Do MORE with StateLESS Elasticsearch Speaker : David Pilato - @dadoonet Special thanks to : Iraklis Psaroudakis - @kherc
Slide 1

Slide 2

Elastic — The Search AI Company Elastic vous aide à transformer les données en réponses, actions et résultats avec Search AI. Fondée en 2012 Plus de 3 000 employés Plus de 40 pays avec des employés
- 5 milliards de téléchargements Utilisé par plus de 54 % des entreprises du Fortune 500 Cotée en bourse sous ESTC au NYSE Données en date de mars 2025 #JugSummerCamp @dadoonet
Slide 3
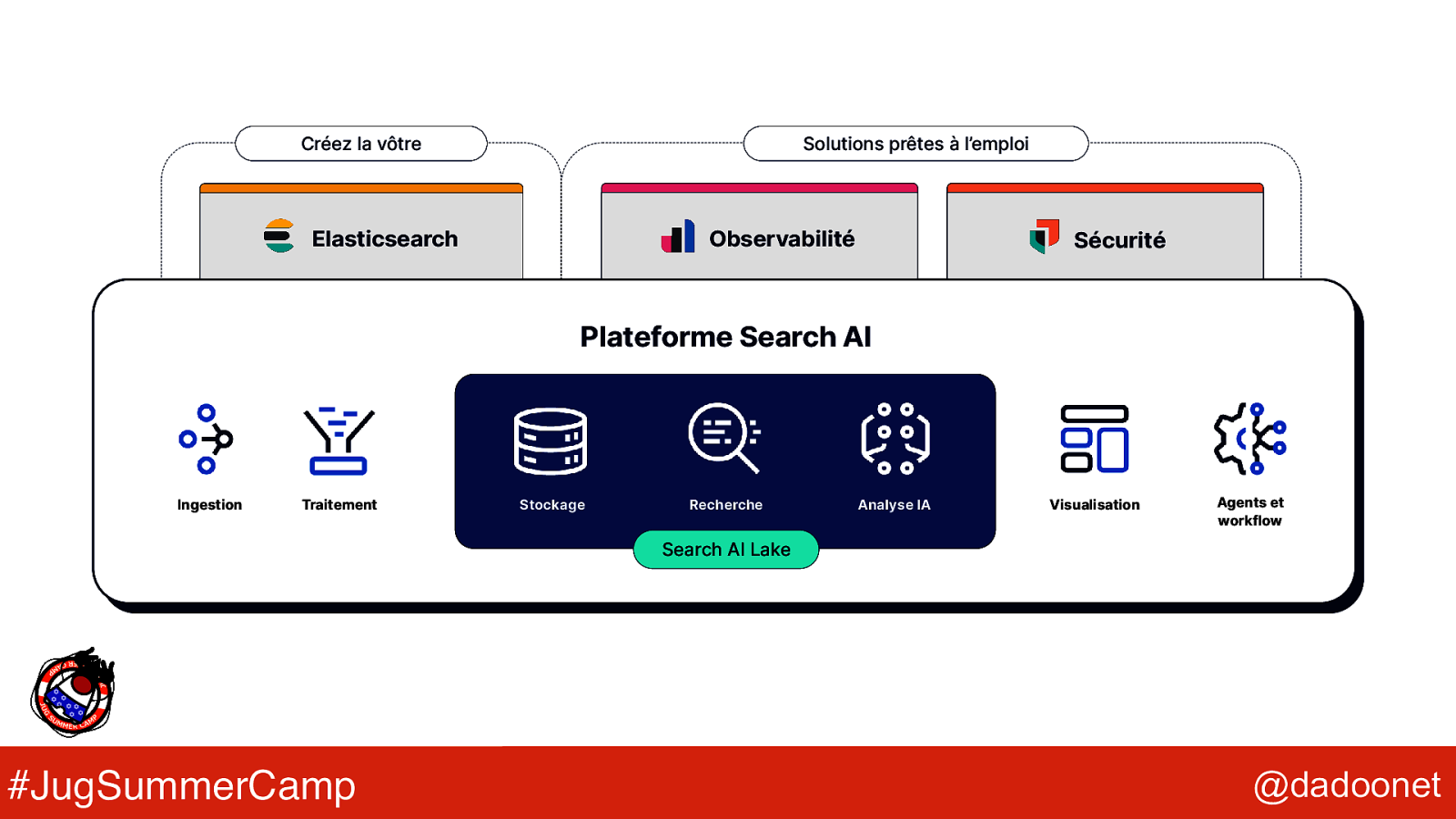
Créez la vôtre Solutions prêtes à l’emploi Observabilité Elasticsearch Sécurité Plateforme Search AI Ingestion Traitement Stockage Recherche Analyse IA Visualisation Agents et workflow Search AI Lake #JugSummerCamp @dadoonet
Slide 4

