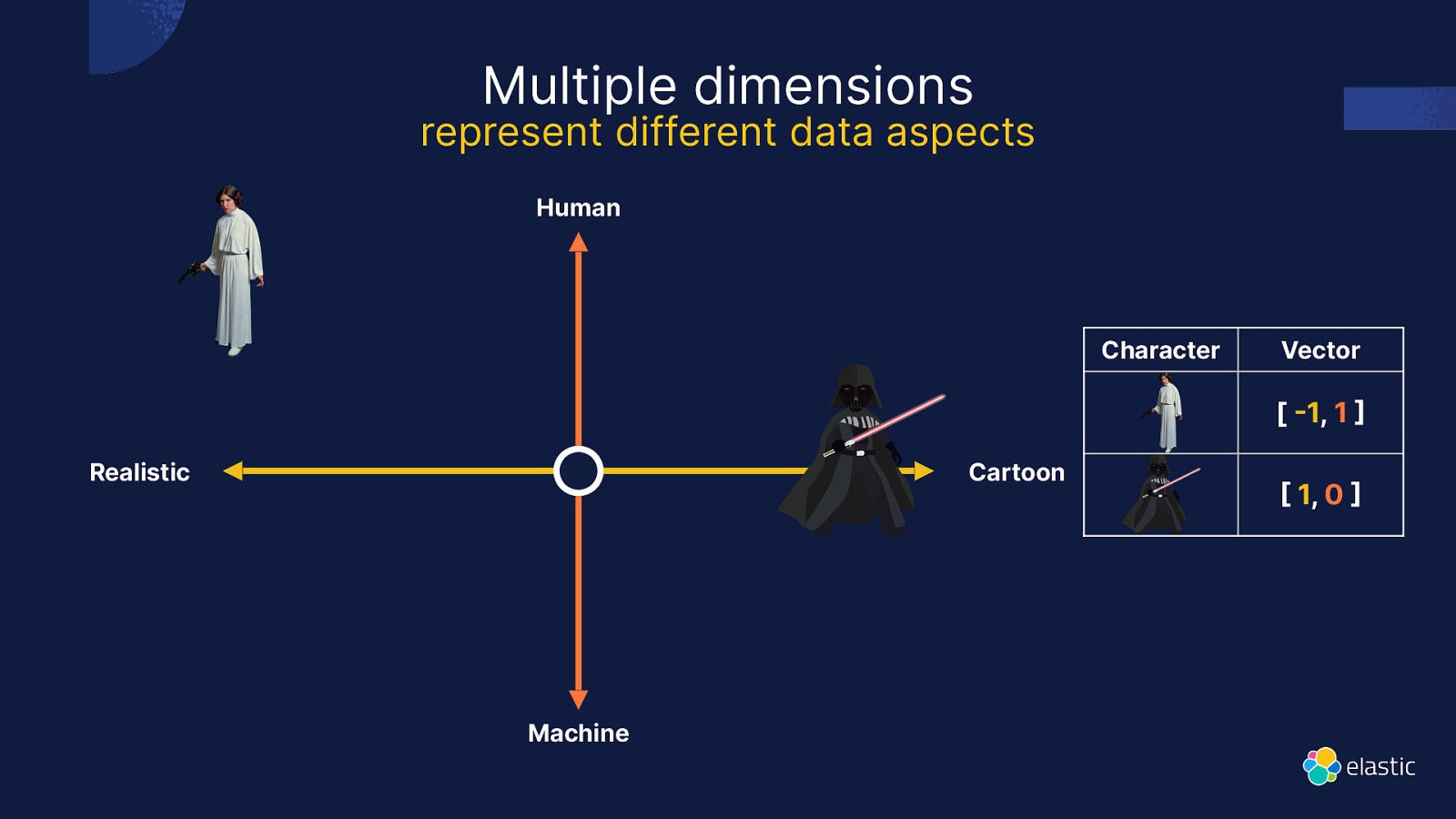
Multiple dimensions represent different data aspects Human Character Vector [ 1, 1 Realistic Cartoon Machine 1, 0
Slide 15
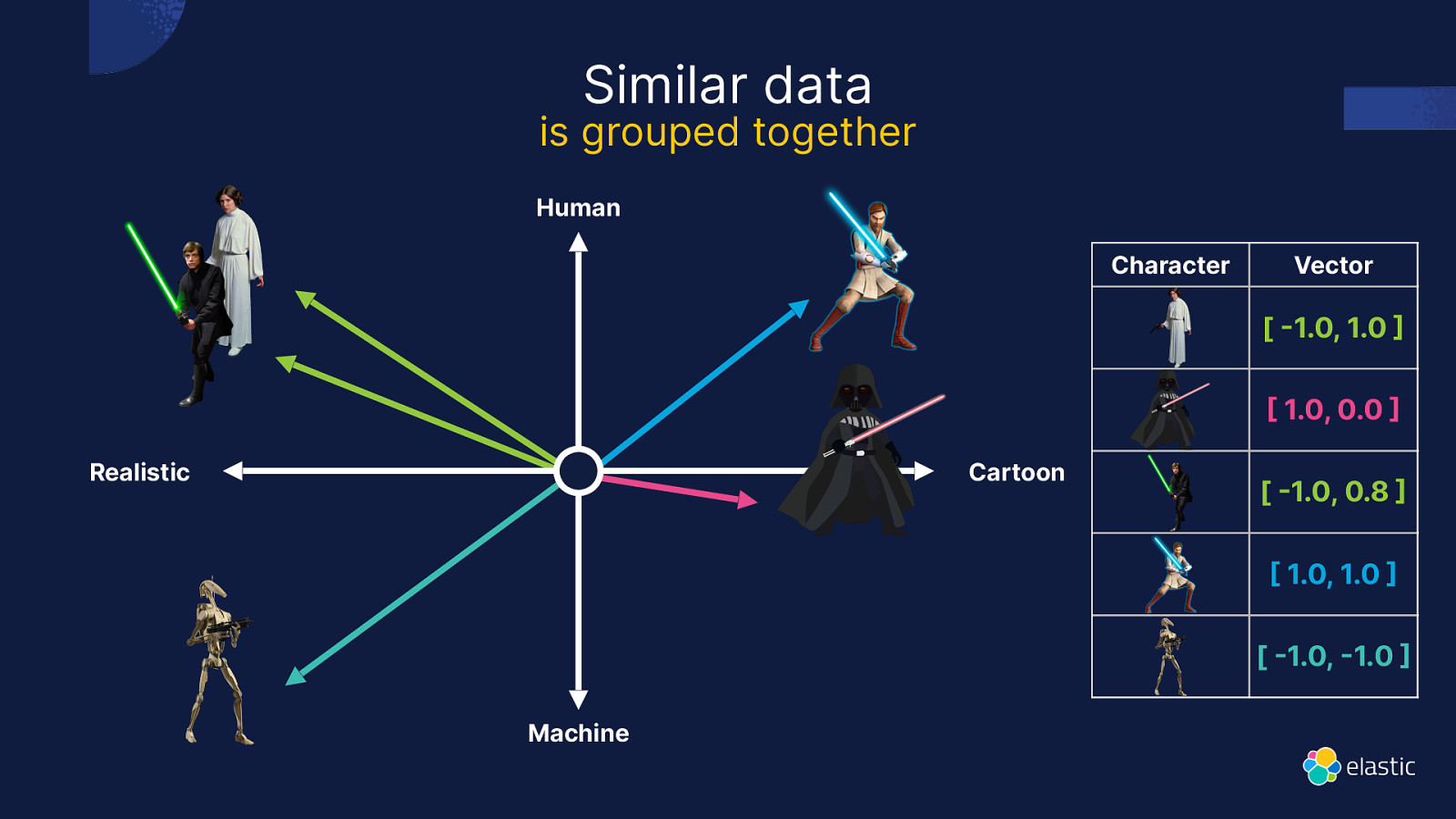
Similar data is grouped together Human Character Vector [ 1.0, 1.0 1.0, 0.0 Realistic Cartoon [ 1.0, 0.8 1.0, 1.0 [ 1.0, 1.0 Machine
Slide 16
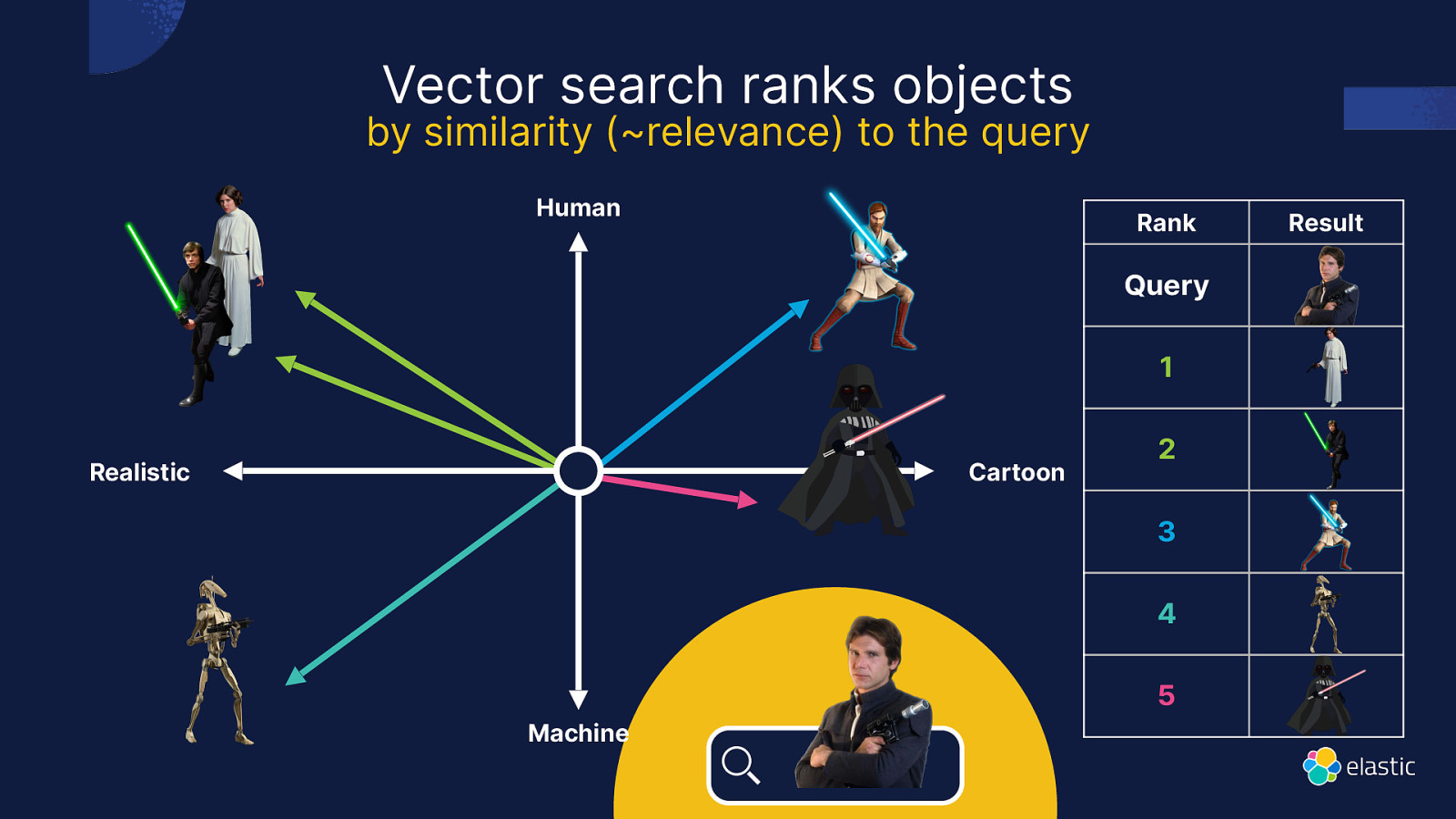
Vector search ranks objects by similarity (~relevance) to the query Human Rank Query 1 Realistic Cartoon 2 3 4 5 Machine Result
Slide 17

Choice of Embedding Model Start with Off-the Shelf Models Extend to Higher Relevance ●Text data: Hugging Face (like Microsoft’s E5 ●Apply hybrid scoring ●Images: OpenAI’s CLIP ●Bring Your Own Model: requires expertise + labeled data
Slide 18

Problem training vs actual use-case
Slide 19
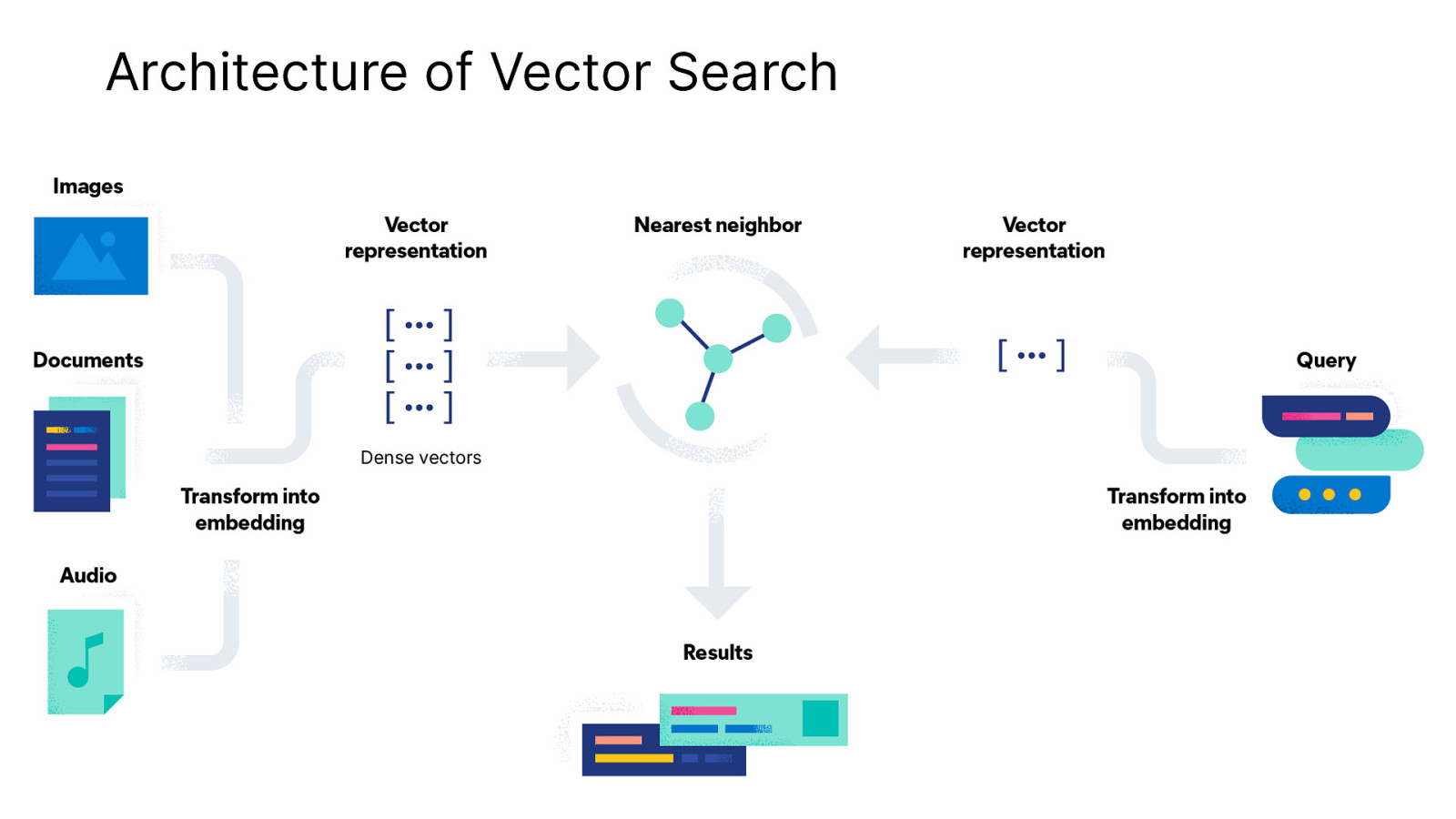
Architecture of Vector Search
Slide 20

