Indexing your office documents with Elastic and FSCrawler David Pilato Developer | Evangelist, Community @dadoonet
Slide 1

Slide 2
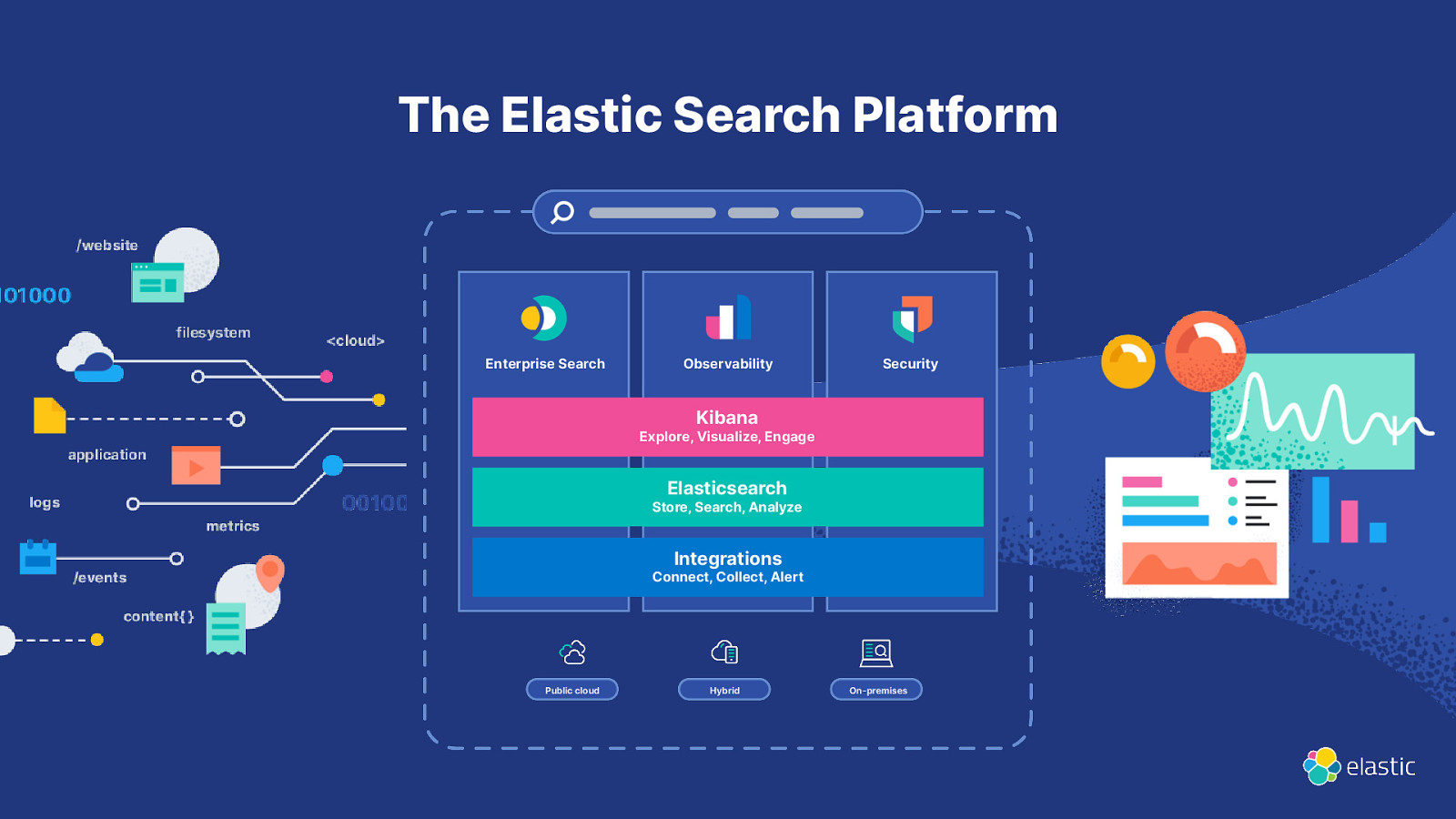
The Elastic Search Platform Enterprise Search Observability Security Kibana Explore, Visualize, Engage Elasticsearch Store, Search, Analyze Integrations Connect, Collect, Alert Public cloud Hybrid On-premises
Slide 3

Slide 4
Slide 5

Parsing a stream and getting content and metadata static void extractTextAndMetadata(InputStream stream) throws Exception { BodyContentHandler handler = new BodyContentHandler(); Metadata metadata = new Metadata(); try (stream) { new DefaultParser().parse(stream, handler, metadata, new ParseContext()); String extractedText = handler.toString(); String title = metadata.get(TikaCoreProperties.TITLE); String keywords = metadata.get(TikaCoreProperties.KEYWORDS); String author = metadata.get(TikaCoreProperties.CREATOR); } }
Slide 6