● Distributed, scalable, highly available, resilient search & analytics engine ● HTTP based JSON interface ● Based on Apache Lucene ● Not only grep or SQL’s LIKE = ‘%quick% ● Ranked results (BM25, recency, popularity), fuzzy matching ● Complex search expressions ● Spelling, Synonyms, Phrases, Stemming ● Timeseries, geospatial ● Vector search, G AI/ML, RAG search apps ) ( #JugSummerCamp github.com/elastic/elasticsearch db-engines.com/en/ranking/search+engine @dadoonet
Slide 5

● ● ● ● ● ● ● ● Cluster Nodes Index Shards Segments Cluster state Data streams Index Lifecycle Management (ILM @dadoonet ) #JugSummerCamp
Slide 6
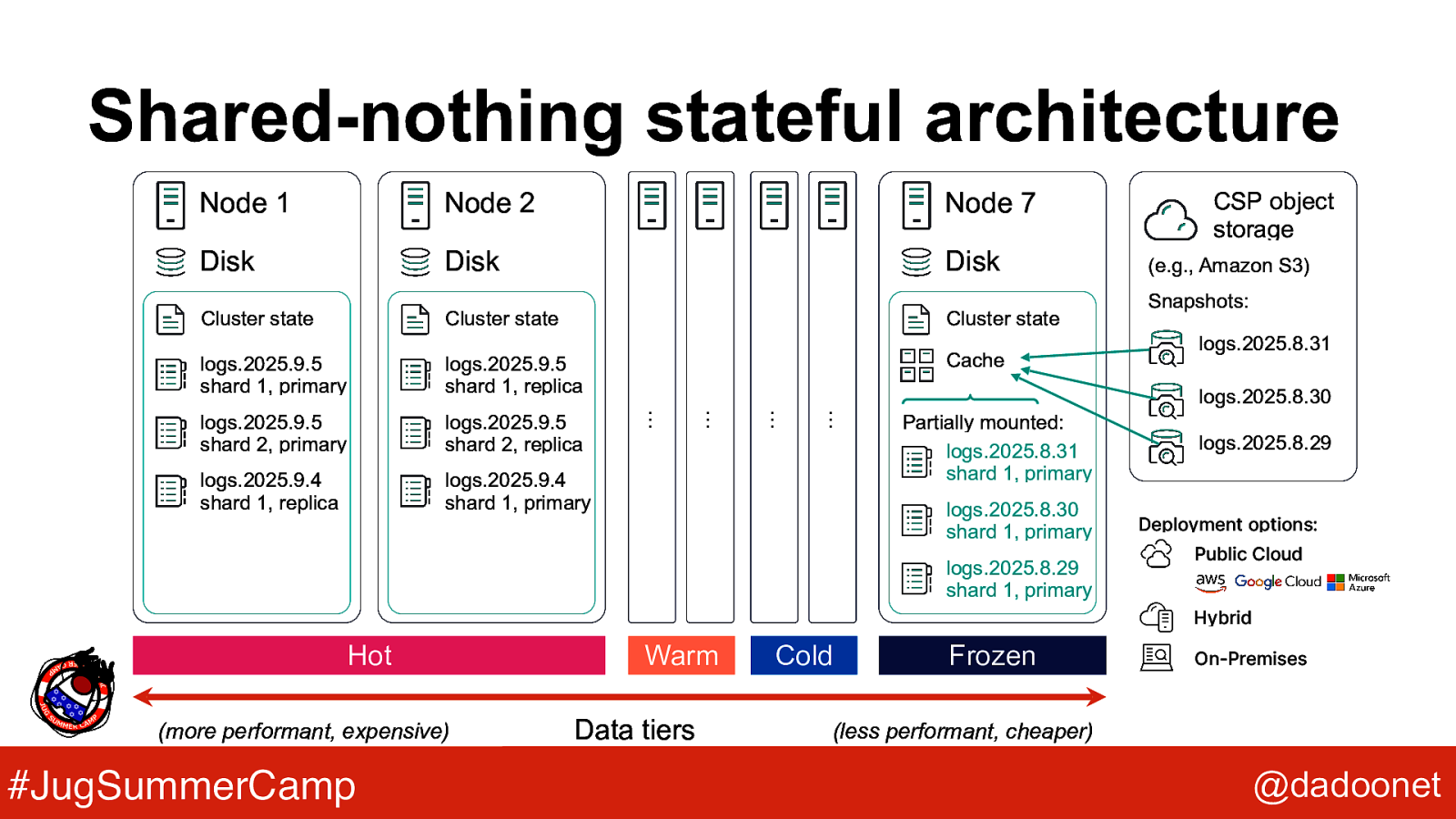
Shared-nothing stateful architecture Node 1 Node 2 Node 7 Disk Disk Disk Cluster state Cluster state Cluster state logs.2025.9.5 shard 1, primary logs.2025.9.5 shard 1, replica Cache logs.2025.9.5 shard 2, primary logs.2025.9.5 shard 2, replica logs.2025.9.4 shard 1, replica logs.2025.9.4 shard 1, primary CSP object storage (e.g., Amazon S3) Snapshots: logs.2025.8.31 … … … … logs.2025.8.30 Partially mounted: logs.2025.8.31 shard 1, primary logs.2025.8.30 shard 1, primary logs.2025.8.29 shard 1, primary logs.2025.8.29 Deployment options: Public Cloud Hybrid Hot (more performant, expensive) #JugSummerCamp Warm Data tiers Cold Frozen On-Premises (less performant, cheaper) @dadoonet
Slide 7

Disadvantages of stateful ● ● ● ● ● User defines cluster (RAM, CPU, disk) CPU & RAM coupled with storage CPU shared by ingestion & search Needs to think of data tiers Adding/removing nodes moves data #JugSummerCamp @dadoonet
Slide 8
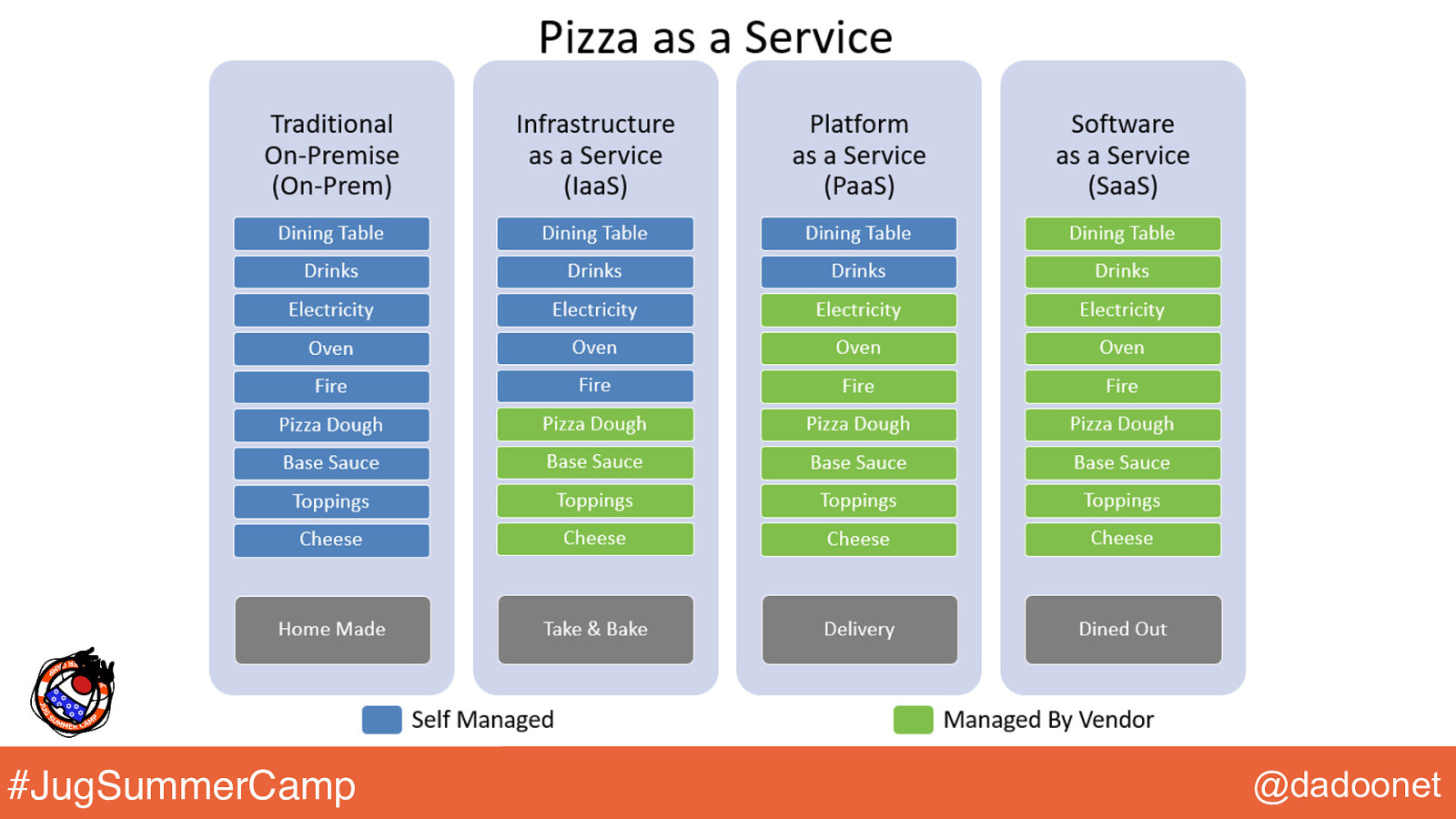
#JugSummerCamp @dadoonet
Slide 9
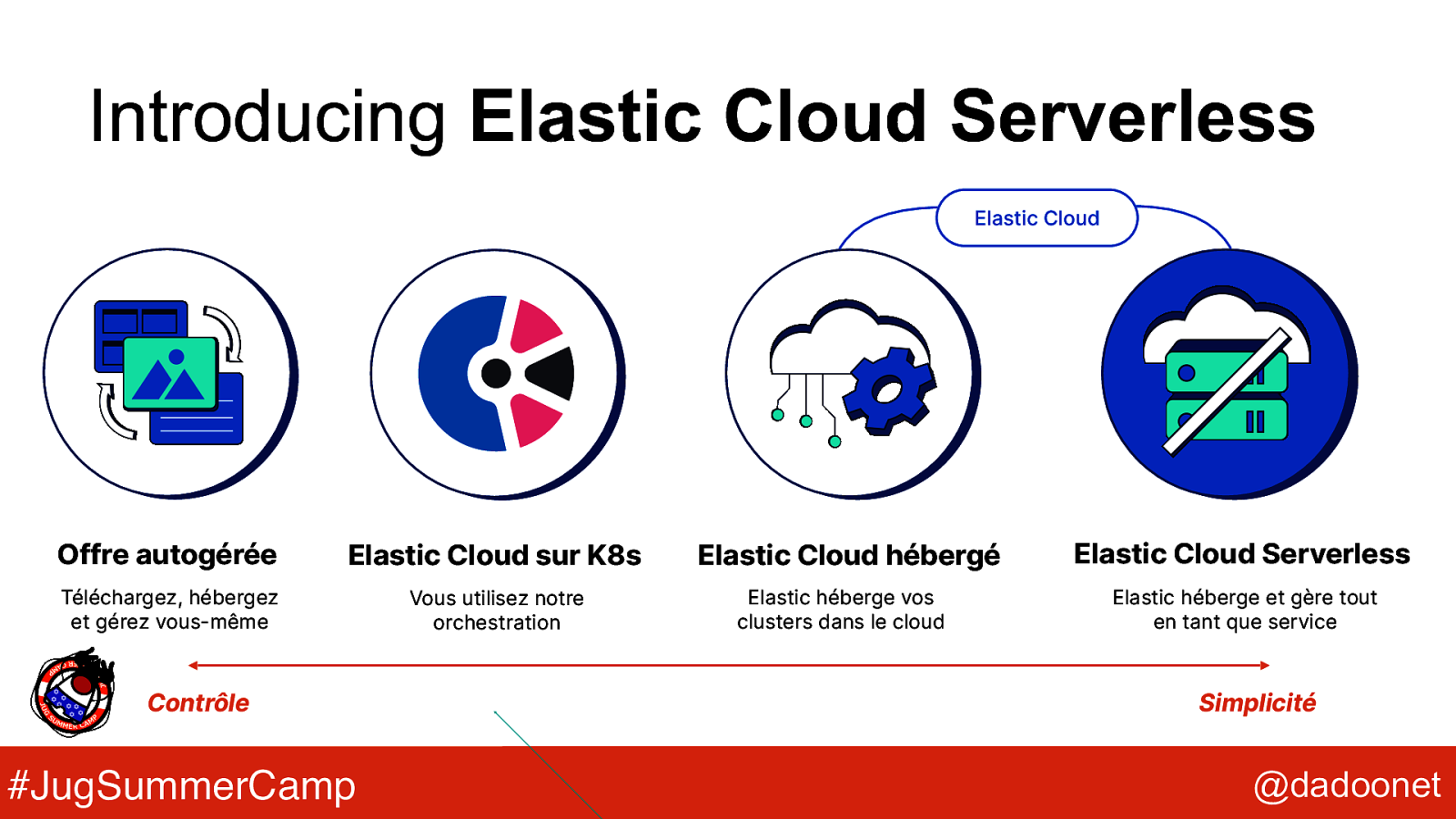
Introducing Elastic Cloud Serverless Elastic Cloud Offre autogérée Elastic Cloud sur K8s Téléchargez, hébergez et gérez vous-même Vous utilisez notre orchestration Contrôle #JugSummerCamp Elastic Cloud hébergé Elastic héberge vos clusters dans le cloud Elastic Cloud Serverless Elastic héberge et gère tout en tant que service Simplicité @dadoonet