How do you index vectors ?
Slide 21
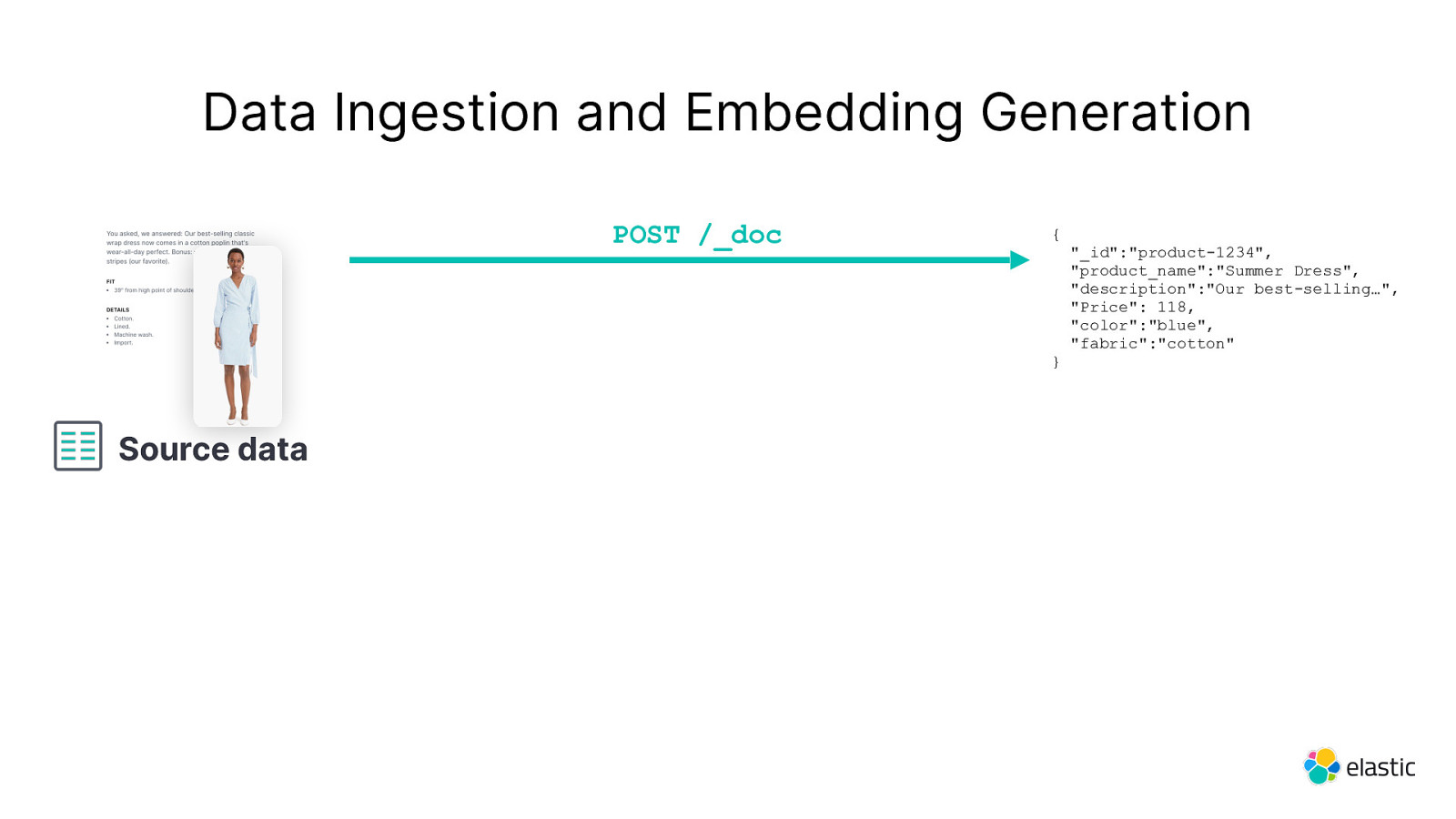
Data Ingestion and Embedding Generation POST /_doc { } Source data “_id”:”product-1234”, “product_name”:”Summer Dress”, “description”:”Our best-selling…”, “Price”: 118, “color”:”blue”, “fabric”:”cotton”
Slide 22
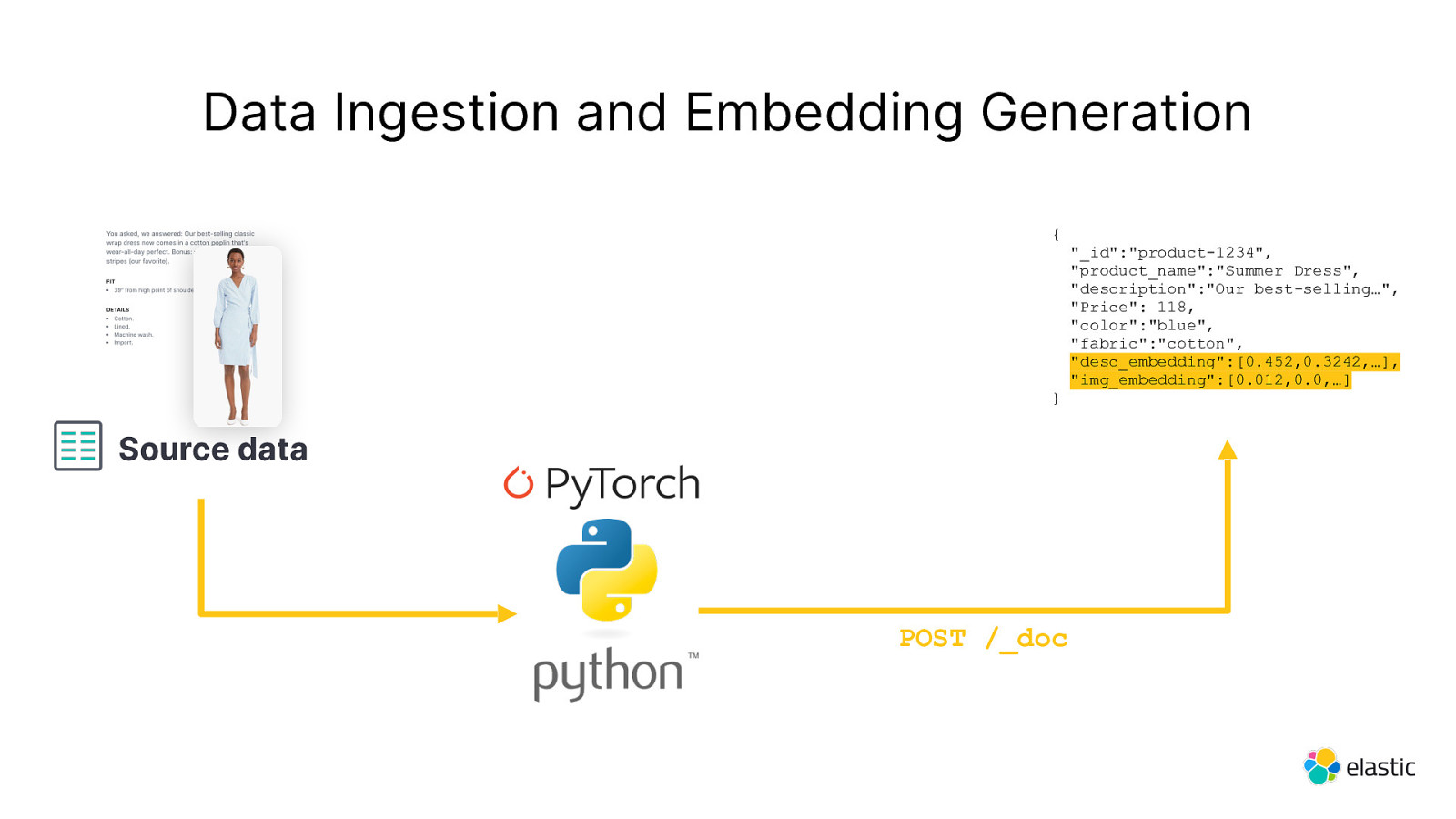
Data Ingestion and Embedding Generation { } Source data POST /_doc “_id”:”product-1234”, “product_name”:”Summer Dress”, “description”:”Our best-selling…”, “Price”: 118, “color”:”blue”, “fabric”:”cotton”, “desc_embedding”:[0.452,0.3242,…], “img_embedding”:[0.012,0.0,…]
Slide 23
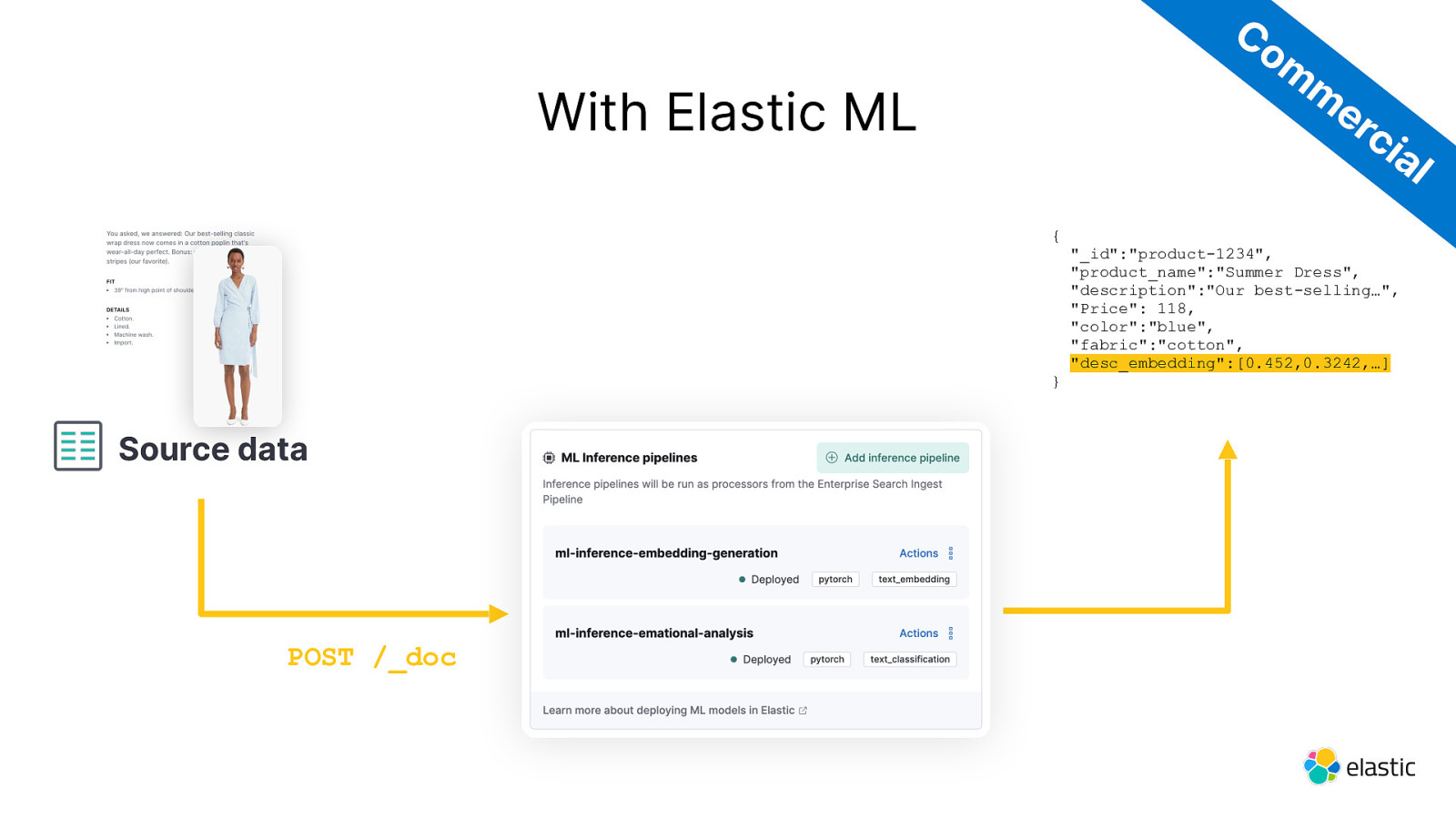
Co m m er ci With Elastic ML al { } Source data POST /_doc “_id”:”product-1234”, “product_name”:”Summer Dress”, “description”:”Our best-selling…”, “Price”: 118, “color”:”blue”, “fabric”:”cotton”, “desc_embedding”:[0.452,0.3242,…]
Slide 24
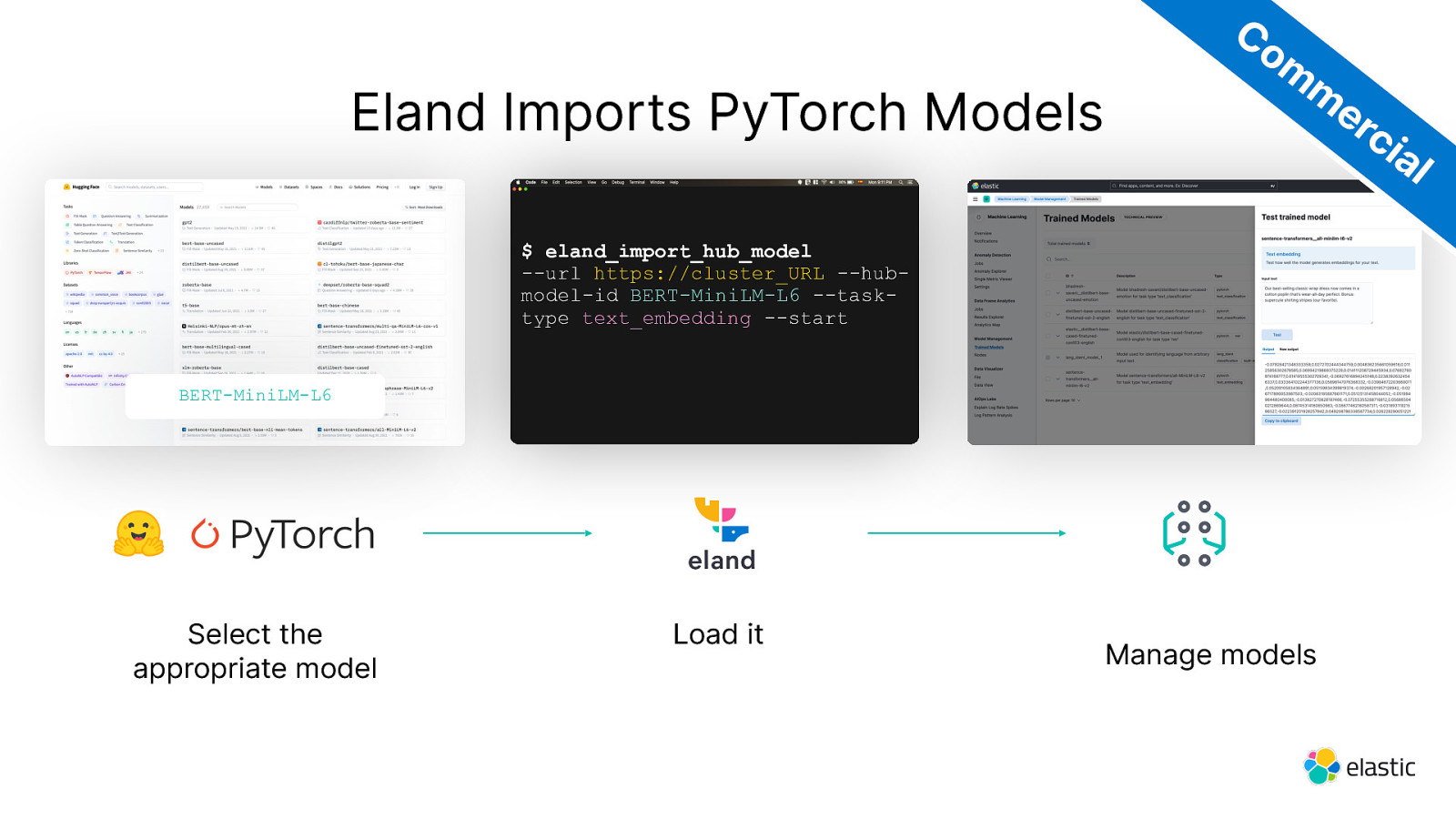
Eland Imports PyTorch Models Co m m er ci al $ eland_import_hub_model —url https://cluster_URL —hubmodel-id BERT-MiniLM-L6 —tasktype text_embedding —start BERT-MiniLM-L6 Select the appropriate model Load it Manage models
Slide 25