ingest-attachment plugin extracting from BASE64 or CBOR 6
Slide 7
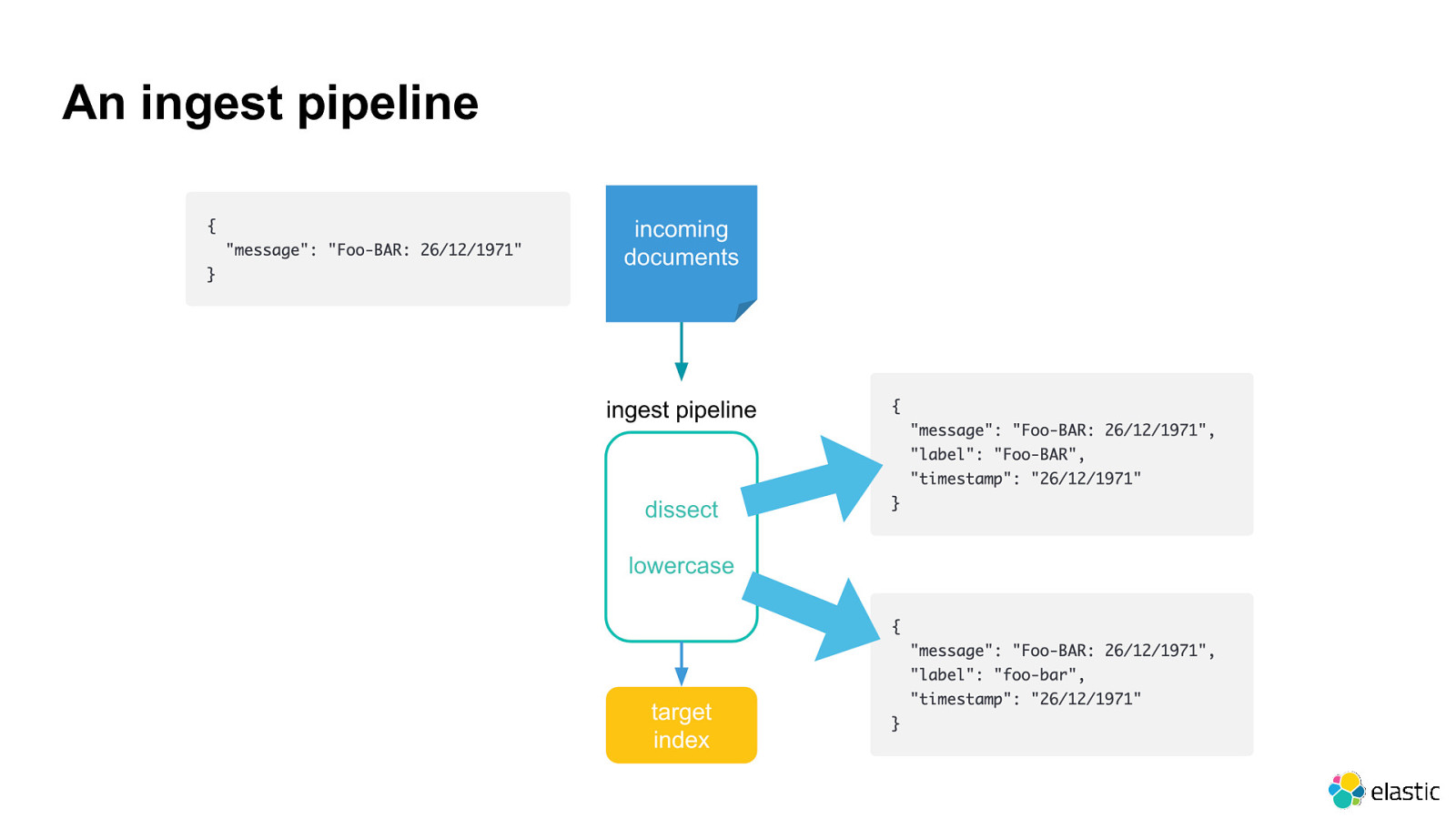
An ingest pipeline
Slide 8

ingest-attachment processor plugin using Tika behind the scene
Slide 9

Demo https://cloud.elastic.co 9
Slide 10

FSCrawler You know, for files… 10
Slide 11
Slide 12

Disclaimer This project is a community project. It is not officially supported by Elastic. Support is only provided by FSCrawler community on discuss and stackoverflow. http://discuss.elastic.co/ https://stackoverflow.com/questions/tagged/fscrawler
Slide 13
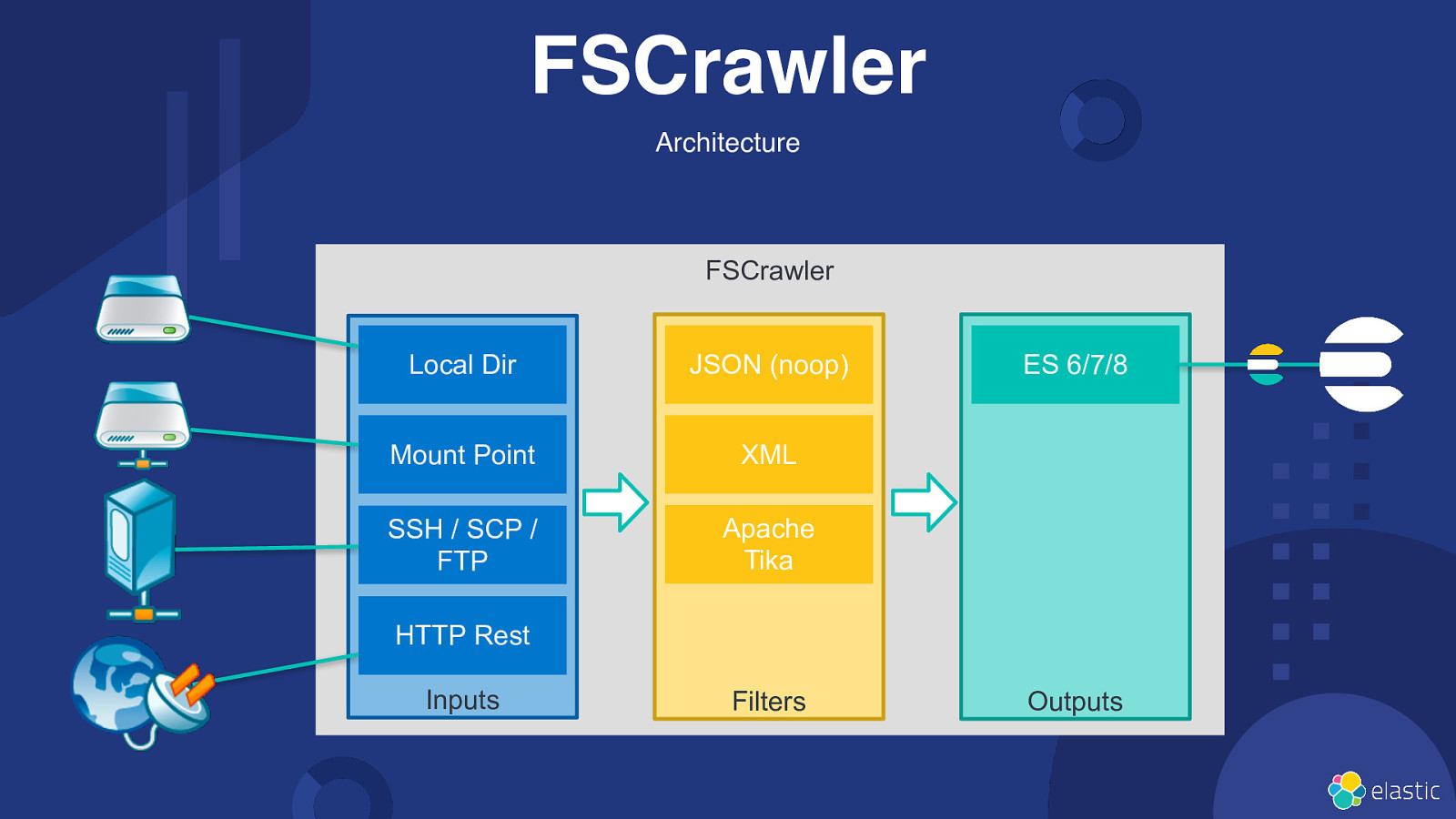
FSCrawler Architecture FSCrawler Local Dir JSON (noop) Mount Point XML SSH / SCP / FTP Apache Tika ES 6/7/8 HTTP Rest Inputs Filters Outputs
Slide 14