Slide 10

Serverless Elasticsearch ● ● ● ● ● SaaS Exploits Cloud Service Provider Stateless: decouples compute from storage Same API as stateful Elasticsearch Pay-as-you-go model (retention, indexing, searching) ● No more cluster specifics, sizing, upgrading, HA ● 2 simplified data tiers: indexing, search #JugSummerCamp @dadoonet
Slide 11
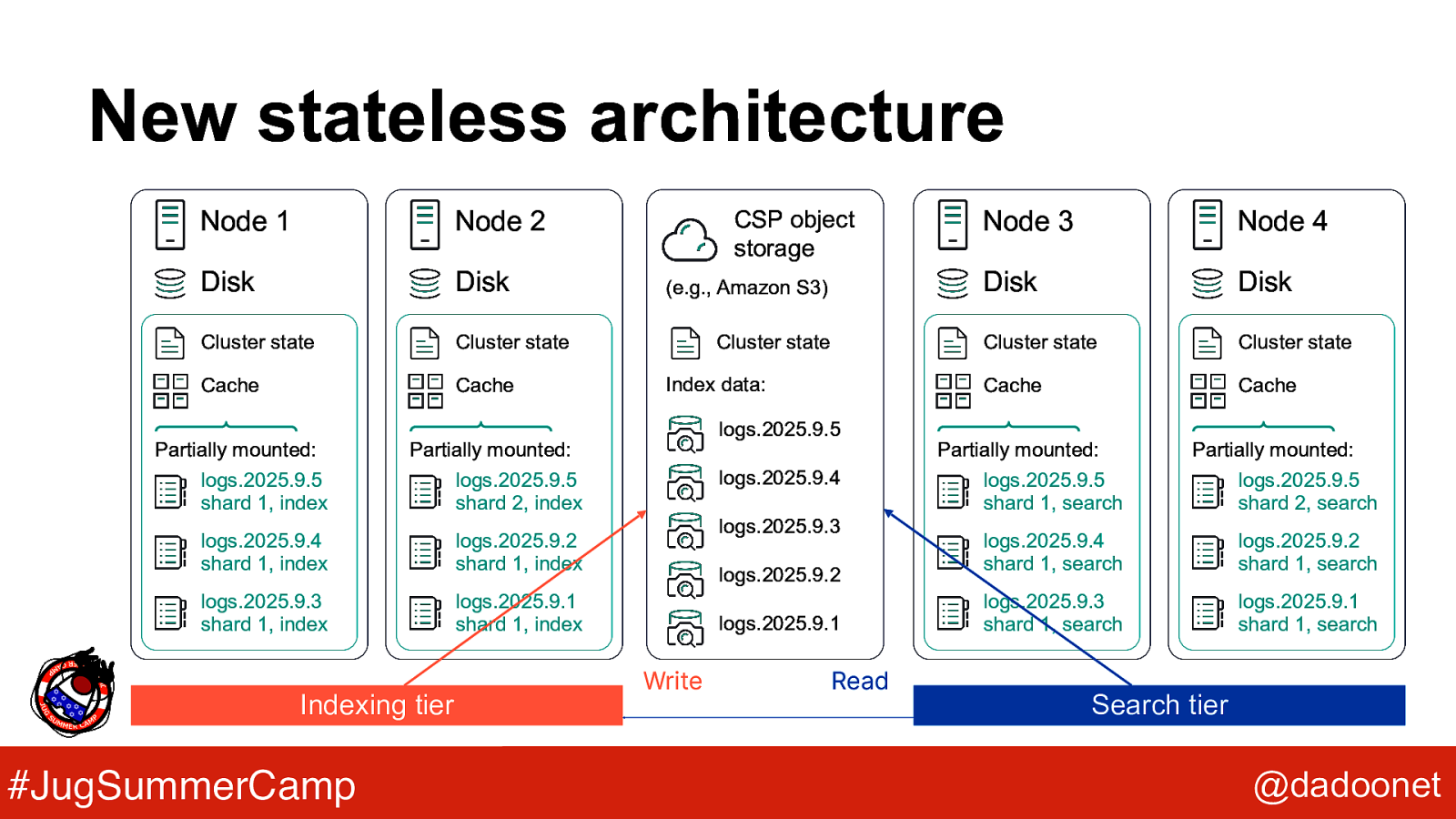
New stateless architecture Node 1 Node 2 Disk Disk Cluster state Cluster state Cache Cache Partially mounted: logs.2025.9.5 shard 1, index Partially mounted: logs.2025.9.5 shard 2, index logs.2025.9.4 shard 1, index logs.2025.9.2 shard 1, index logs.2025.9.3 shard 1, index logs.2025.9.1 shard 1, index Indexing tier #JugSummerCamp CSP object storage (e.g., Amazon S3) Cluster state Index data: logs.2025.9.5 logs.2025.9.4 