Elastic’s range of supported NLP models Co m m er ci ● Fill mask model Mask some of the words in a sentence and predict words that replace masks ● Named entity recognition model NLP method that extracts information from text ● Text embedding model Represent individual words as numerical vectors in a predefined vector space ● Text classification model Assign a set of predefined categories to open-ended text ● Question answering model Model that can answer questions given some or no context ● Zero-shot text classification model Model trained on a set of labeled examples, that is able to classify previously unseen examples Full list at: ela.st/nlp-supported-models al
Slide 26

How do you search vectors ?
Slide 27
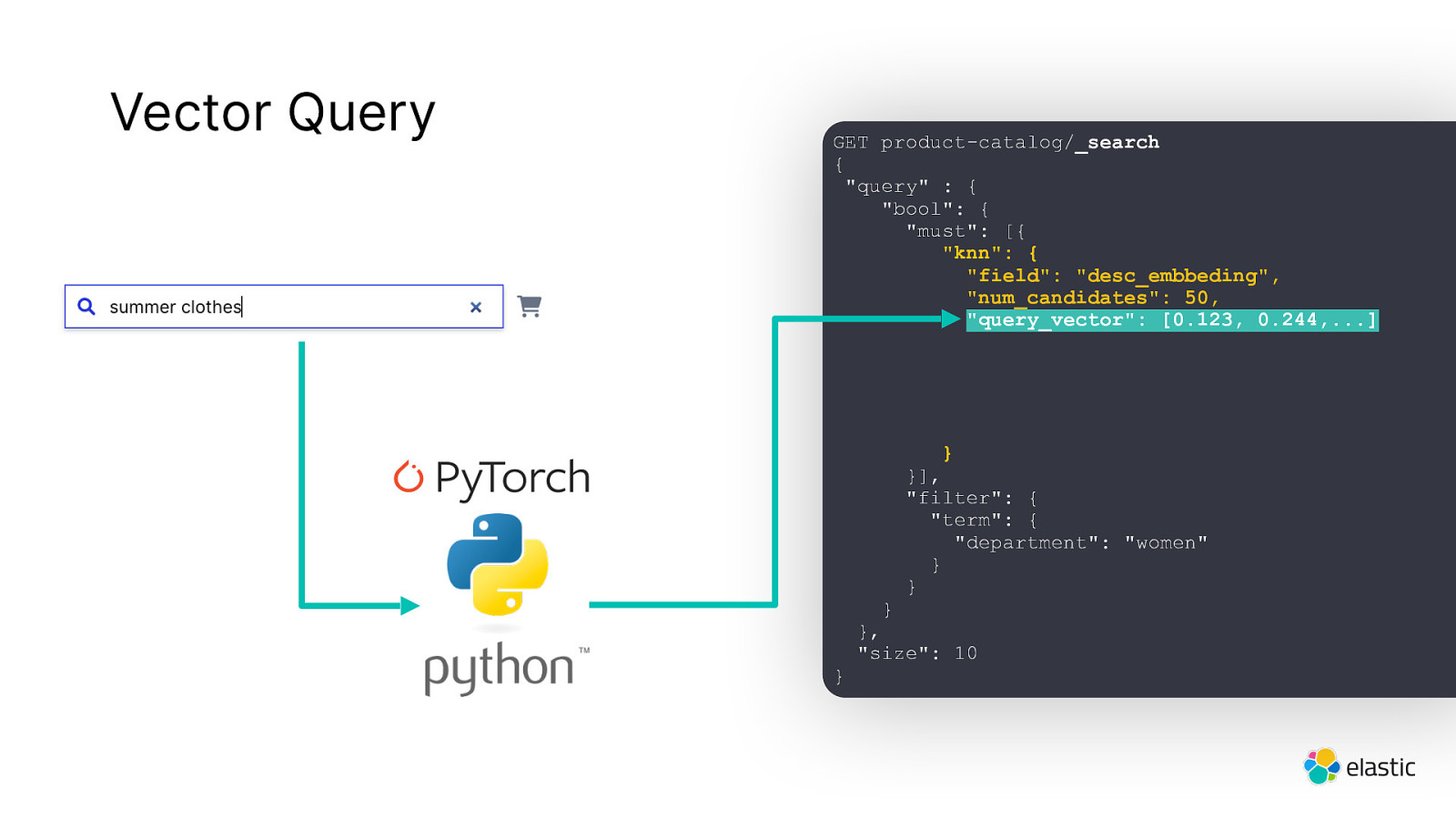
Vector Query GET product-catalog/_search { “query” : { “bool”: { “must”: [{ “knn”: { “field”: “desc_embbeding”, “num_candidates”: 50, “query_vector”: [0.123, 0.244,…] } }], “filter”: { “term”: { “department”: “women” } } } } }, “size”: 10
Slide 28
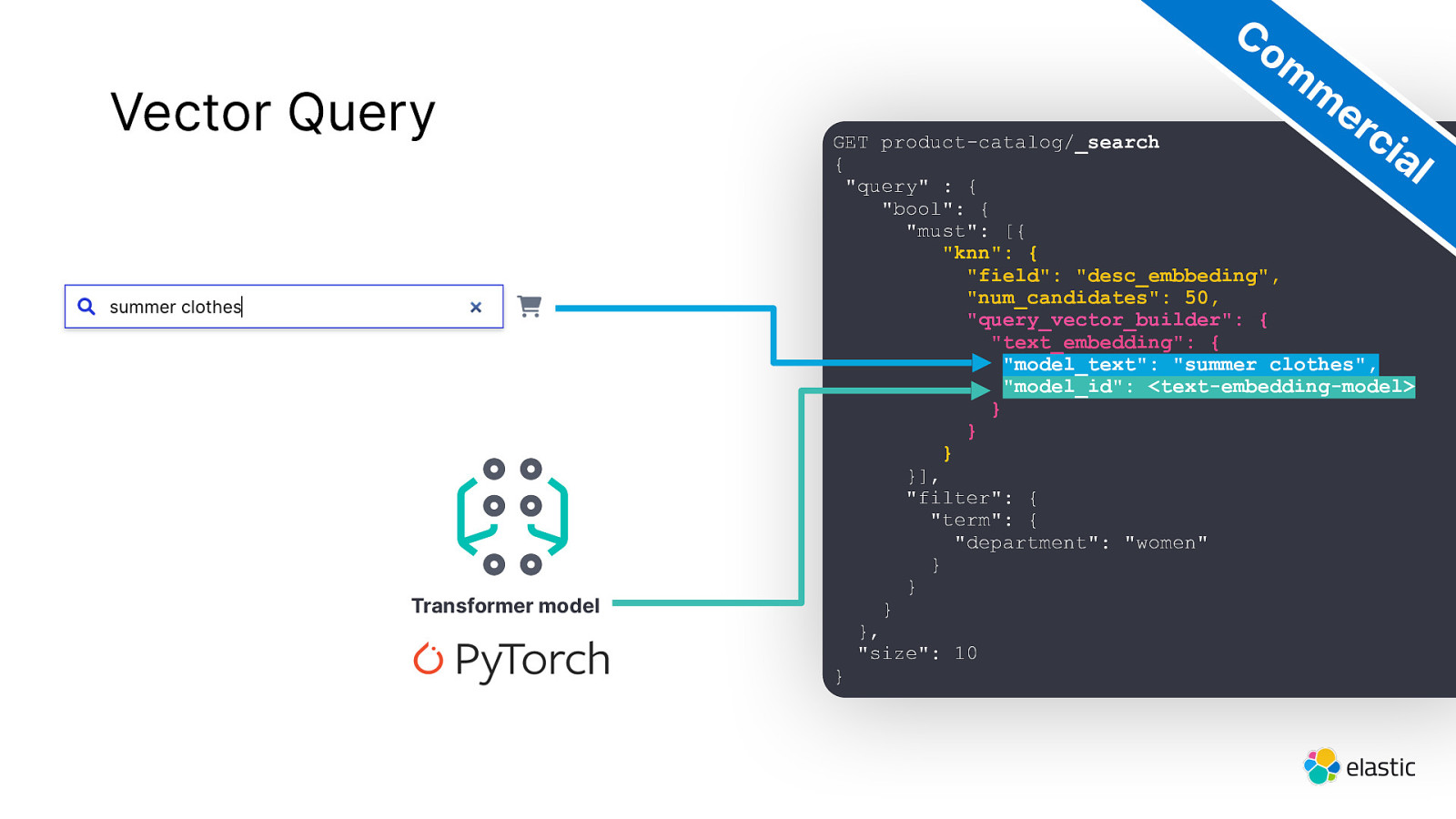
Vector Query Transformer model Co m m er ci al GET product-catalog/_search { “query” : { “bool”: { “must”: [{ “knn”: { “field”: “desc_embbeding”, “num_candidates”: 50, “query_vector_builder”: { “text_embedding”: { “model_text”: “summer clothes”, “model_id”: <text-embedding-model> } } } }], “filter”: { “term”: { “department”: “women” } } } }, “size”: 10 }
Slide 29
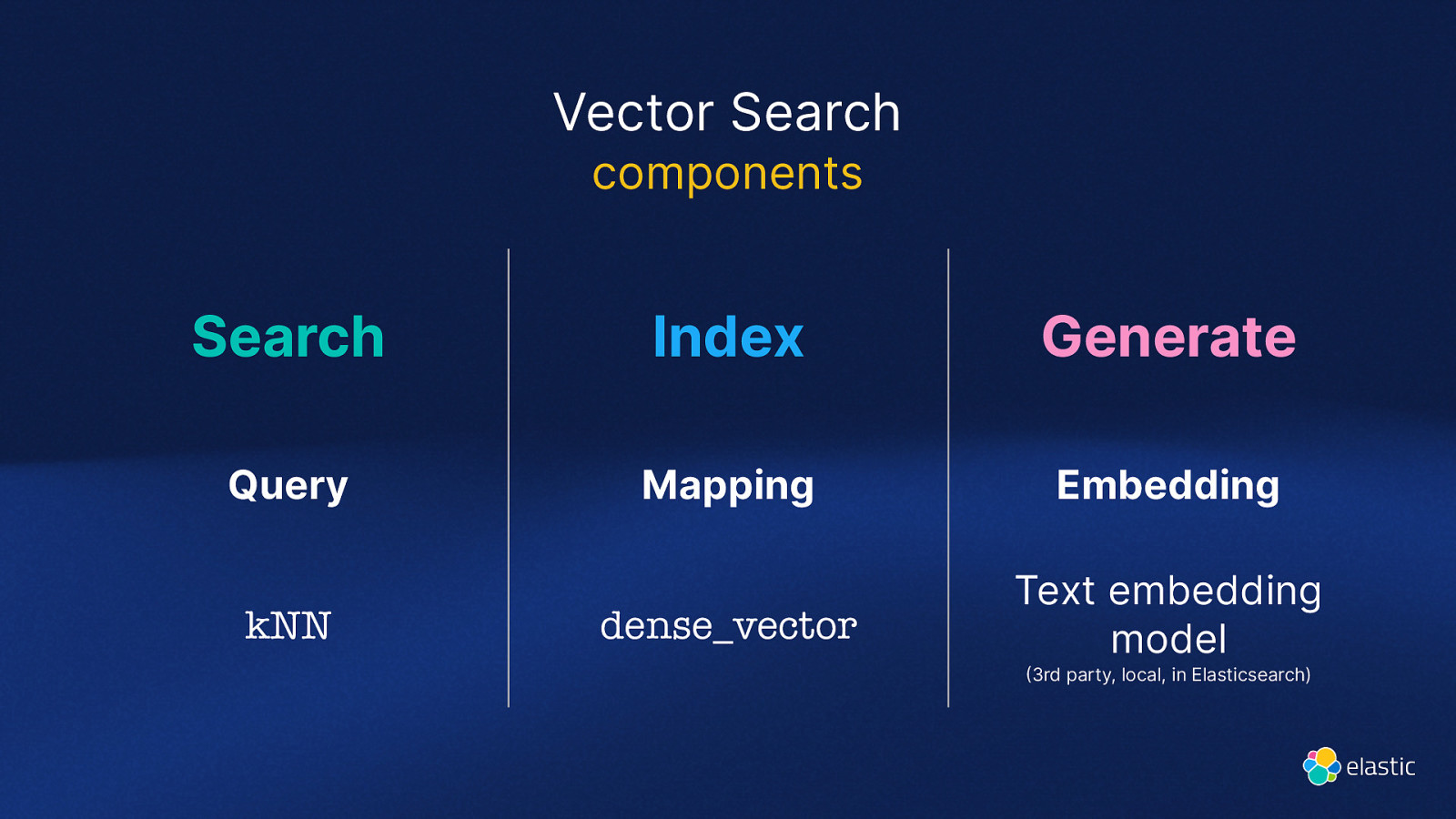
Vector Search components Search Index Generate Query Mapping Embedding dense_vector Text embedding model kNN 3rd party, local, in Elasticsearch)
Slide 30