FSCrawler Key Features • • • Much more formats than ingest attachment plugin OCR (Tesseract) Much more metadata than ingest attachment plugin (See https://fscrawler.readthedocs.io/en/latest/admin/fs/elasticsearch.html#generated-fields) • Extraction of non standard metadata
Slide 15

Documentation • • • • https://fscrawler.readthedocs.io/ https://fscrawler.readthedocs.io/en/latest/user/tutorial.html https://fscrawler.readthedocs.io/en/latest/user/formats.html https://fscrawler.readthedocs.io/en/latest/admin/fs/index.html https://fscrawler.readthedocs.io/en/latest/
Slide 16

Demo https://cloud.elastic.co 16
Slide 17

FSCrawler even better with a UI 17
Slide 18
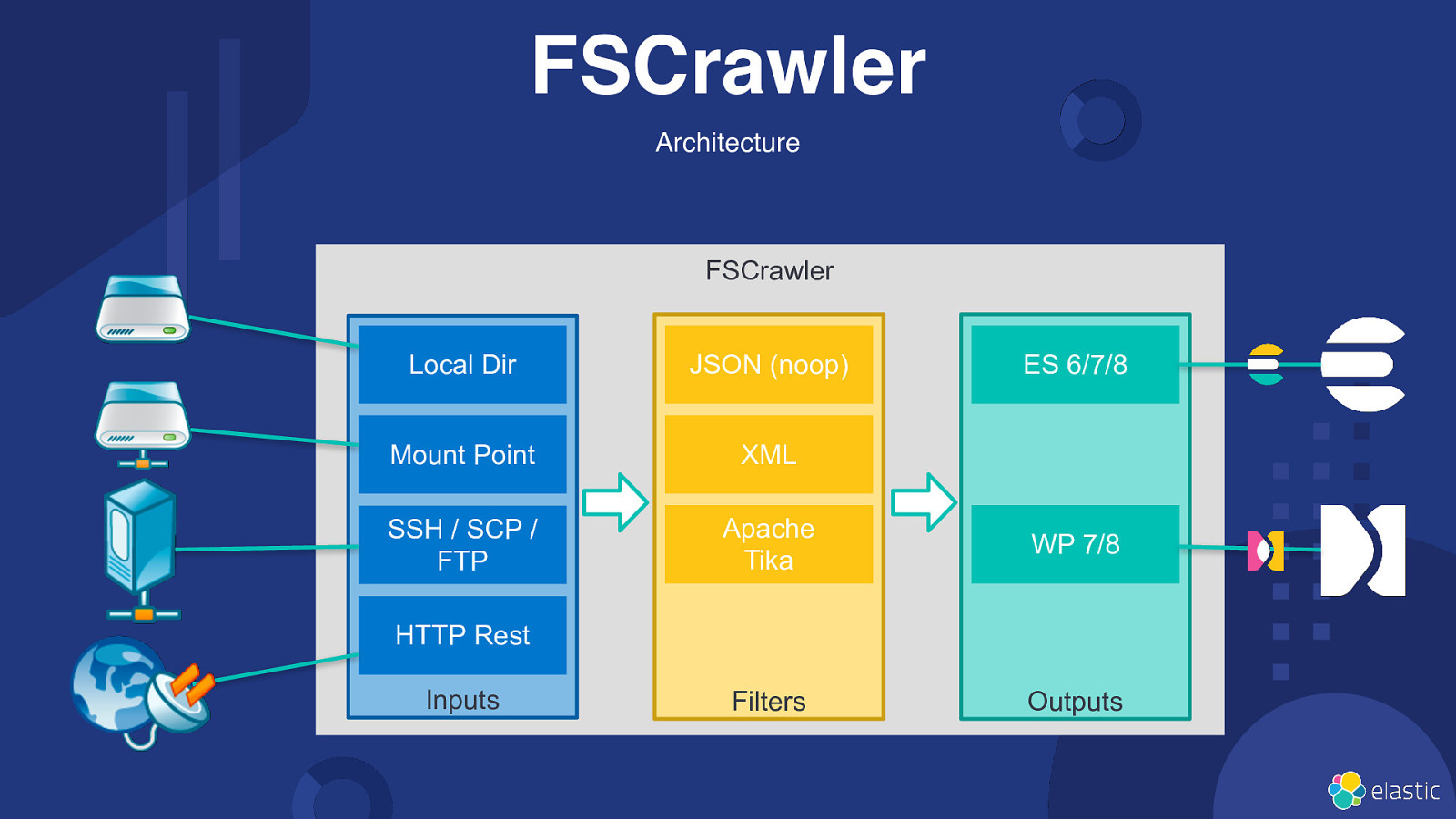
FSCrawler Architecture FSCrawler Local Dir JSON (noop) Mount Point XML SSH / SCP / FTP Apache Tika WP 7/8 Filters Outputs ES 6/7/8 HTTP Rest Inputs
Slide 19