logs.2025.9.3 logs.2025.9.2 logs.2025.9.1 Write Read Node 3 Node 4 Disk Disk Cluster state Cluster state Cache Cache Partially mounted: logs.2025.9.5 shard 1, search Partially mounted: logs.2025.9.5 shard 2, search logs.2025.9.4 shard 1, search logs.2025.9.2 shard 1, search logs.2025.9.3 shard 1, search logs.2025.9.1 shard 1, search Search tier @dadoonet
Slide 12

Thin shards ● Loaded with metadata until data is indexed/searched ● Indexing generates files, uploads them and deletes them when unused ● Searching loads from object store only the required data into the cache ● Indexing & searching virtually limitless data ● Not dependent on disk, not restricted by disk capacity ● Shard relocation (and recovery) is very fast #JugSummerCamp @dadoonet
Slide 13

Stateful example data inside a shard
Slide 14
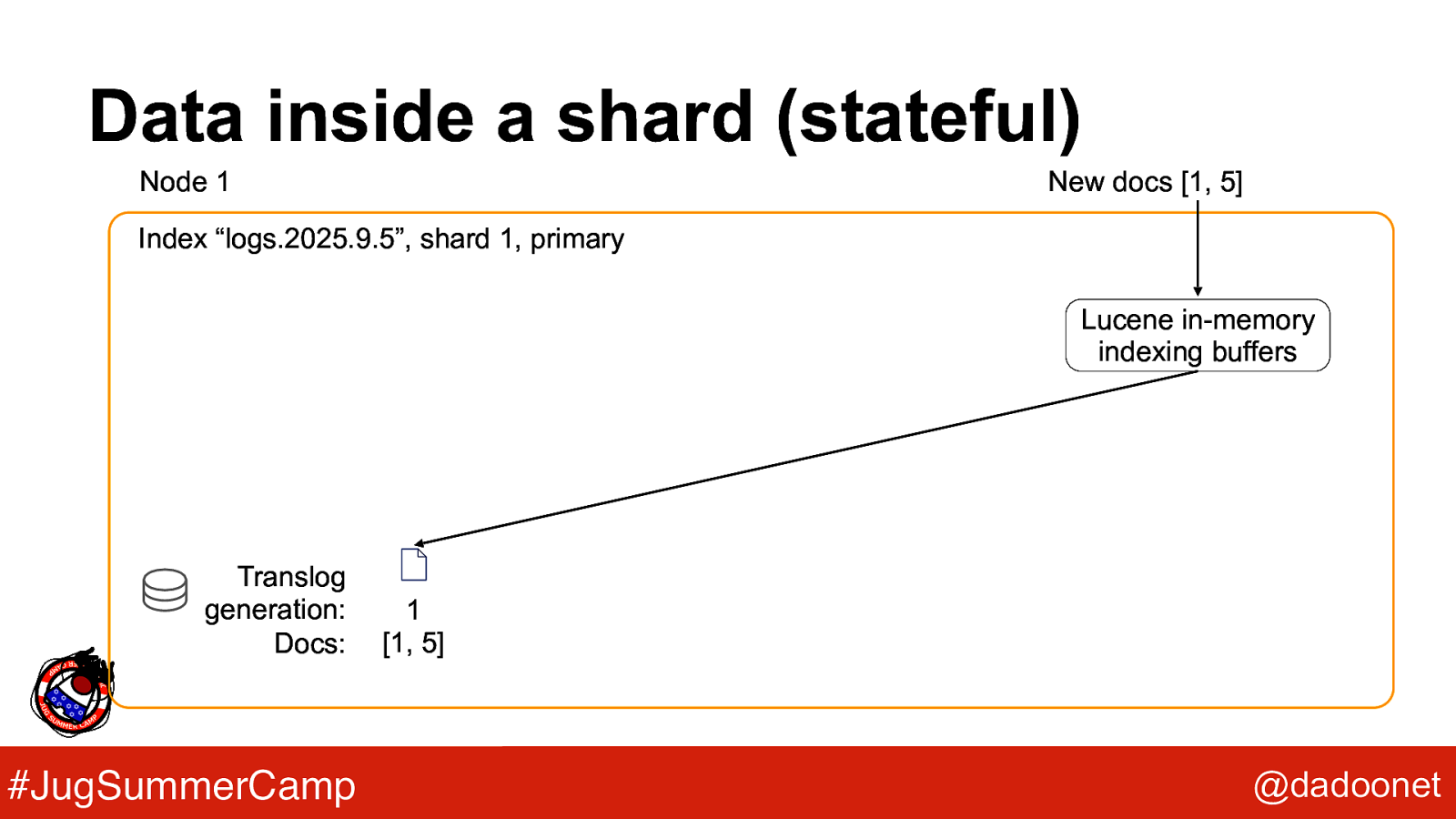