But how does it really work?
Slide 31
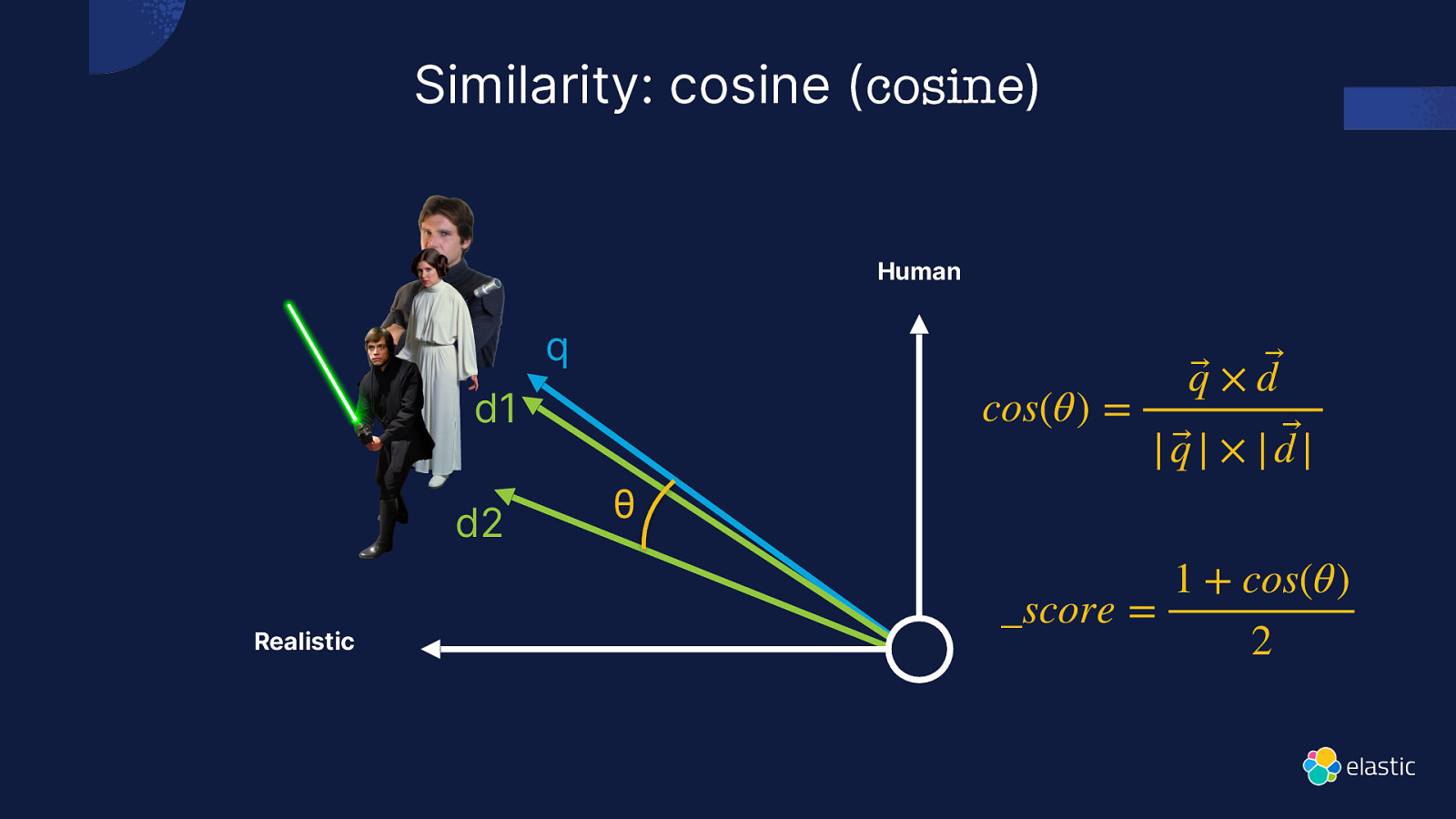
Similarity: cosine (cosine) Human q cos(θ) = d1 d2 Realistic θ q⃗ × d ⃗ | q⃗ | × | d |⃗ _score = 1 + cos(θ) 2
Slide 32
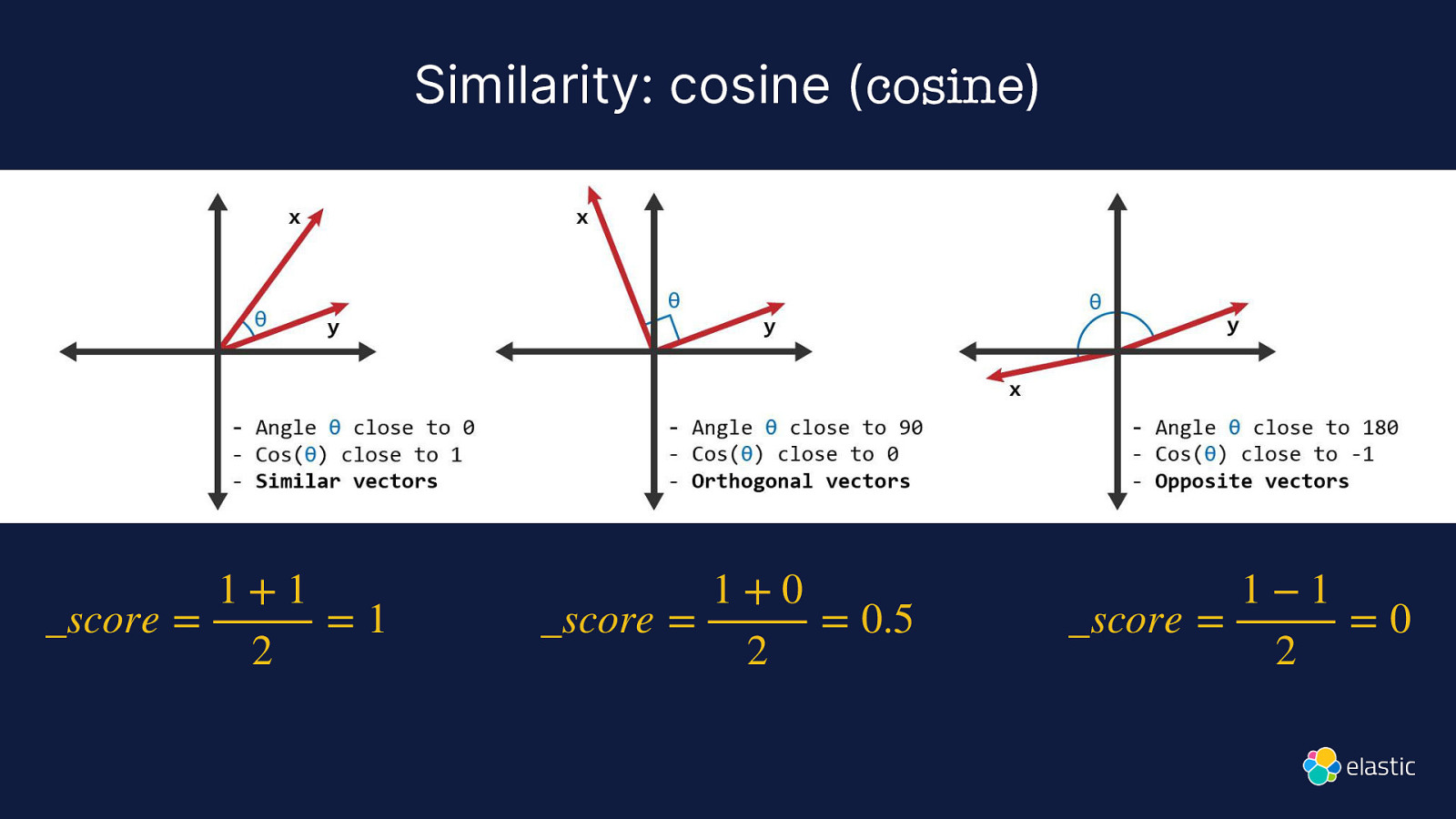
Similarity: cosine (cosine) 1+1 _score = =1 2 1+0 _score = = 0.5 2 1−1 _score = =0 2
Slide 33
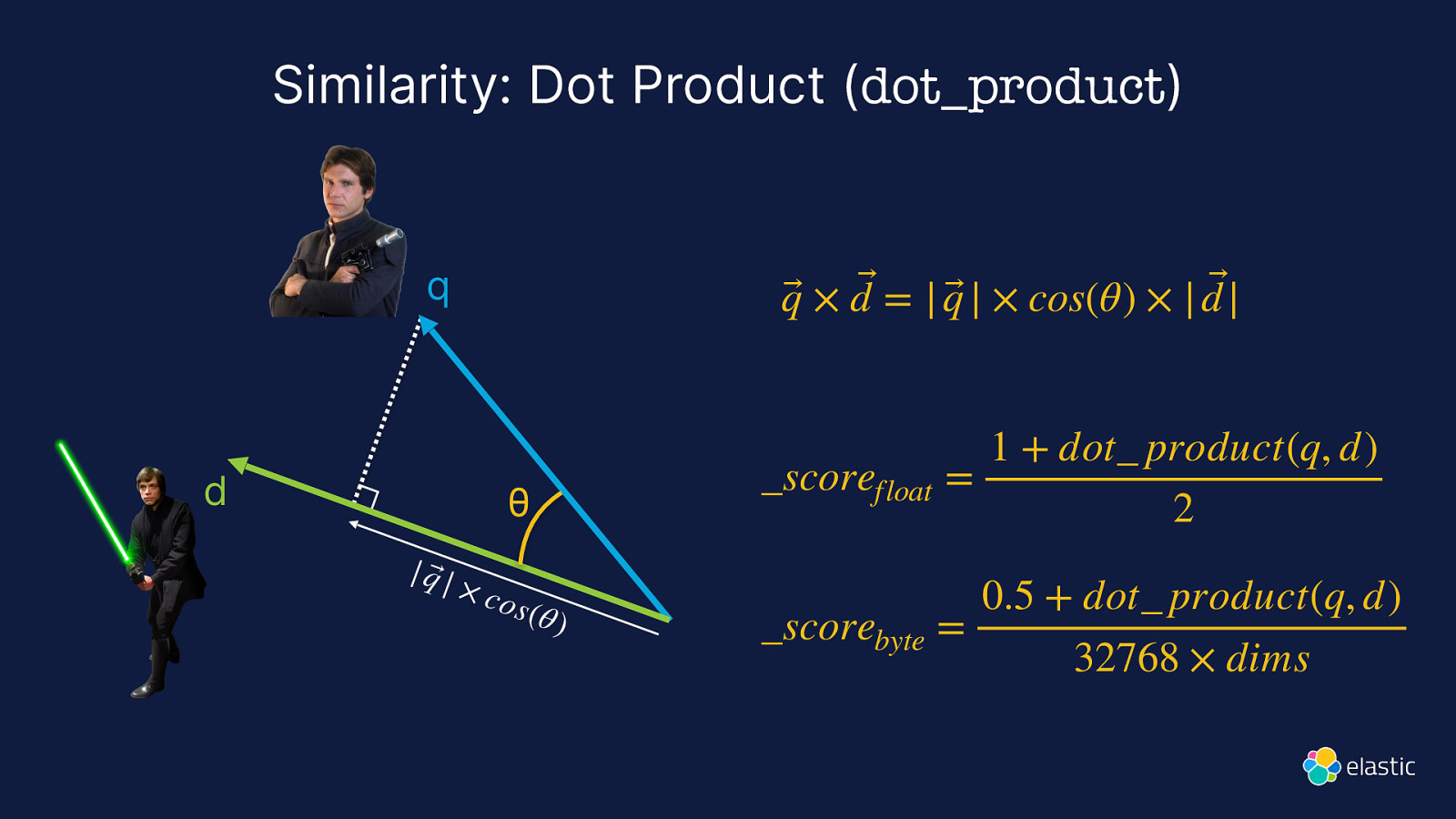
Similarity: Dot Product (dot_product) q d q⃗ × d ⃗ = | q⃗ | × cos(θ) × | d |⃗ θ | q⃗ | × co s (θ ) 1 + dot_ product(q, d) scorefloat = 2 0.5 + dot product(q, d) _scorebyte = 32768 × dims
Slide 34
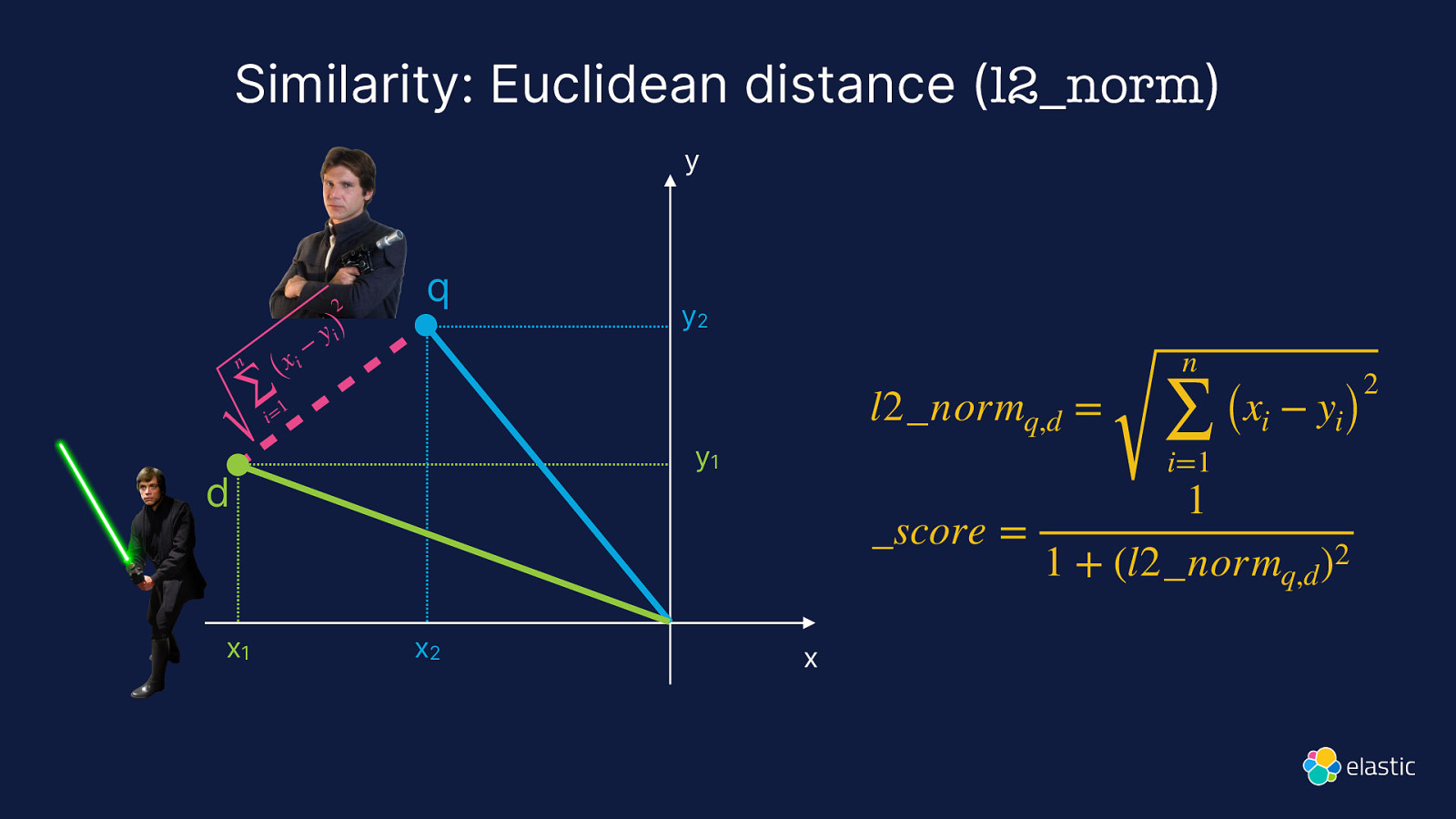
Similarity: Euclidean distance (l2_norm) y 2 n i (x ∑ 1 i= − y i) q l2_normq,d = y1 d x1 y2 x2 n ∑ i=1 (xi − yi) 1 _score = 1 + (l2_normq,d )2 x 2
Slide 35

Brute Force
Slide 36

Hierarchical Navigable Small Worlds (HNSW One popular approach HNSW: a layered approach that simplifies access to the nearest neighbor Tiered: from coarse to fine approximation over a few steps Balance: Bartering a little accuracy for a lot of scalability Speed: Excellent query latency on large scale indices
Slide 37
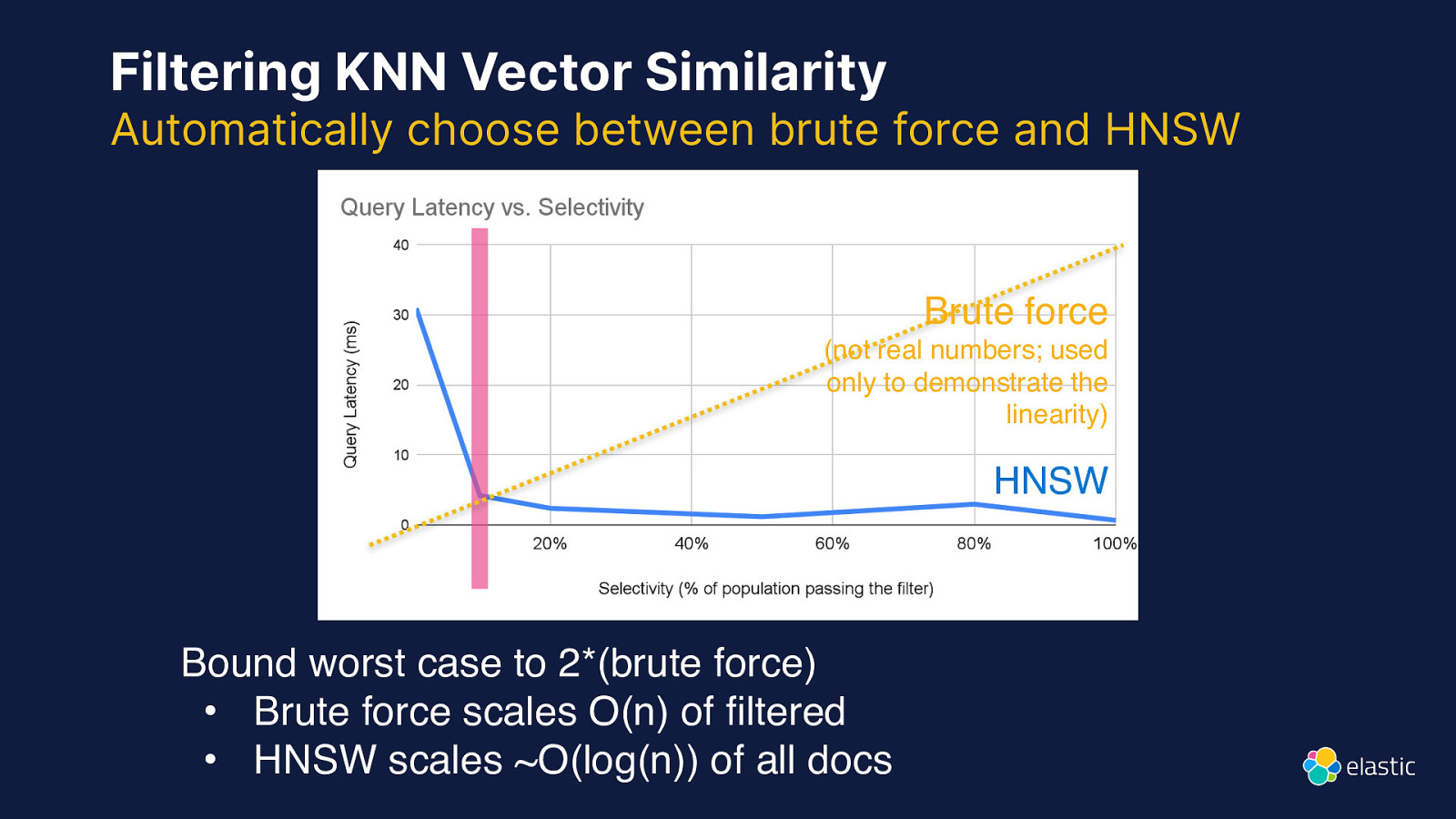
Filtering KNN Vector Similarity Automatically choose between brute force and HNSW Brute force (not real numbers; used only to demonstrate the linearity) HNSW Bound worst case to 2*(brute force) • Brute force scales O(n) of filtered • HNSW scales ~O(log(n)) of all docs
Slide 38
Elasticsearch + Lucene = fast progress ❤
Slide 39