Demo https://cloud.elastic.co 19
Slide 20

Be t 8. a 2 Network drives connector package for Enterprise Search https://github.com/elastic/enterprise-search-network-drives-connector/
Slide 21

FSCrawler v3 Roadmap (“It depends”) 21
Slide 22

Extended CLI parameters https://github.com/dadoonet/fscrawler/issues/857 $ bin/fscrawler —input.fs.dir=/path/to/files \ —filter.tika.indexed_chars=100% \ —output.elasticsearch=https://localhost:9200 $ bin/fscrawler —input.fs.dir=/path/to/files \ —filter.tika.lang_detect=true \ —output.wpsearch=https://localhost:3002
Slide 23
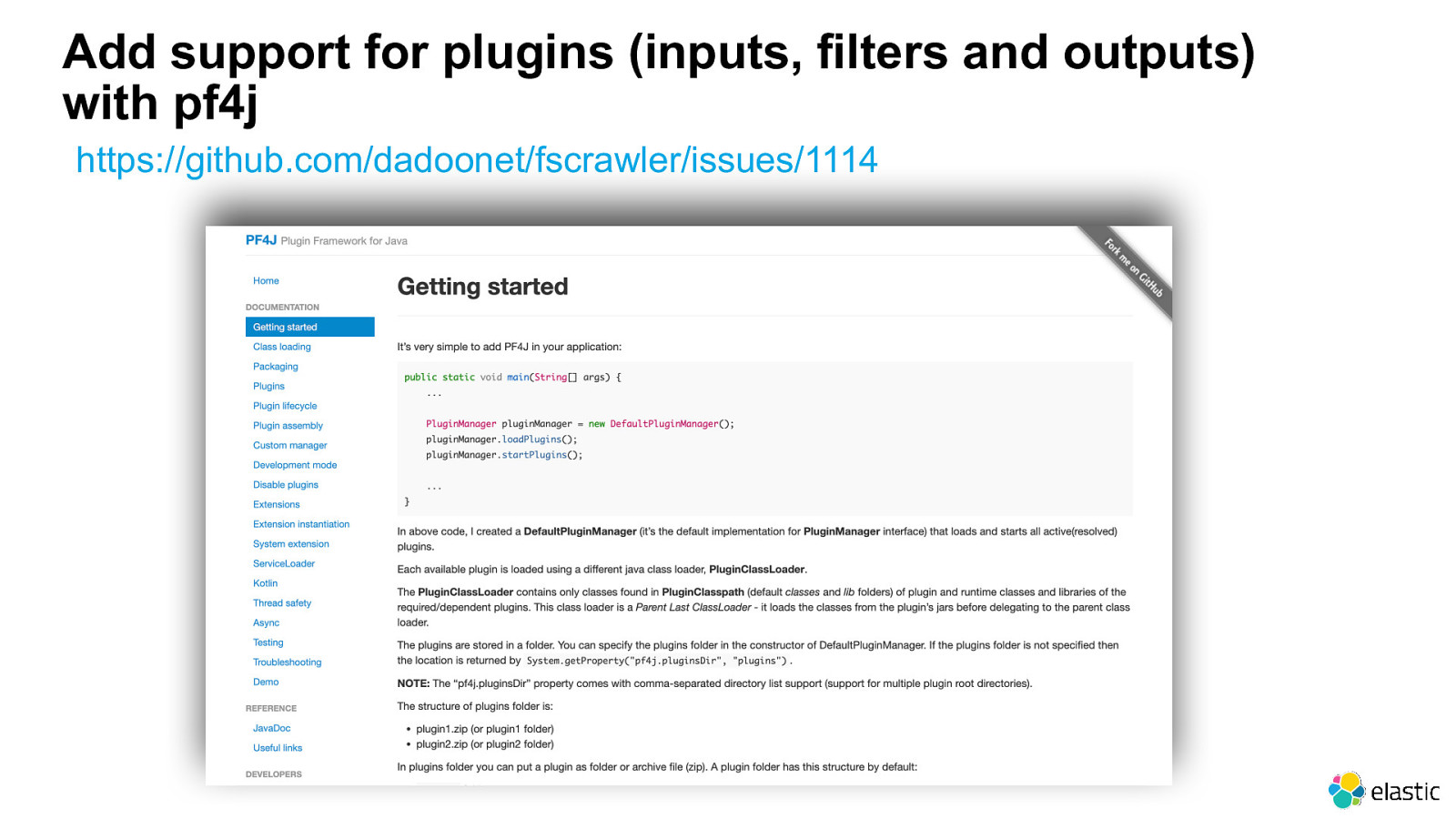
Add support for plugins (inputs, filters and outputs) with pf4j https://github.com/dadoonet/fscrawler/issues/1114
Slide 24
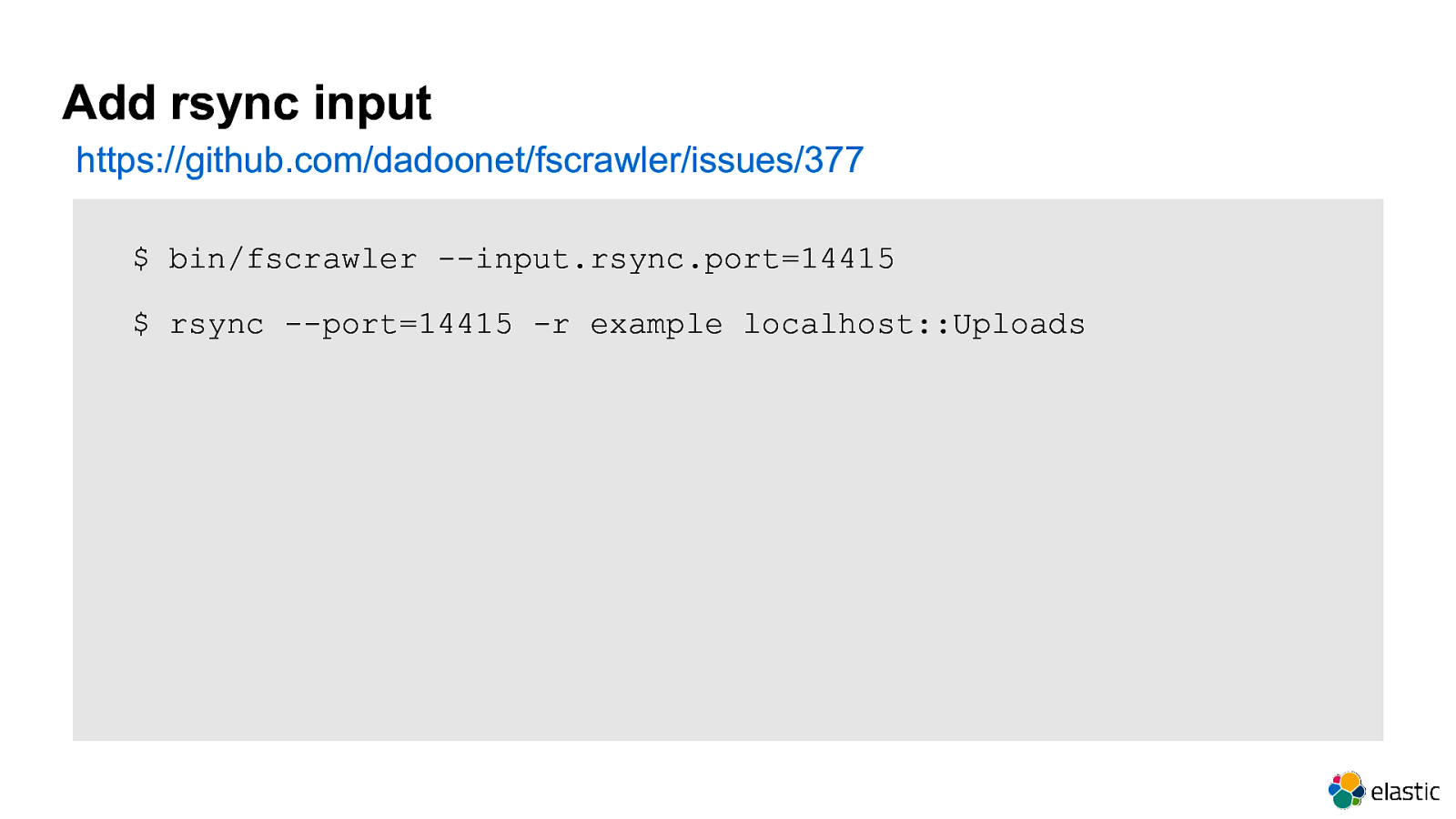