Data inside a shard (stateful) Node 1 New docs [1, 5] Index “logs.2025.9.5”, shard 1, primary Lucene in-memory indexing buffers Translog generation: Docs: #JugSummerCamp 1 [1, 5] @dadoonet
Slide 15
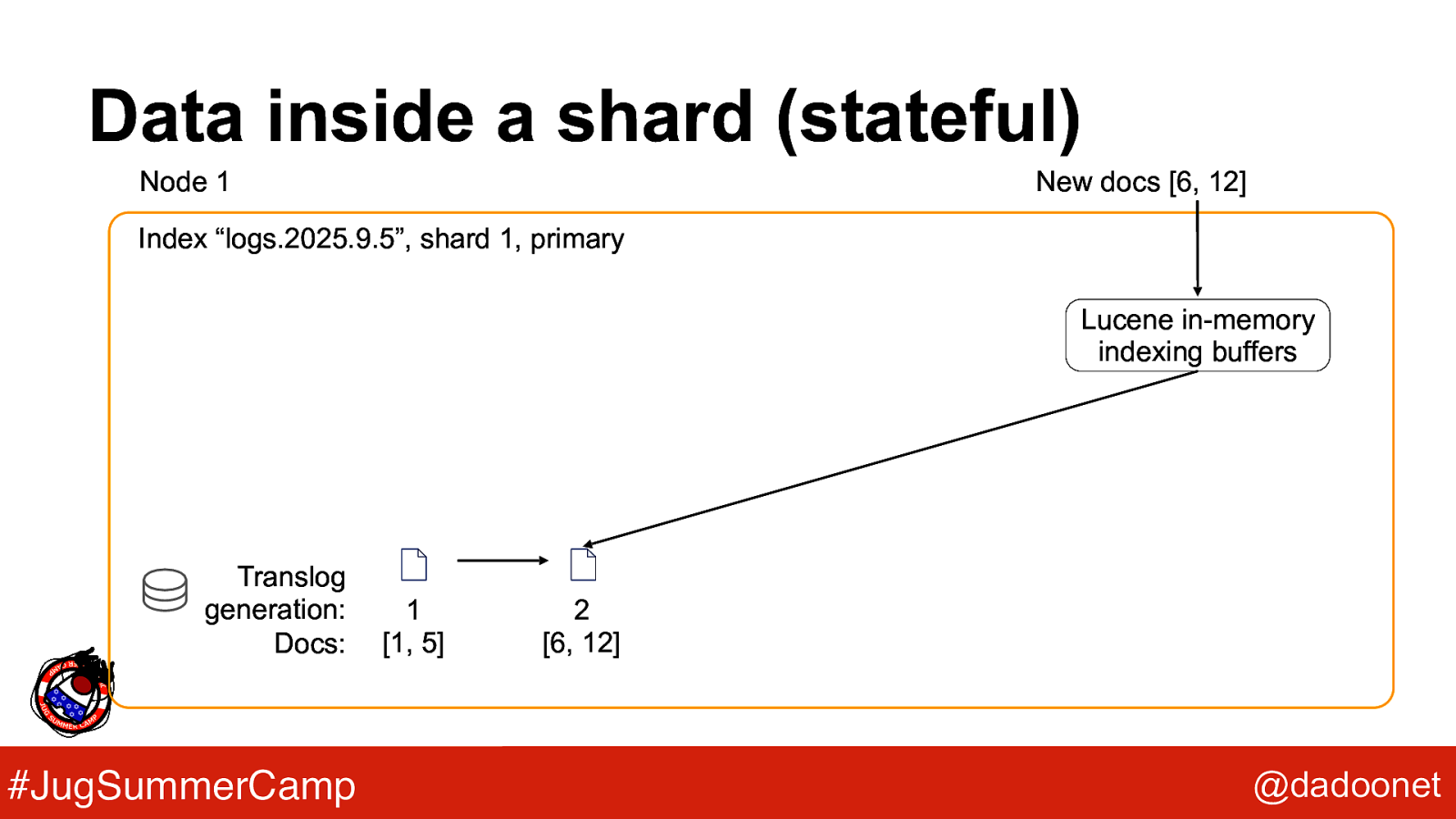
Data inside a shard (stateful) Node 1 New docs [6, 12] Index “logs.2025.9.5”, shard 1, primary Lucene in-memory indexing buffers Translog generation: Docs: #JugSummerCamp 1 [1, 5] 2 [6, 12] @dadoonet
Slide 16

Data inside a shard (stateful) Node 1 Index “logs.2025.9.5”, shard 1, primary refresh Lucene segments generation: Docs: Translog generation: Docs: #JugSummerCamp Lucene in-memory indexing buffers 1 [1, 12] 1 [1, 5] 2 [6, 12] @dadoonet
Slide 17
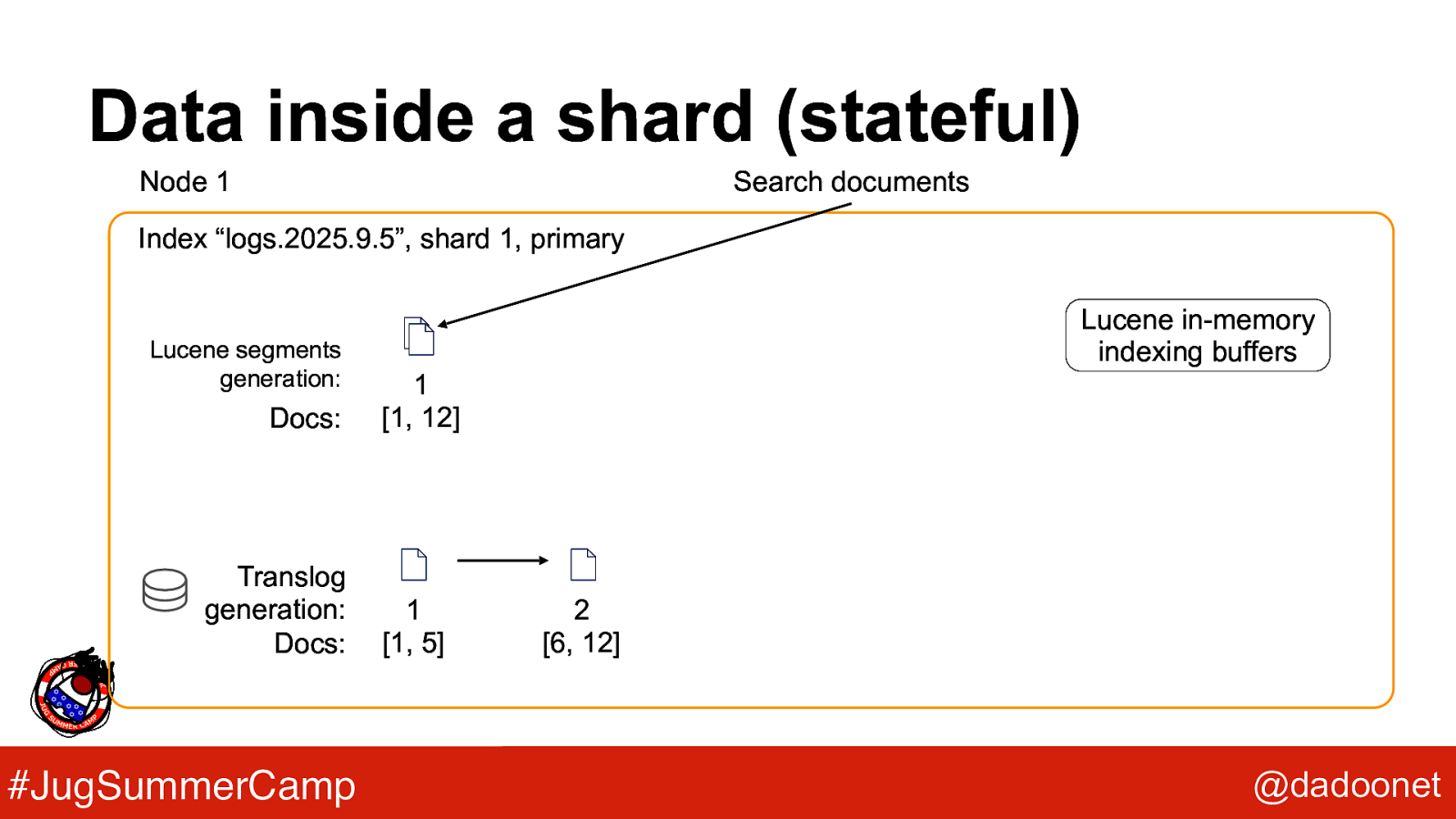
Data inside a shard (stateful) Node 1 Search documents Index “logs.2025.9.5”, shard 1, primary Lucene segments generation: Docs: Translog generation: Docs: #JugSummerCamp Lucene in-memory indexing buffers 1 [1, 12] 1 [1, 5] 2 [6, 12] @dadoonet