Scaling Vector Search Vector search Best practices
- Needs lots of memory
- Avoid searches during indexing
- Indexing is slower
- Exclude vectors from _source
- Merging is slow
- Reduce vector dimensionality 4. Use byte rather than float
- Continuous improvements in Lucene + Elasticsearch
Slide 40
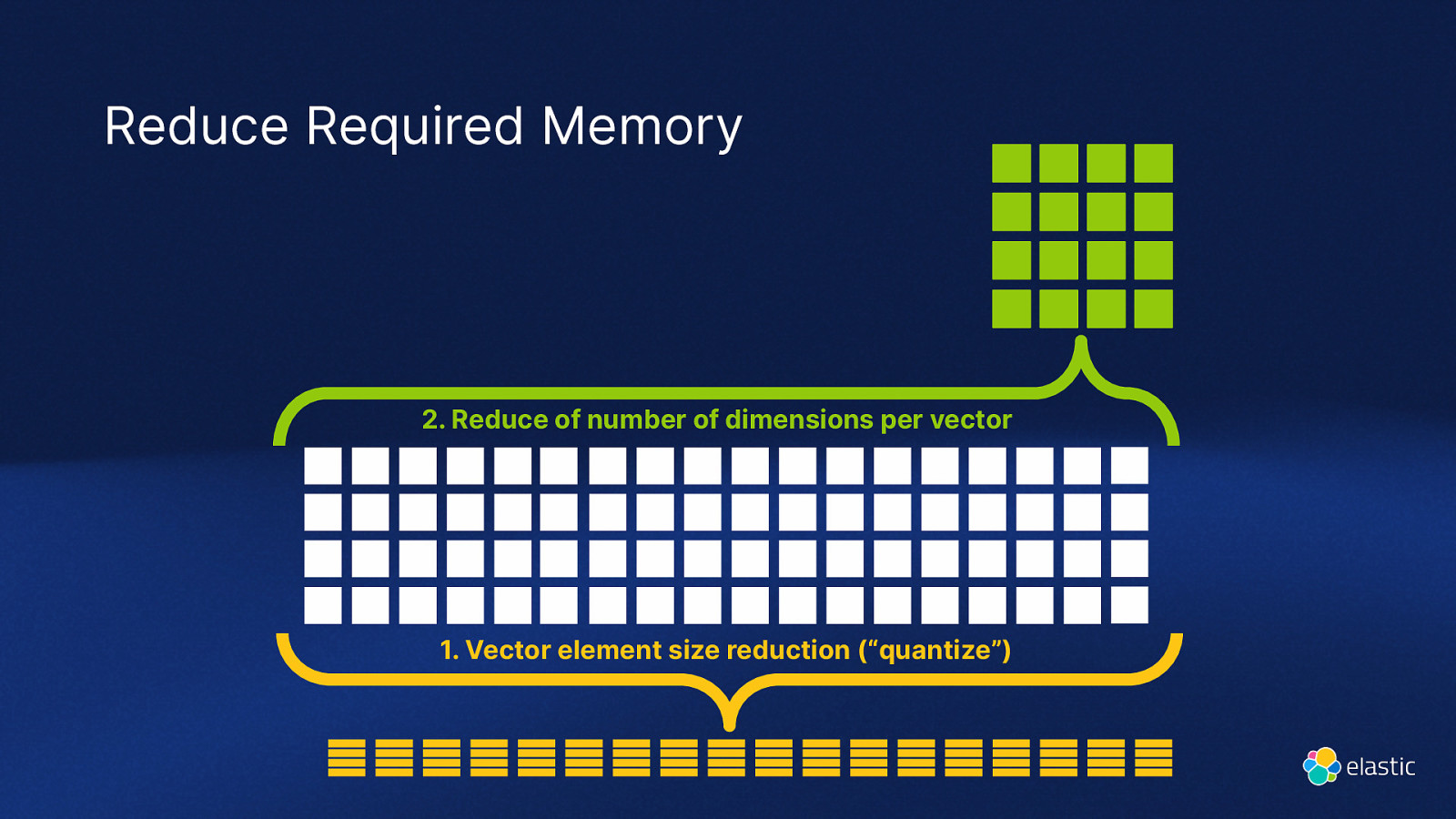
Reduce Required Memory 2. Reduce of number of dimensions per vector
- Vector element size reduction (“quantize”)
Slide 41

Benchmarketing
Slide 42
https://github.com/erikbern/ann-benchmarks
Slide 43

Elasticsearch You Know, for Hybrid Search
Slide 44
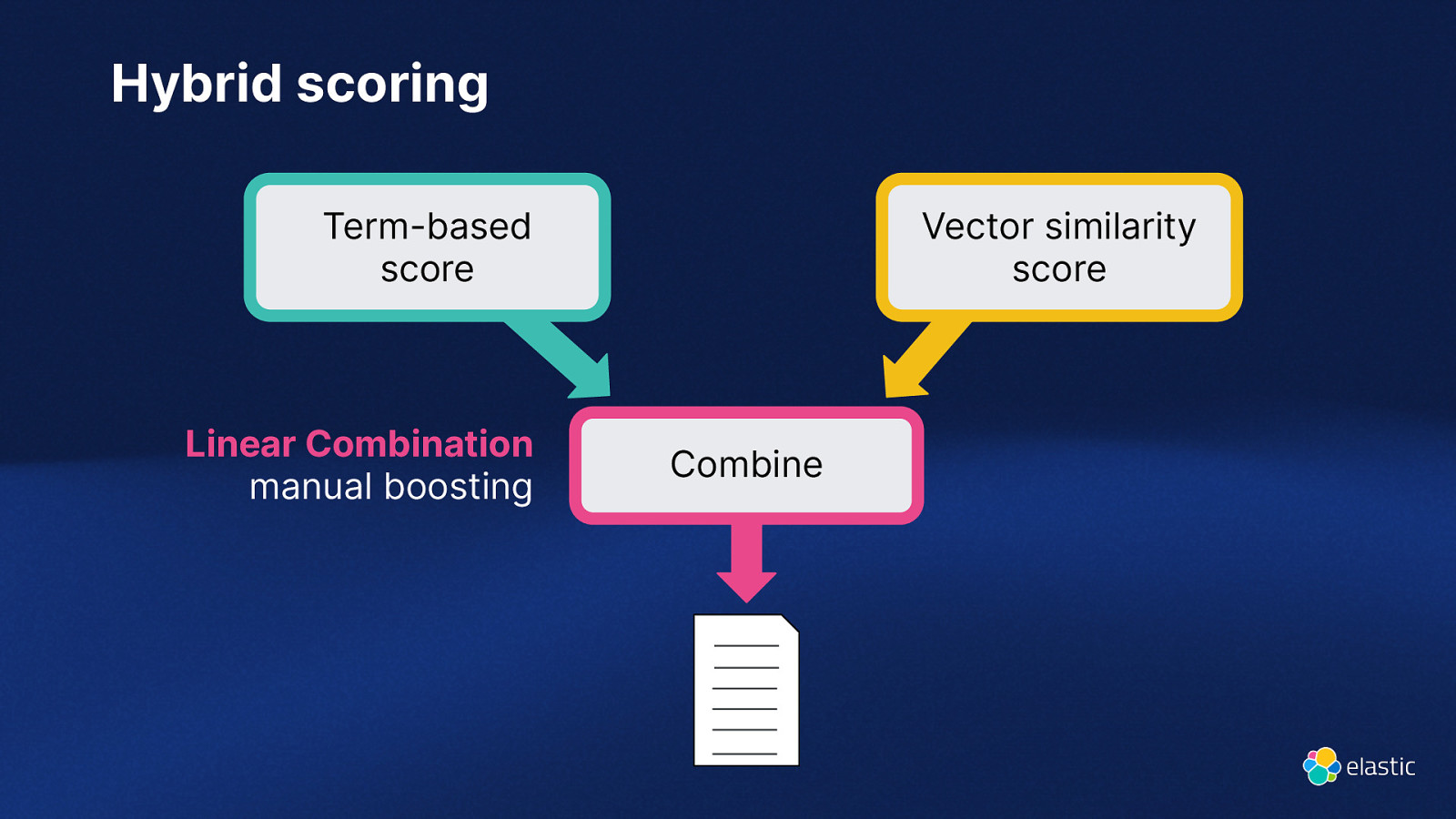
Hybrid scoring Term-based score Linear Combination manual boosting Vector similarity score Combine
Slide 45
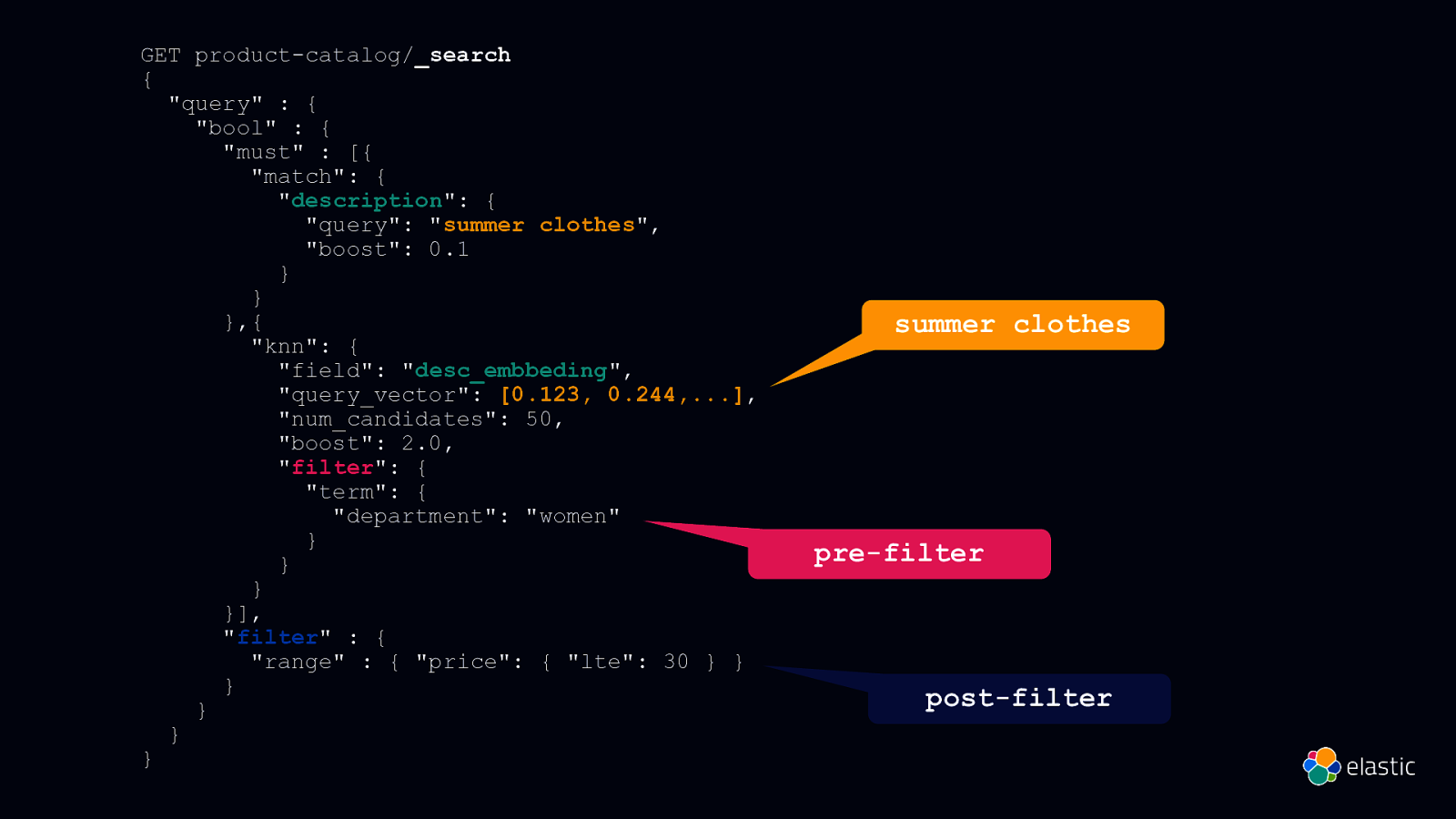
GET product-catalog/_search { “query” : { “bool” : { “must” : [{ “match”: { “description”: { “query”: “summer clothes”, “boost”: 0.1 } } },{ “knn”: { “field”: “desc_embbeding”, “query_vector”: [0.123, 0.244,…], “num_candidates”: 50, “boost”: 2.0, “filter”: { “term”: { “department”: “women” } } } }], “filter” : { “range” : { “price”: { “lte”: 30 } } } } } } summer clothes pre-filter post-filter
Slide 46
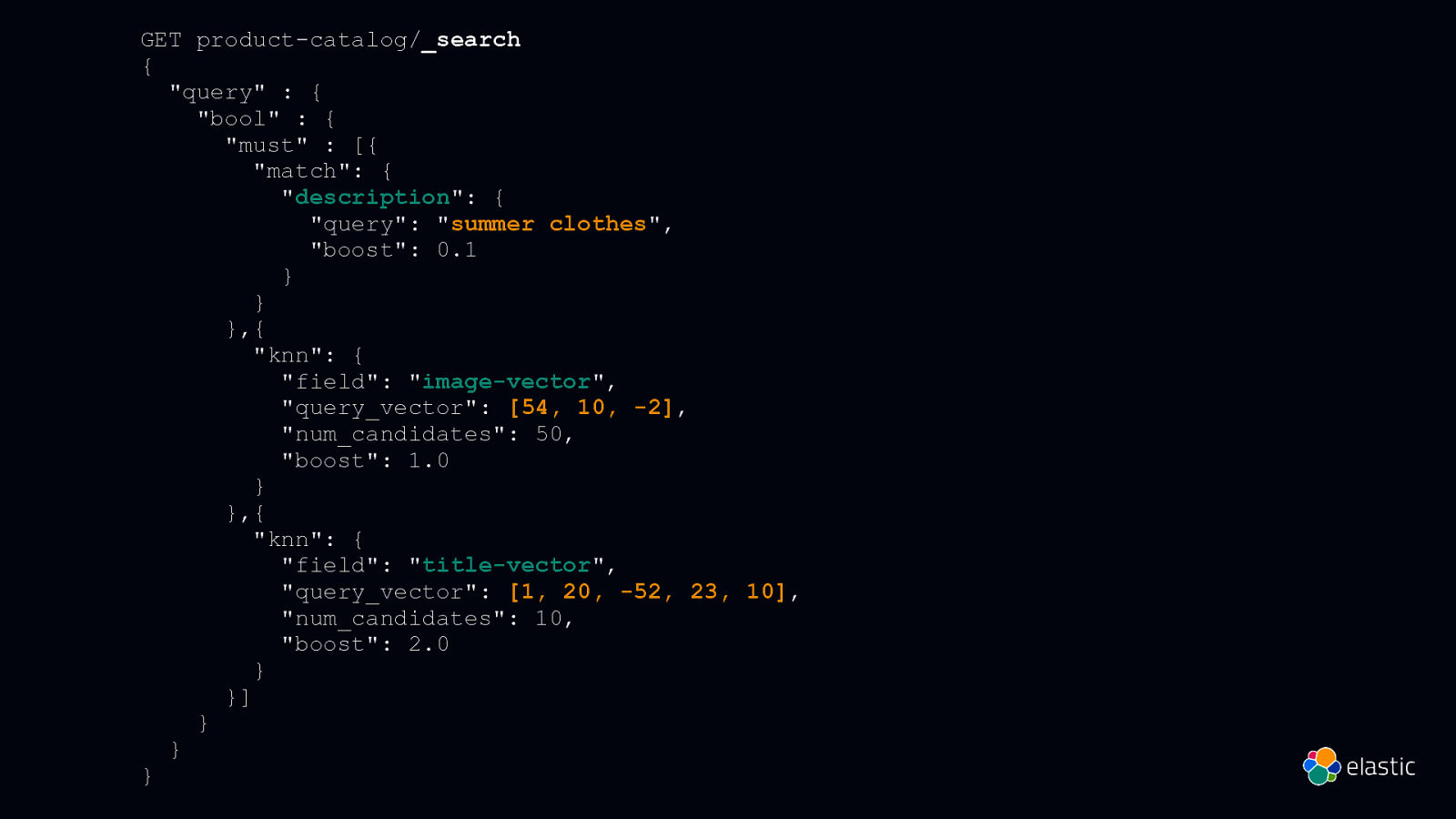
GET product-catalog/_search { “query” : { “bool” : { “must” : [{ “match”: { “description”: { “query”: “summer clothes”, “boost”: 0.1 } } },{ “knn”: { “field”: “image-vector”, “query_vector”: [54, 10, -2], “num_candidates”: 50, “boost”: 1.0 } },{ “knn”: { “field”: “title-vector”, “query_vector”: [1, 20, -52, 23, 10], “num_candidates”: 10, “boost”: 2.0 } }] } } }
Slide 47