Add rsync input https://github.com/dadoonet/fscrawler/issues/377 $ bin/fscrawler —input.rsync.port=14415 $ rsync —port=14415 -r example localhost::Uploads
Slide 25
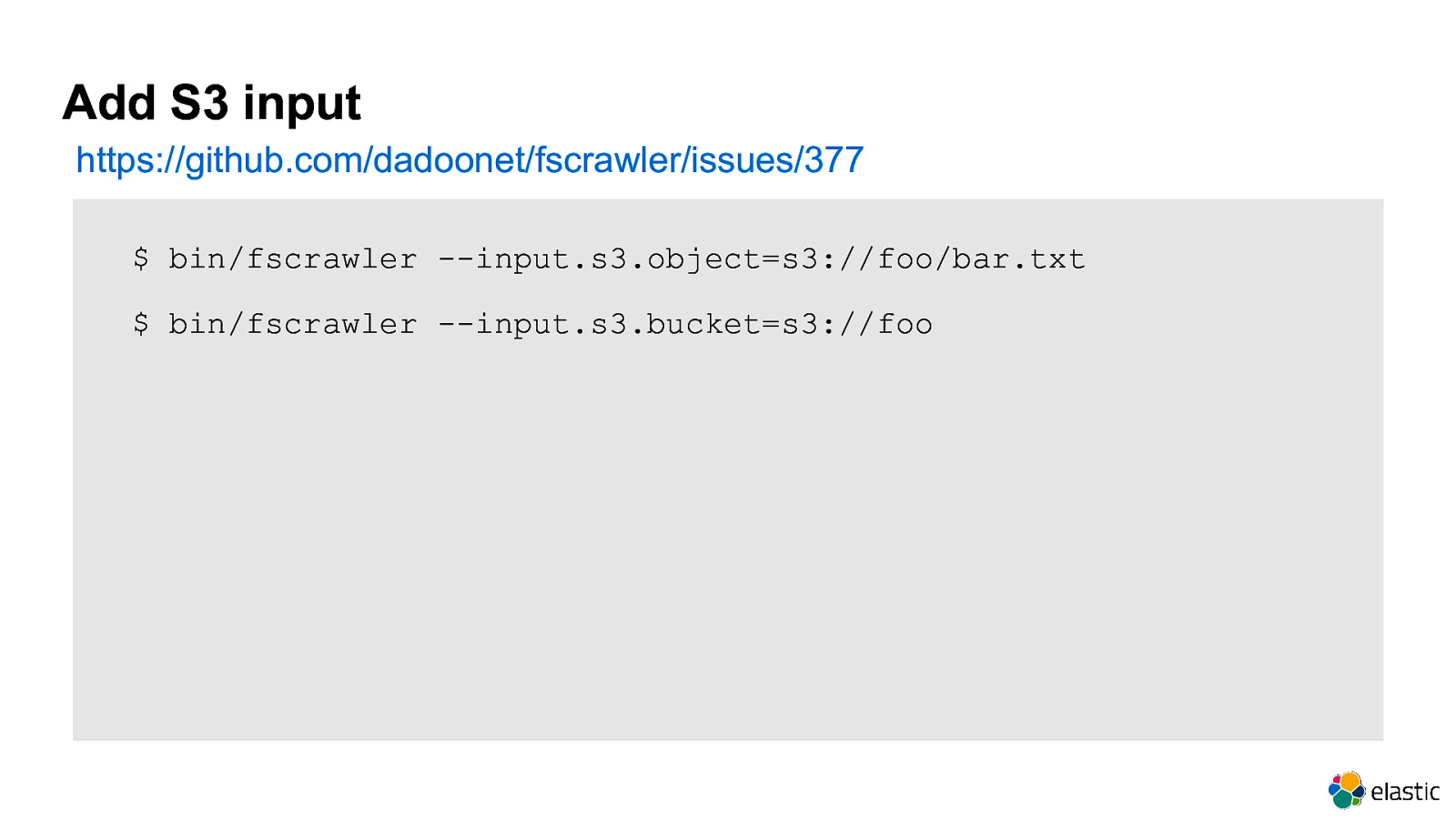
Add S3 input https://github.com/dadoonet/fscrawler/issues/377 $ bin/fscrawler —input.s3.object=s3://foo/bar.txt $ bin/fscrawler —input.s3.bucket=s3://foo
Slide 26
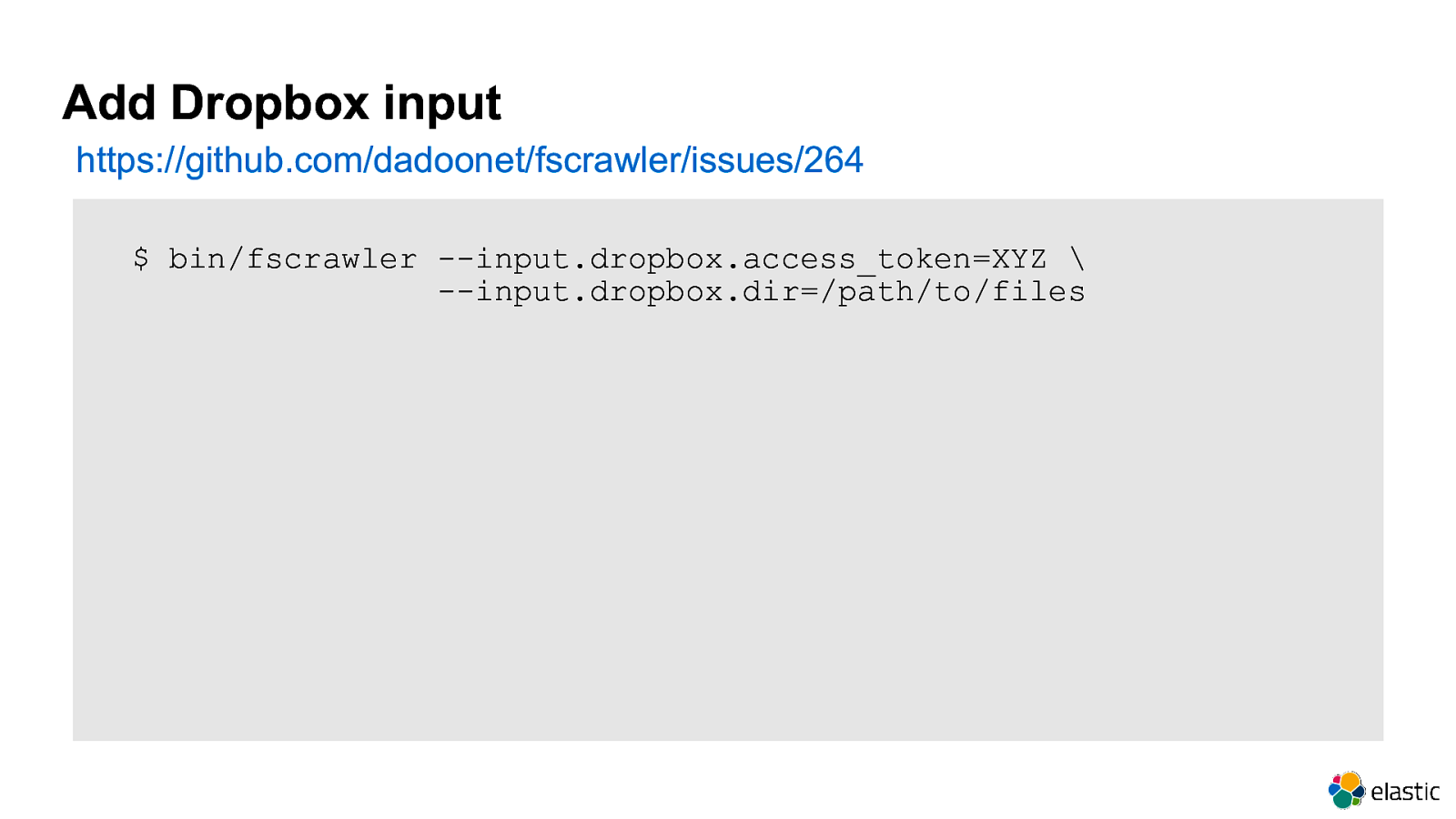