Slide 18
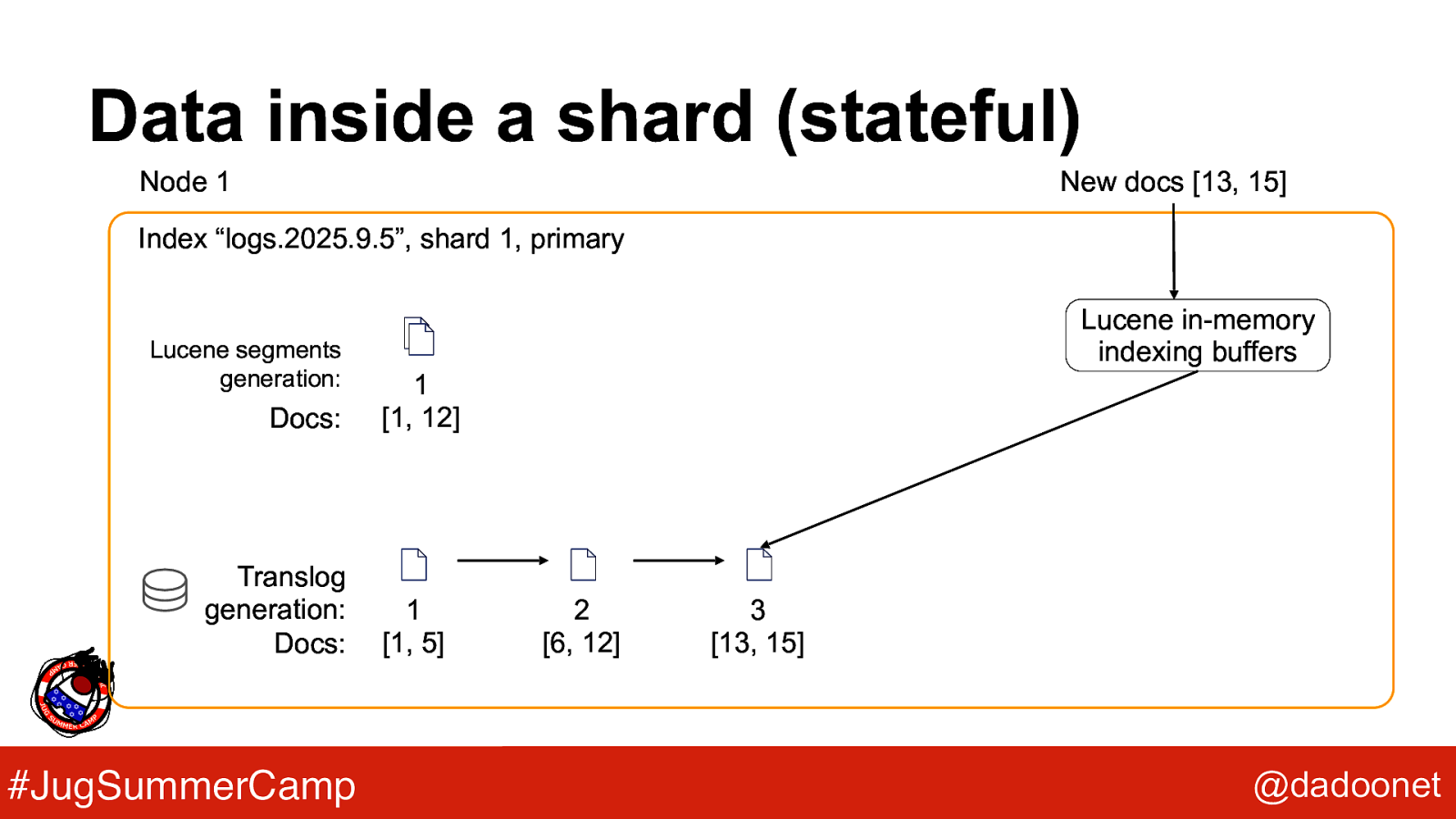
Data inside a shard (stateful) Node 1 New docs [13, 15] Index “logs.2025.9.5”, shard 1, primary Lucene segments generation: Docs: Translog generation: Docs: #JugSummerCamp Lucene in-memory indexing buffers 1 [1, 12] 1 [1, 5] 2 [6, 12] 3 [13, 15] @dadoonet
Slide 19
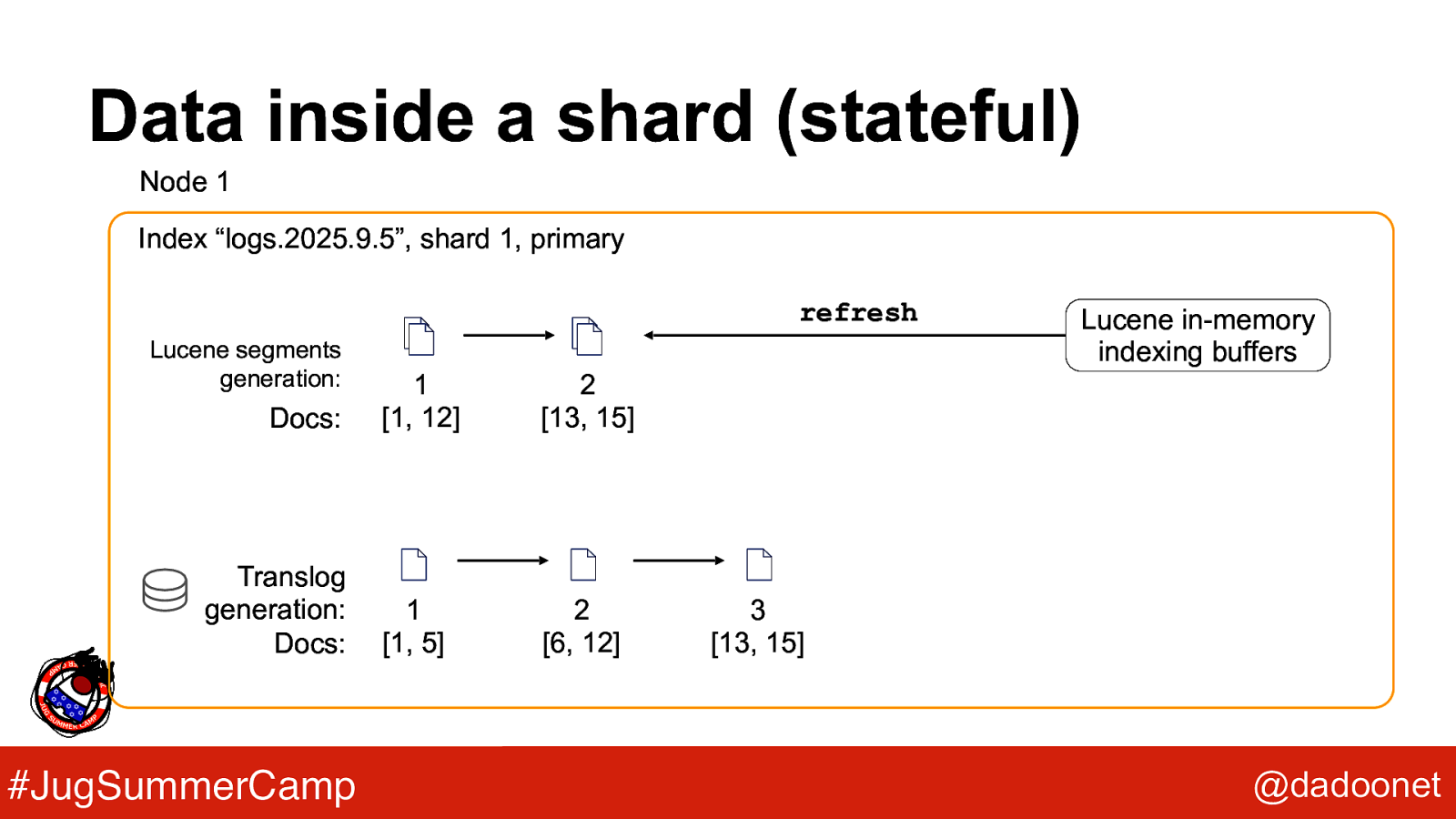
Data inside a shard (stateful) Node 1 Index “logs.2025.9.5”, shard 1, primary refresh Lucene segments generation: Docs: Translog generation: Docs: #JugSummerCamp 1 [1, 12] 2 [13, 15] 1 [1, 5] 2 [6, 12] Lucene in-memory indexing buffers 3 [13, 15] @dadoonet
Slide 20

Data inside a shard (stateful) Node 1 Index “logs.2025.9.5”, shard 1, primary Lucene segments generation: Docs: Flushed commits: Translog generation: Docs: #JugSummerCamp Lucene in-memory indexing buffers 1 [1, 12] 2 [13, 15] Index flush Commit 2 1 [1, 5] 2 [6, 12] 3 [13, 15] @dadoonet