ELSER Elastic Learned Sparse EncodER text_expansion Not BM25 or (dense) vector Sparse vector like BM25 Stored as inverted index Co m m er ci al
Slide 48
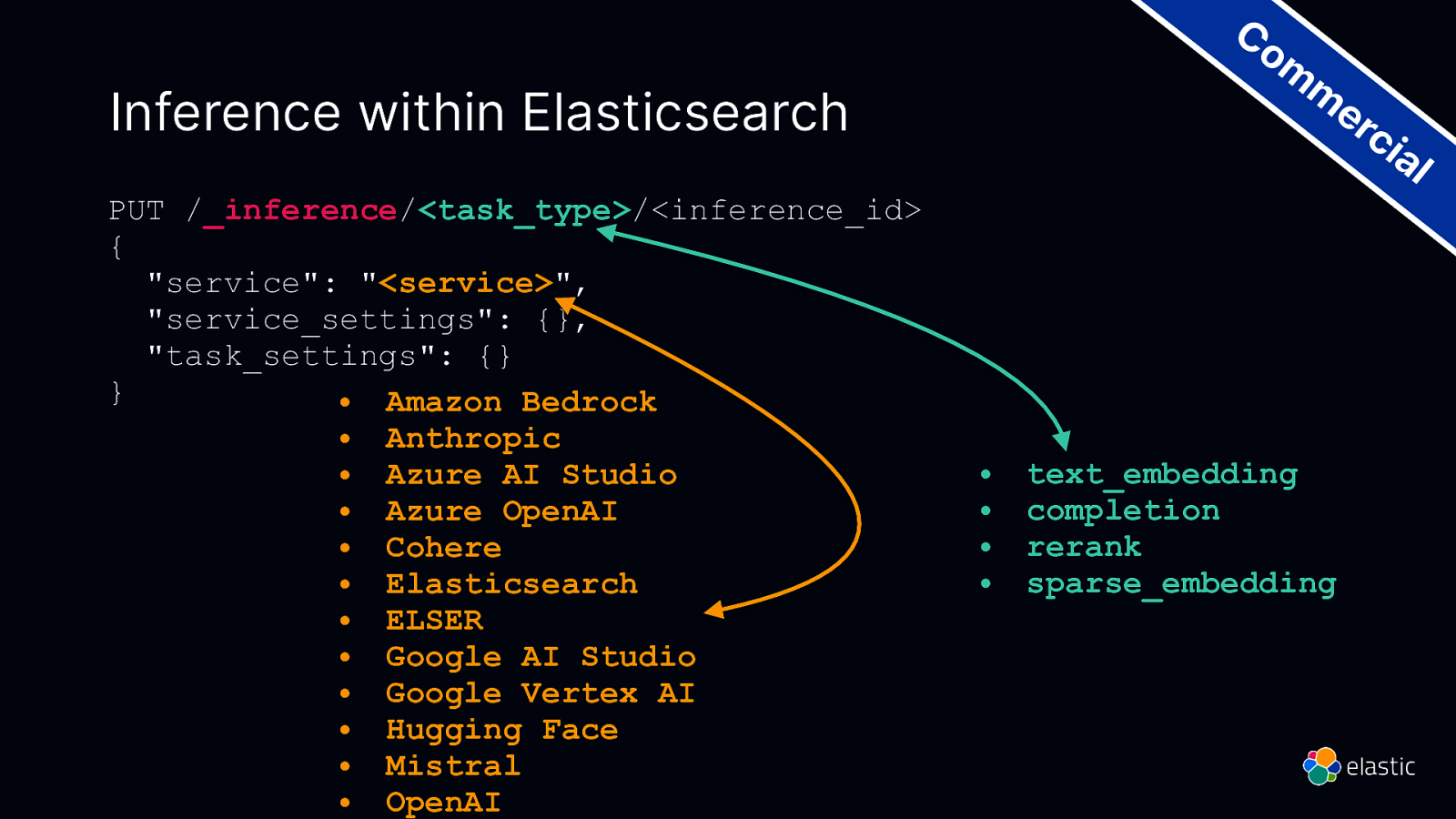
Co m m er ci Inference within Elasticsearch PUT /_inference/<task_type>/<inference_id> { “service”: “<service>”, “service_settings”: {}, “task_settings”: {} } • Amazon Bedrock • Anthropic • Azure AI Studio • Azure OpenAI • Cohere • Elasticsearch • ELSER • Google AI Studio • Google Vertex AI • Hugging Face • Mistral • OpenAI al • • • • text_embedding completion rerank sparse_embedding
Slide 49
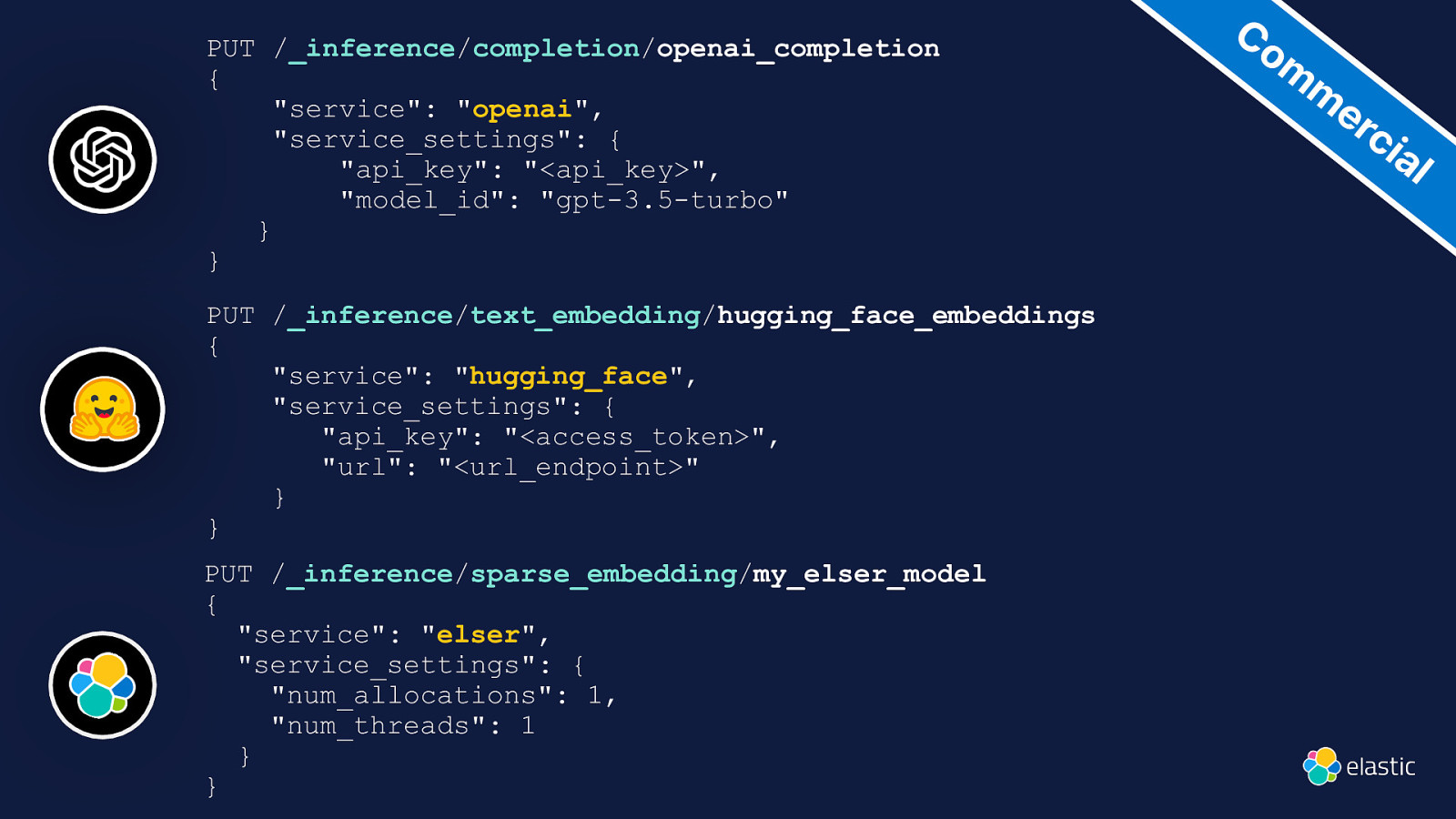
PUT /_inference/completion/openai_completion { “service”: “openai”, “service_settings”: { “api_key”: “<api_key>”, “model_id”: “gpt-3.5-turbo” } } PUT /_inference/text_embedding/hugging_face_embeddings { “service”: “hugging_face”, “service_settings”: { “api_key”: “<access_token>”, “url”: “<url_endpoint>” } } PUT /_inference/sparse_embedding/my_elser_model { “service”: “elser”, “service_settings”: { “num_allocations”: 1, “num_threads”: 1 } } Co m m er ci al
Slide 50
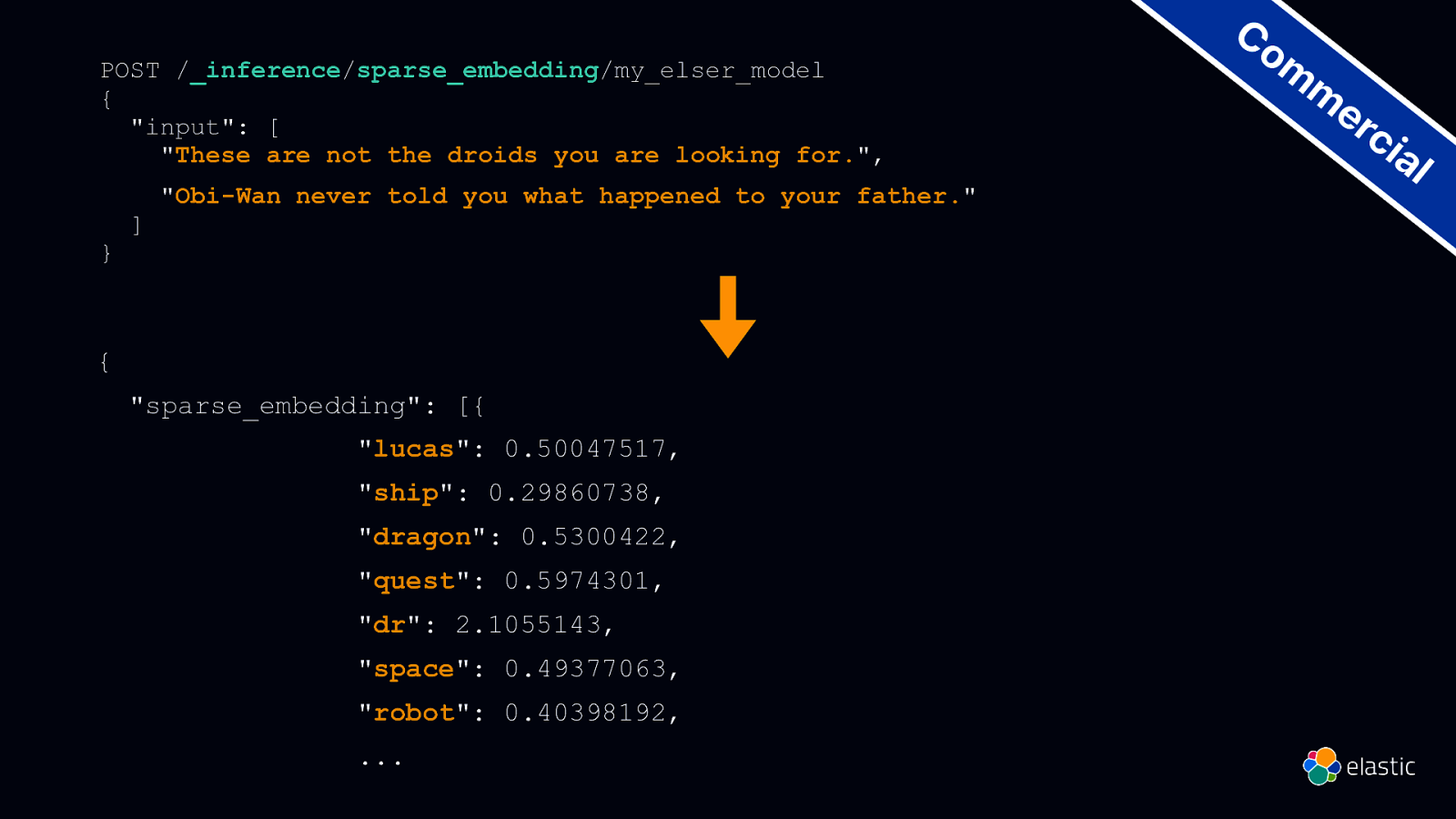
POST /_inference/sparse_embedding/my_elser_model { “input”: [ “These are not the droids you are looking for.”, } ] “Obi-Wan never told you what happened to your father.” { “sparse_embedding”: [{ “lucas”: 0.50047517, “ship”: 0.29860738, “dragon”: 0.5300422, “quest”: 0.5974301, “dr”: 2.1055143, “space”: 0.49377063, “robot”: 0.40398192, … Co m m er ci al
Slide 51
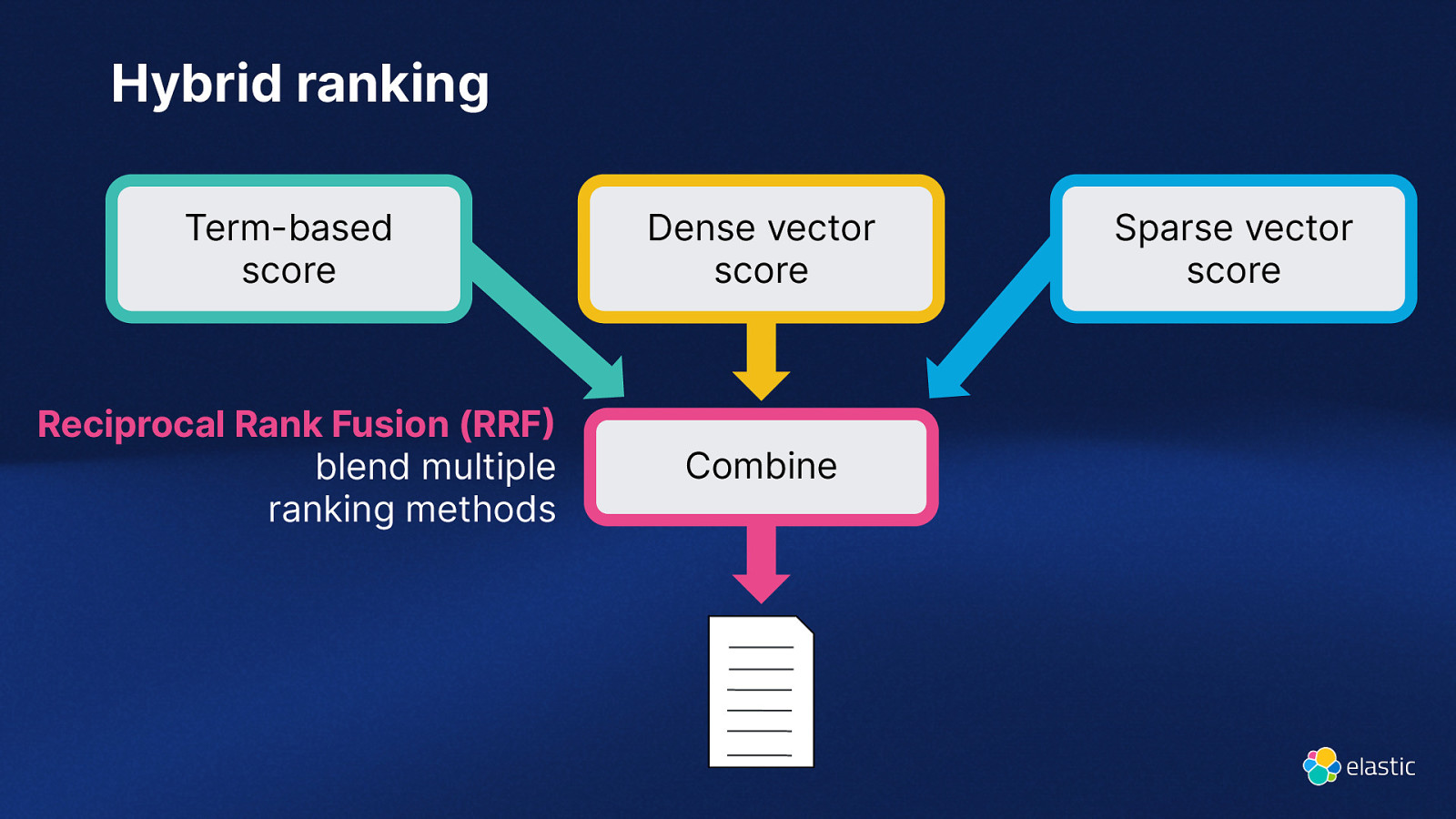
Hybrid ranking Term-based score Dense vector score Reciprocal Rank Fusion (RRF blend multiple ranking methods Combine Sparse vector score
Slide 52