Add Dropbox input https://github.com/dadoonet/fscrawler/issues/264 $ bin/fscrawler —input.dropbox.access_token=XYZ \ —input.dropbox.dir=/path/to/files
Slide 27
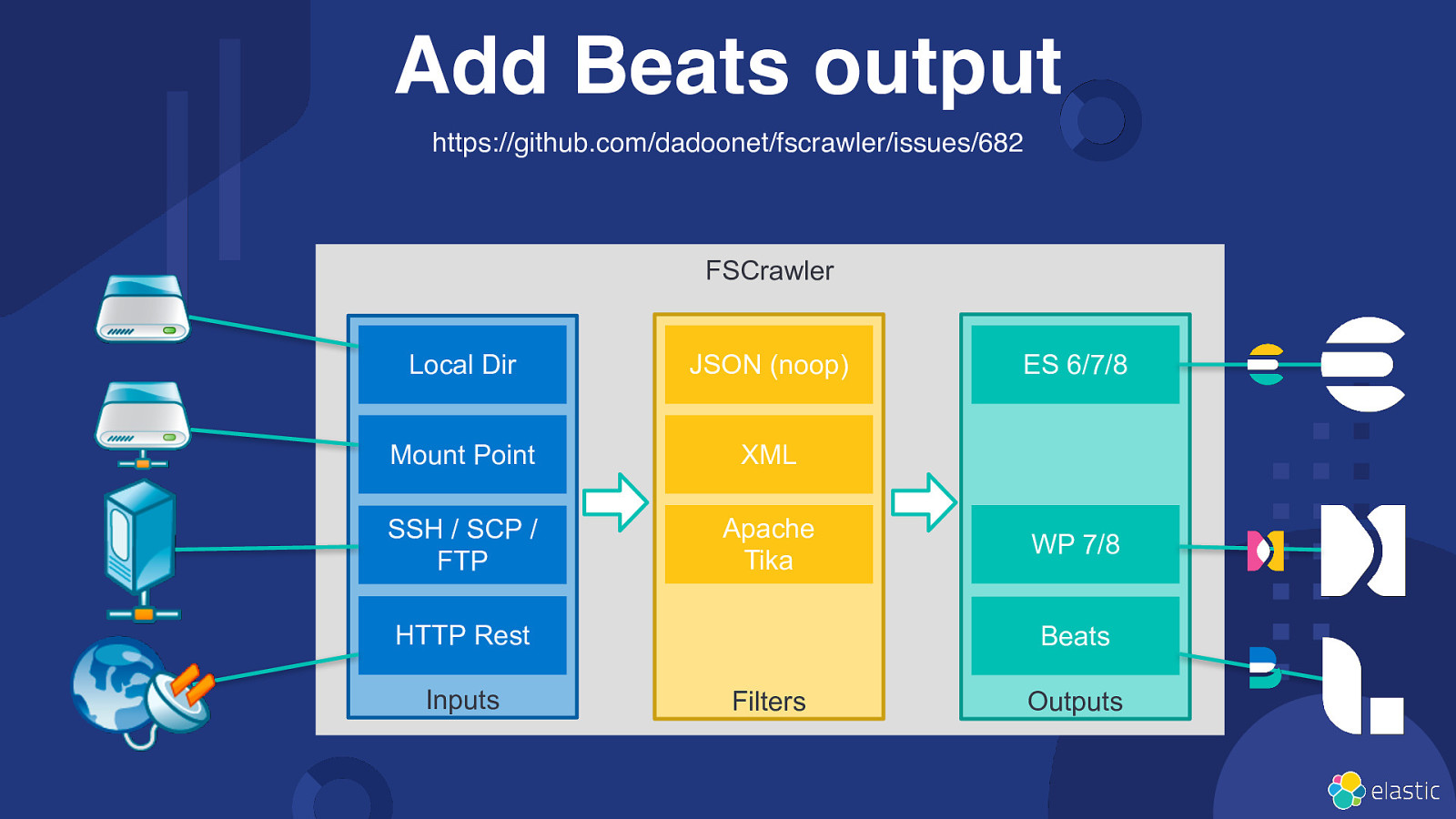
Add Beats output https://github.com/dadoonet/fscrawler/issues/682 FSCrawler Local Dir JSON (noop) Mount Point XML SSH / SCP / FTP Apache Tika HTTP Rest Inputs ES 6/7/8 WP 7/8 Beats Filters Outputs
Slide 28