Reciprocal Rank Fusion (RRF D set of docs R set of rankings as permutation on 1..|D| k - typically set to 60 by default Ranking Algorithm 1 Doc Ranking Algorithm 2 Score r(d) k+r(d) A 1 1 B 0.7 C D E Doc Score r(d) k+r(d) 61 C 1,341 1 61 2 62 A 739 2 62 0.5 3 63 F 732 3 63 0.2 4 64 G 192 4 64 0.01 5 65 H 183 5 65 Doc RRF Score A 1/61 1/62 0,0325 C 1/63 1/61 0,0323 B 1/62 0,0161 F 1/63 0,0159 D 1/64 0,0156
Slide 53

GET index/_search { “retriever”: { “rrf”: { “retrievers”: [{ “standard” { “query”: { “match”: {…} } } },{ “standard” { “query”: { “text_expansion”: {…} } } },{ “knn”: { … } } ] } } } Hybrid Ranking BM25f + ELSER + Vector
Slide 54

https://djdadoo.pilato.fr/
Slide 55
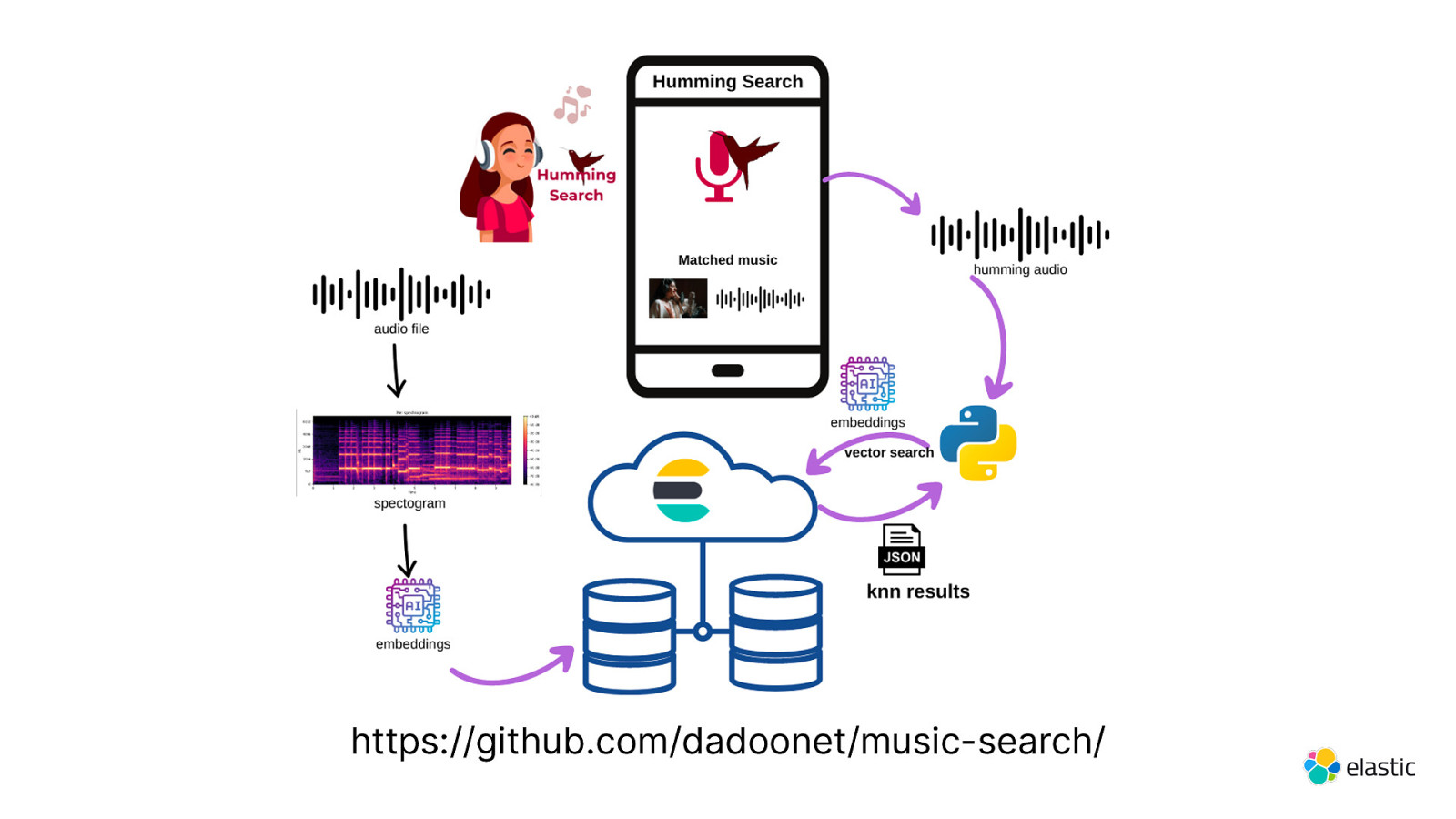
https://github.com/dadoonet/music-search/
Slide 56

ChatGPT Elastic and LLM
Slide 57

Gen AI Search engines
Slide 58
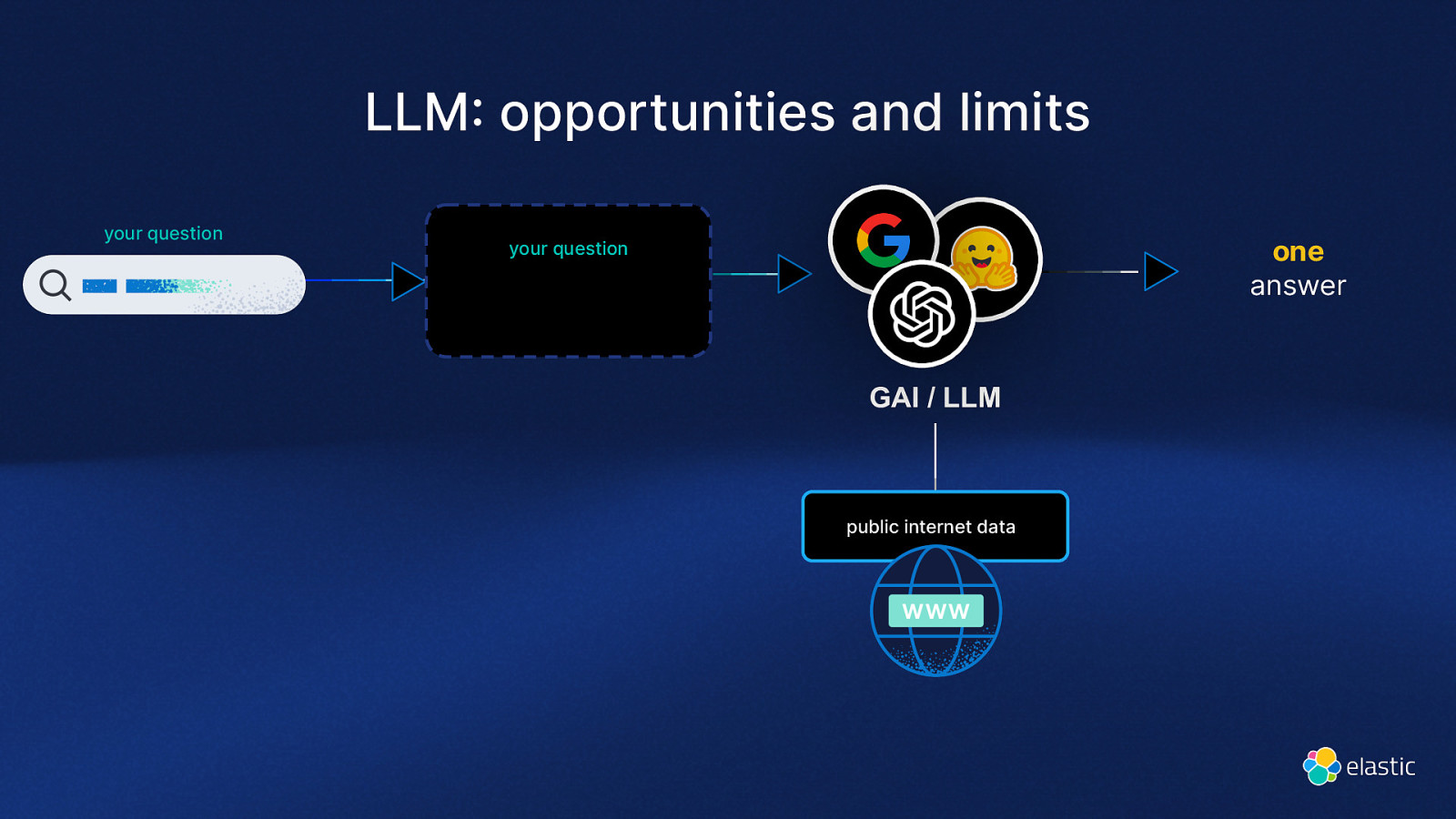
LLM opportunities and limits your question one answer your question GAI / LLM public internet data
Slide 59
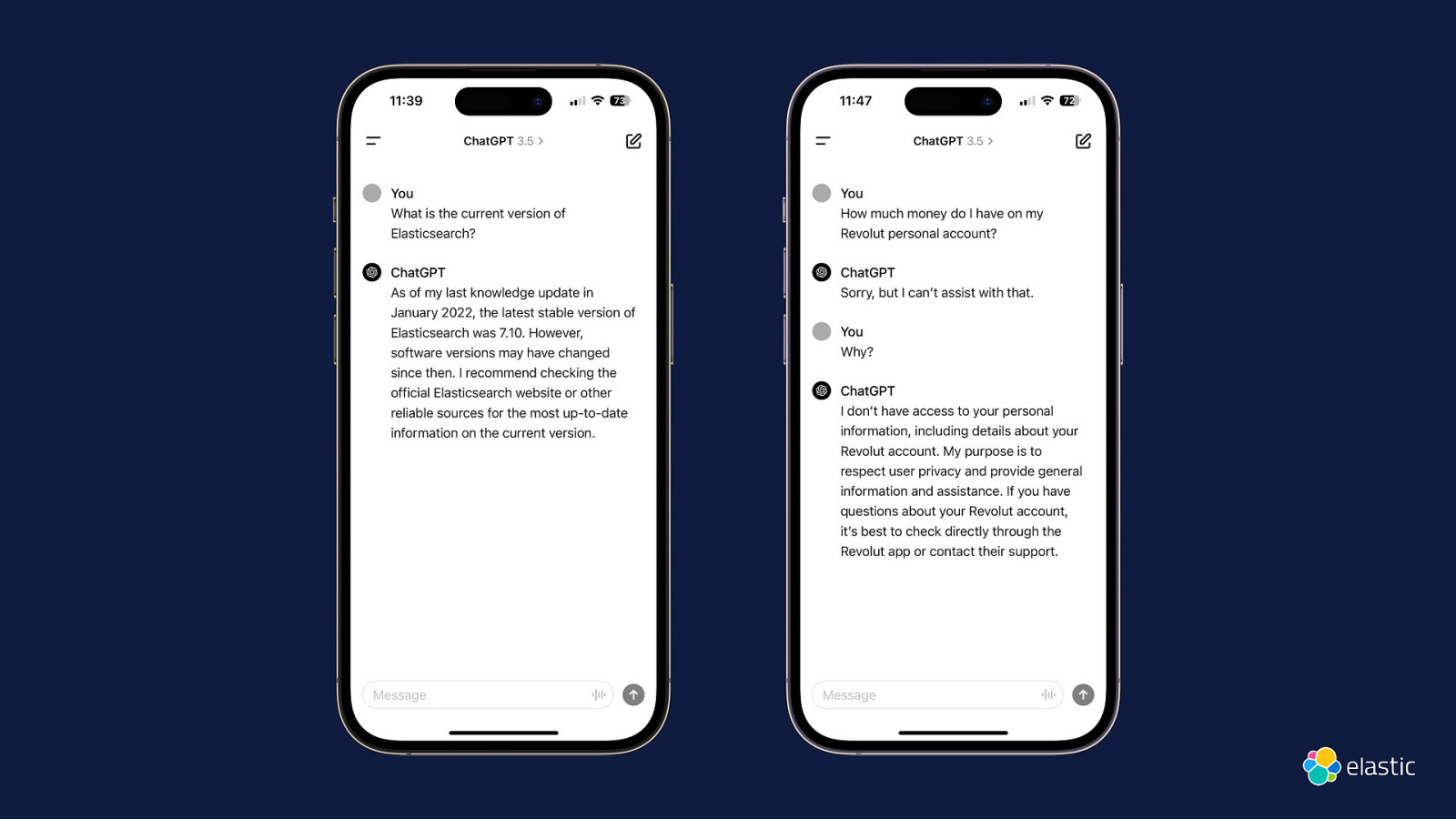
Slide 60
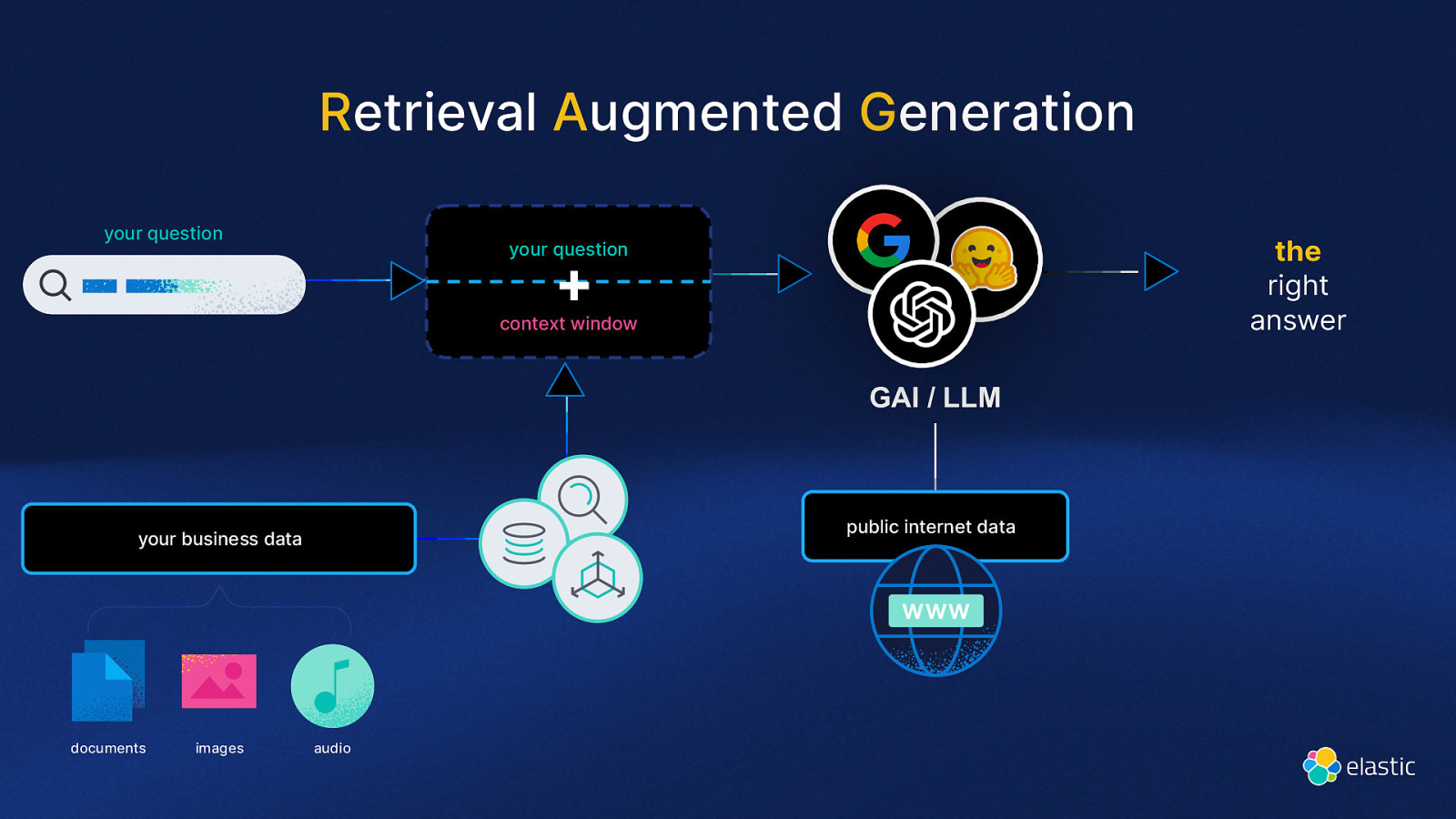
Retrieval Augmented Generation your question the right answer your question + context window GAI / LLM public internet data your business data documents images audio
Slide 61