Add Beats output https://github.com/dadoonet/fscrawler/issues/682 $ bin/logstash -e ’ input { beats { port => 5044 } } output { elasticsearch { hosts => [“https://localhost:9200”] } }’ $ bin/fscrawler —output.beats.url=https://localhost:5044
Slide 29

Manage jobs from the REST Service https://github.com/dadoonet/fscrawler/issues/1549 # Create curl -XPUT http://127.0.0.1:8080/_jobs/my_job -d ‘{ “type”: “fs”, “fs”: { “url”: “file://foo/bar.txt” } } # Start / Stop curl -XPOST http://127.0.0.1:8080/_jobs/my_job/_start curl -XPOST http://127.0.0.1:8080/_jobs/my_job/_stop # Job info and status curl -XGET http://127.0.0.1:8080/_jobs/my_job # Remove the job curl -XDELETE http://127.0.0.1:8080/_jobs/my_job
Slide 30
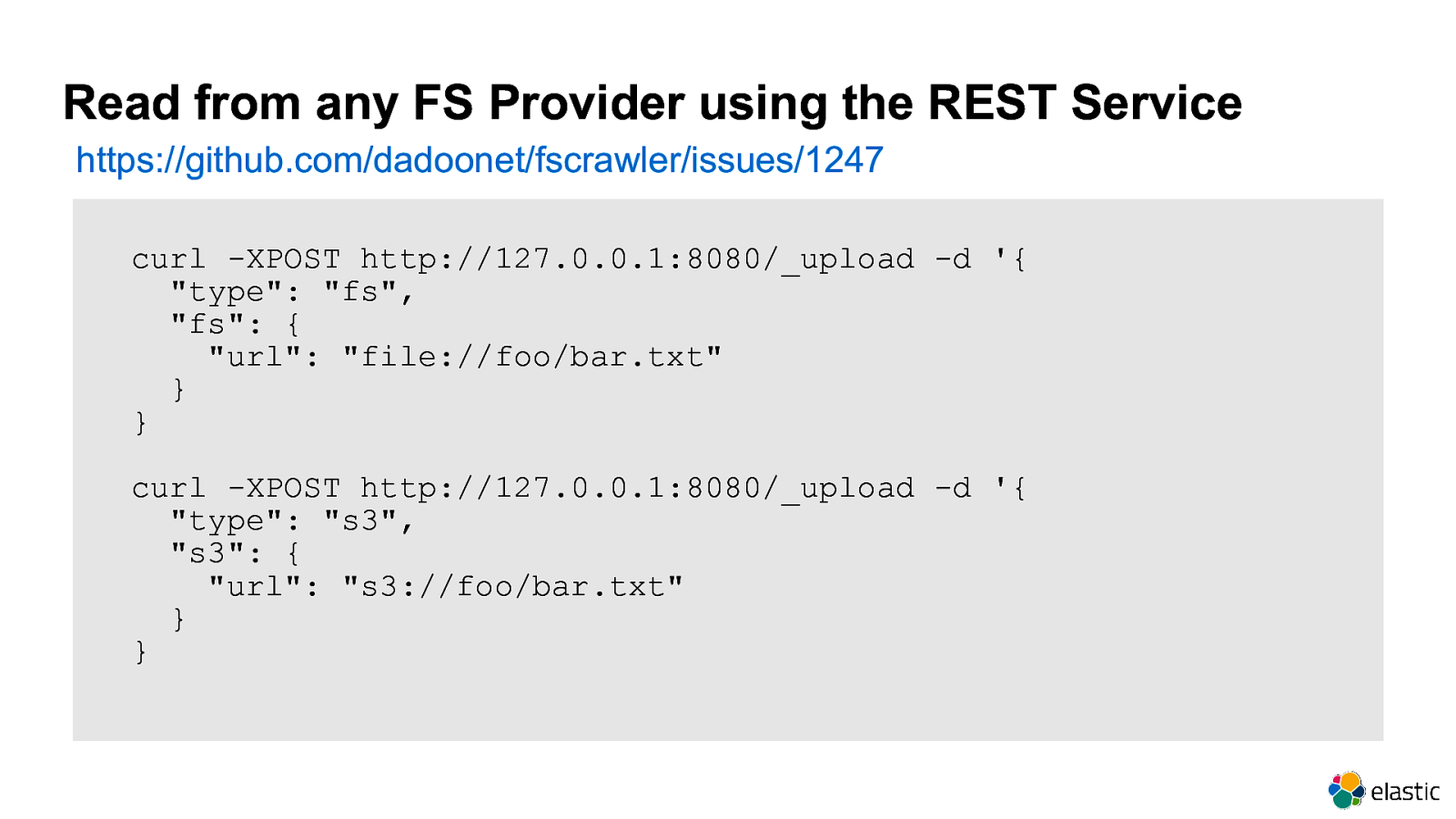
Read from any FS Provider using the REST Service https://github.com/dadoonet/fscrawler/issues/1247 curl -XPOST http://127.0.0.1:8080/_upload -d ‘{ “type”: “fs”, “fs”: { “url”: “file://foo/bar.txt” } } curl -XPOST http://127.0.0.1:8080/_upload -d ‘{ “type”: “s3”, “s3”: { “url”: “s3://foo/bar.txt” } }
Slide 31
Other ideas • • • • New local file crawling implementation (WatchService): #399 Store jobs, configurations, status in Elasticsearch: #717 Switch to ECS format for the most common fields: #677 Extract ACL informations: #464 https://fscrawler.readthedocs.io/en/latest/
Slide 32

Thanks! PR are warmly welcomed! https://github.com/dadoonet/fscrawler