Demo Elastic Playground
Slide 62
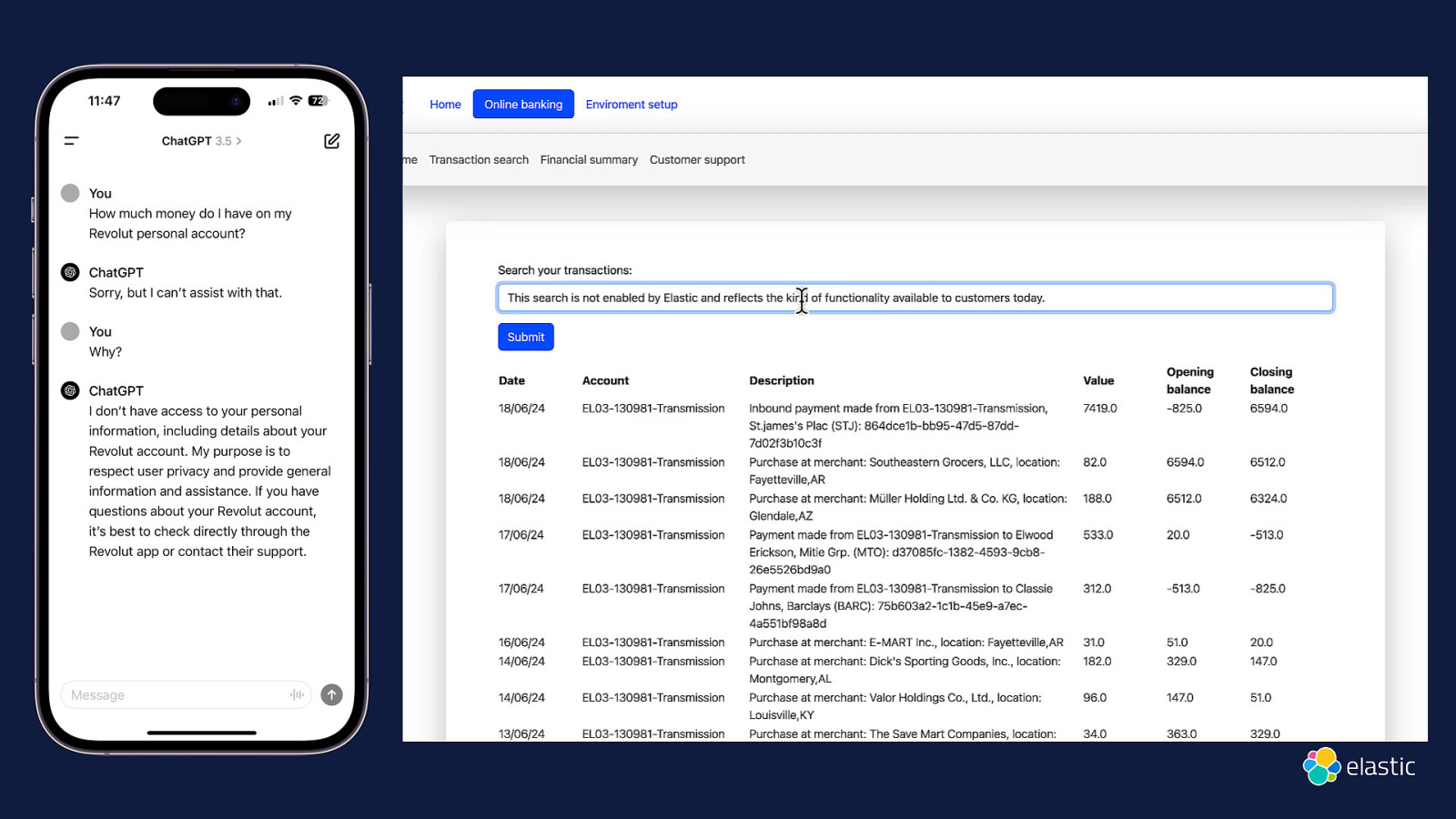
Slide 63

Conclusion
Slide 64

Making it easier PUT /_inference/text_embedding/e5-small-multilingual { “service”: “elasticsearch”, “service_settings”: { “num_allocations”: 1, “num_threads”: 1, “model_id”: “.multilingual-e5-small_linux-x86_64” } } 8. 14
Slide 65

- 14 Making it easier PUT semantic-starwars { “mappings”: { “properties”: { “quote”: { “type”: “text”, “analyzer”: “my_analyzer” }, “quote_e5” : { “type” : “dense_vector” }}}} POST semantic-starwars/_doc { “quote”: “These are <em>not</em> the droids you are looking for.”, “quote_e5”: [ 0.5, 10, 6, …] } GET semantic-starwars/_search { “query”: { “knn”: { “field”: “quote_e5” “k” : 10, “num_candidates”: 100, “query_vector_builder”: { “text_embedding”: { “model_id”: “e5-small-multilingual”, “model_text”: “search for an android” }}}}}
Slide 66
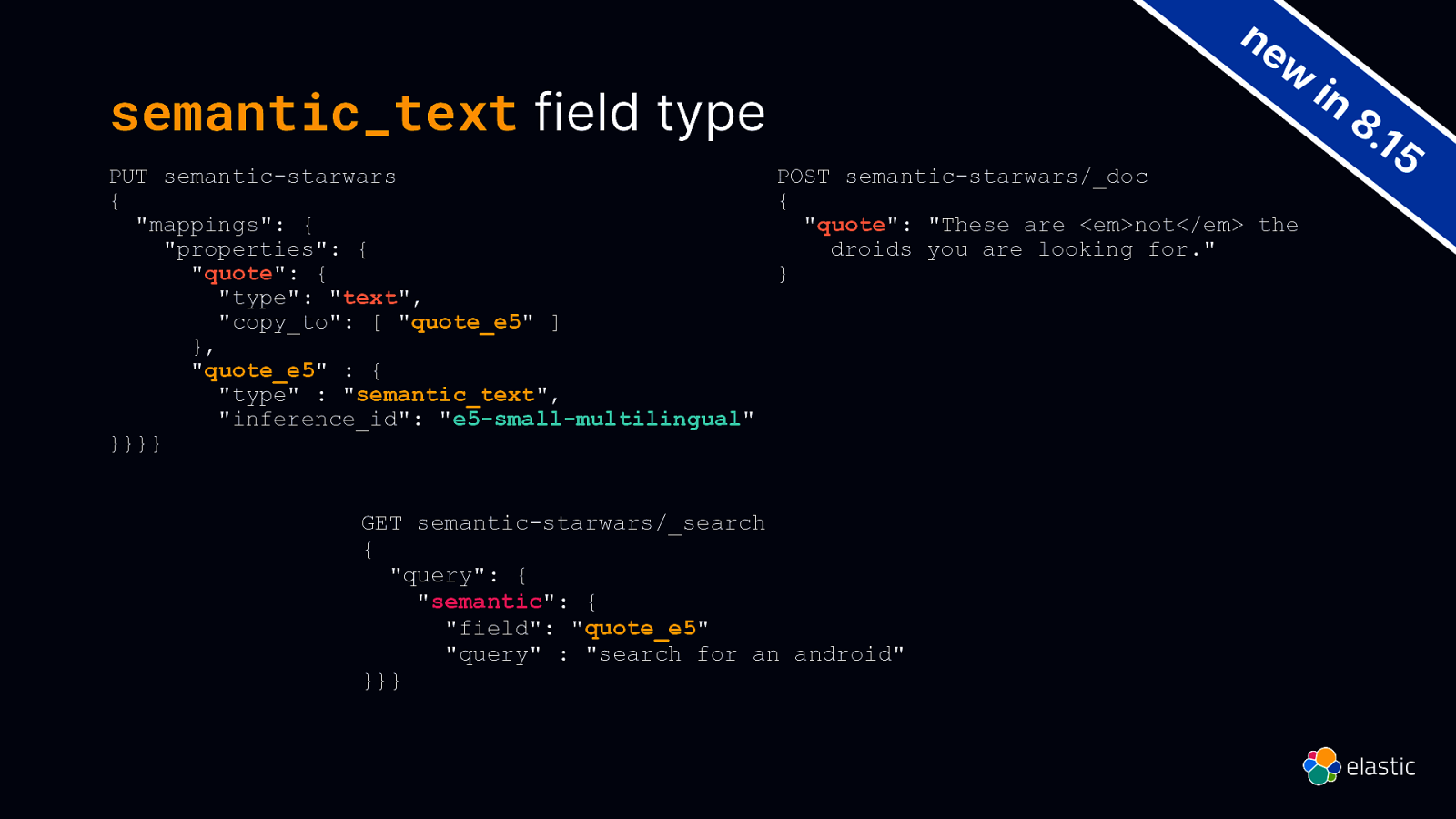
semantic_text field type ne w PUT semantic-starwars POST semantic-starwars/_doc { { “mappings”: { “quote”: “These are <em>not</em> the “properties”: { droids you are looking for.” “quote”: { } “type”: “text”, “copy_to”: [ “quote_e5” ] }, “quote_e5” : { “type” : “semantic_text”, “inference_id”: “e5-small-multilingual” }}}} GET semantic-starwars/_search { “query”: { “semantic”: { “field”: “quote_e5” “query” : “search for an android” }}} in 8. 15
Slide 67
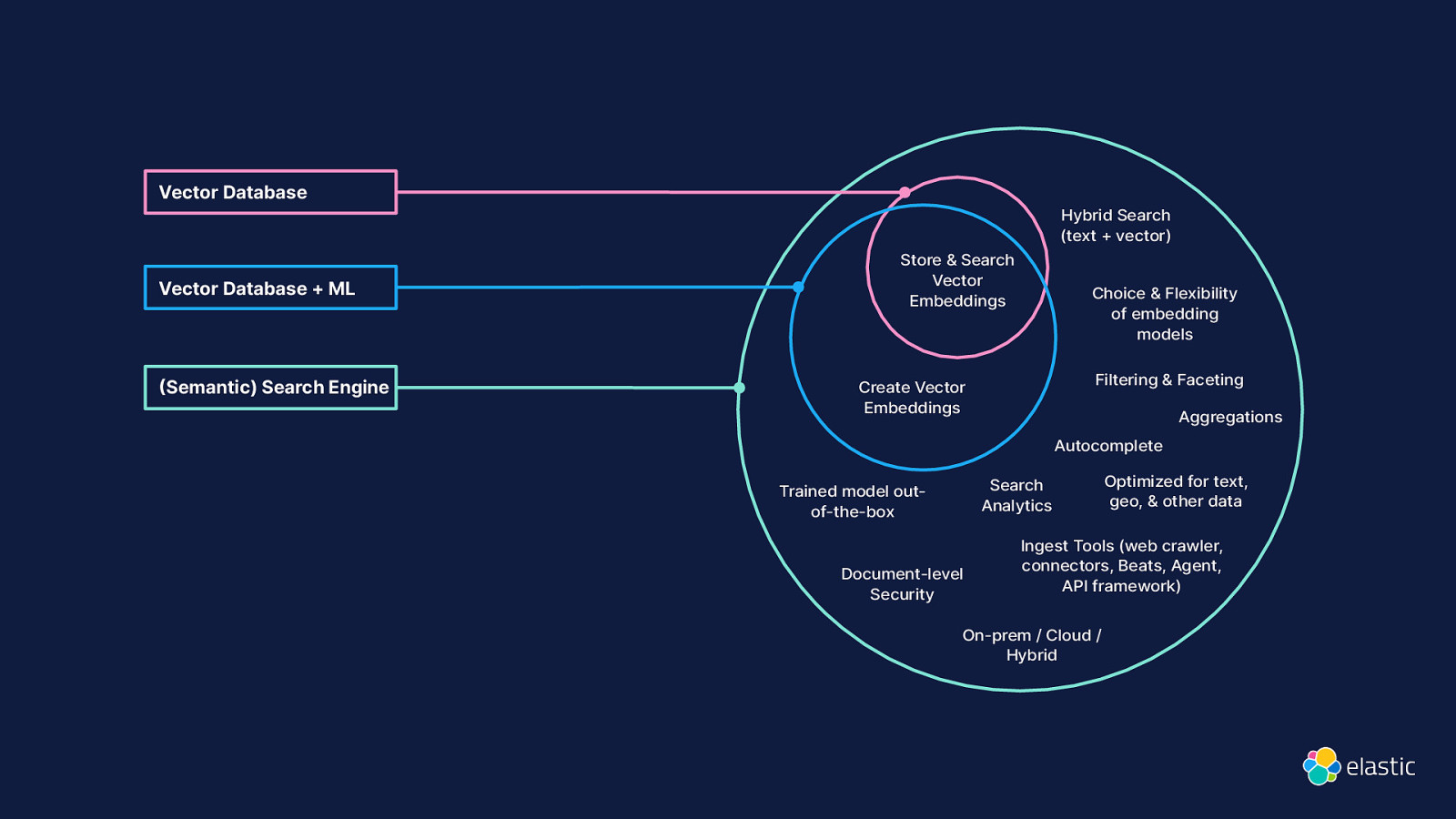
Vector Database Vector Database + ML Semantic) Search Engine Hybrid Search (text + vector) Store & Search Vector Embeddings Choice & Flexibility of embedding models Filtering & Faceting Create Vector Embeddings Aggregations Autocomplete Search Analytics Trained model outof-the-box Document-level Security Optimized for text, geo, & other data Ingest Tools (web crawler, connectors, Beats, Agent, API framework) On-prem / Cloud / Hybrid
Slide 68

Elasticsearch You Know, for Semantic Search
Slide 69

Search & AI a new era David Pilato | @dadoonet