Slide 21

Data inside a shard (stateful) Node 1 Index “logs.2025.9.5”, shard 1, primary Lucene segments generation: Docs: Flushed commits: Lucene in-memory indexing buffers 1 [1, 12] 2 [13, 15] Commit 2 Translog generation: Docs: #JugSummerCamp @dadoonet
Slide 22
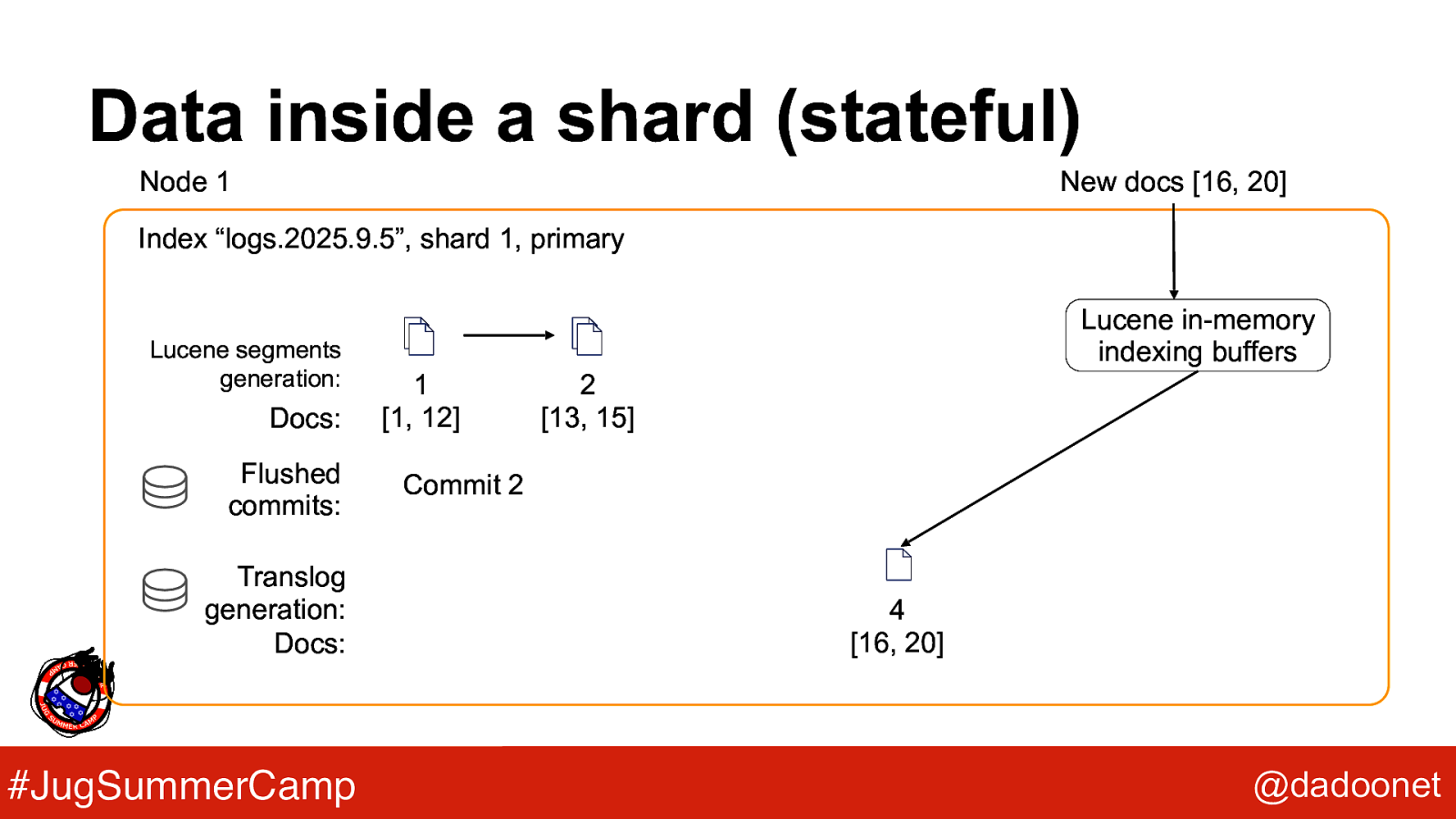
Data inside a shard (stateful) Node 1 New docs [16, 20] Index “logs.2025.9.5”, shard 1, primary Lucene segments generation: Docs: Flushed commits: Translog generation: Docs: #JugSummerCamp Lucene in-memory indexing buffers 1 [1, 12] 2 [13, 15] Commit 2 4 [16, 20] @dadoonet
Slide 23
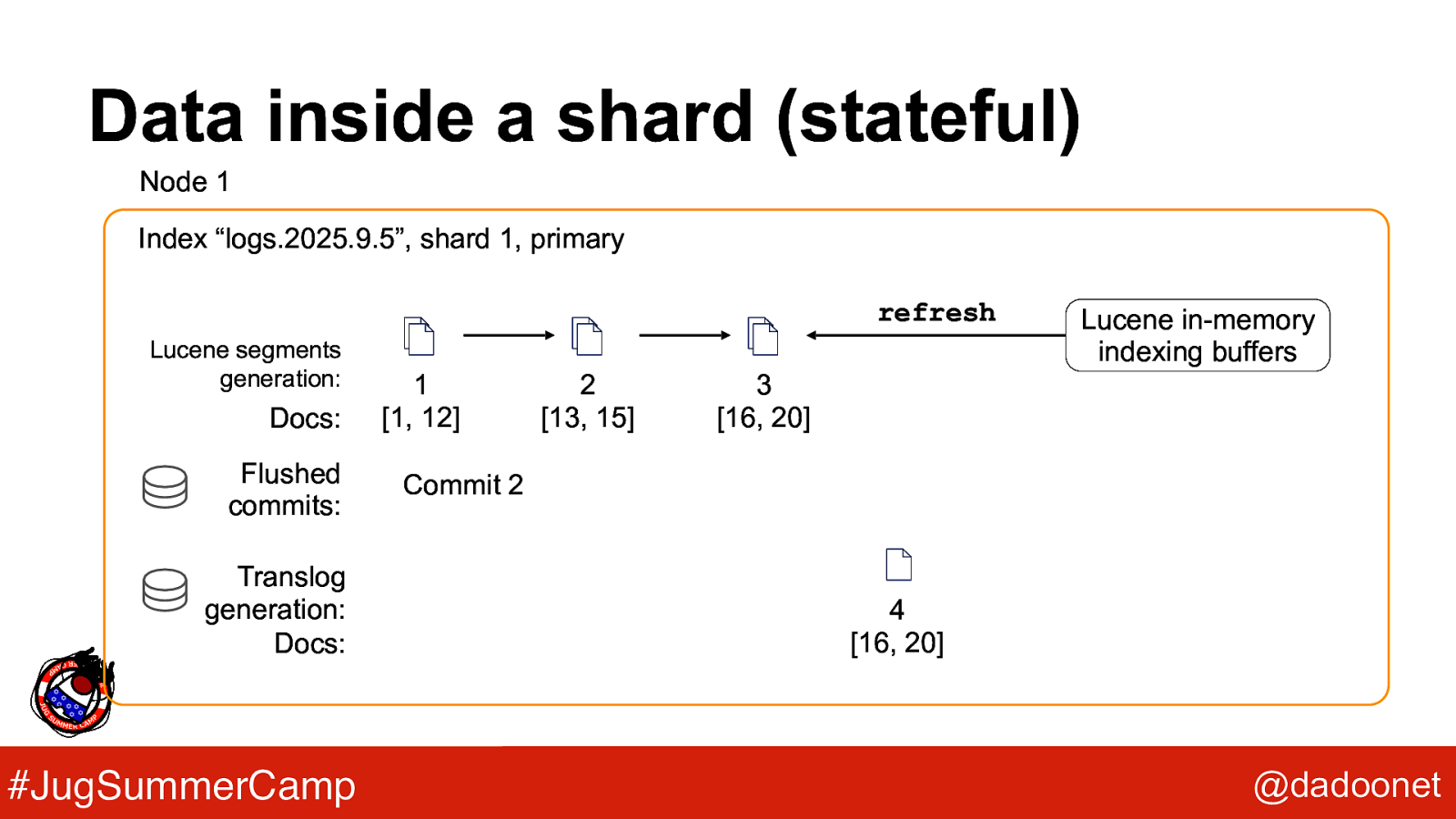
Data inside a shard (stateful) Node 1 Index “logs.2025.9.5”, shard 1, primary refresh Lucene segments generation: Docs: Flushed commits: Translog generation: Docs: #JugSummerCamp 1 [1, 12] 2 [13, 15] Lucene in-memory indexing buffers 3 [16, 20] Commit 2 4 [16, 20] @dadoonet
Slide 24
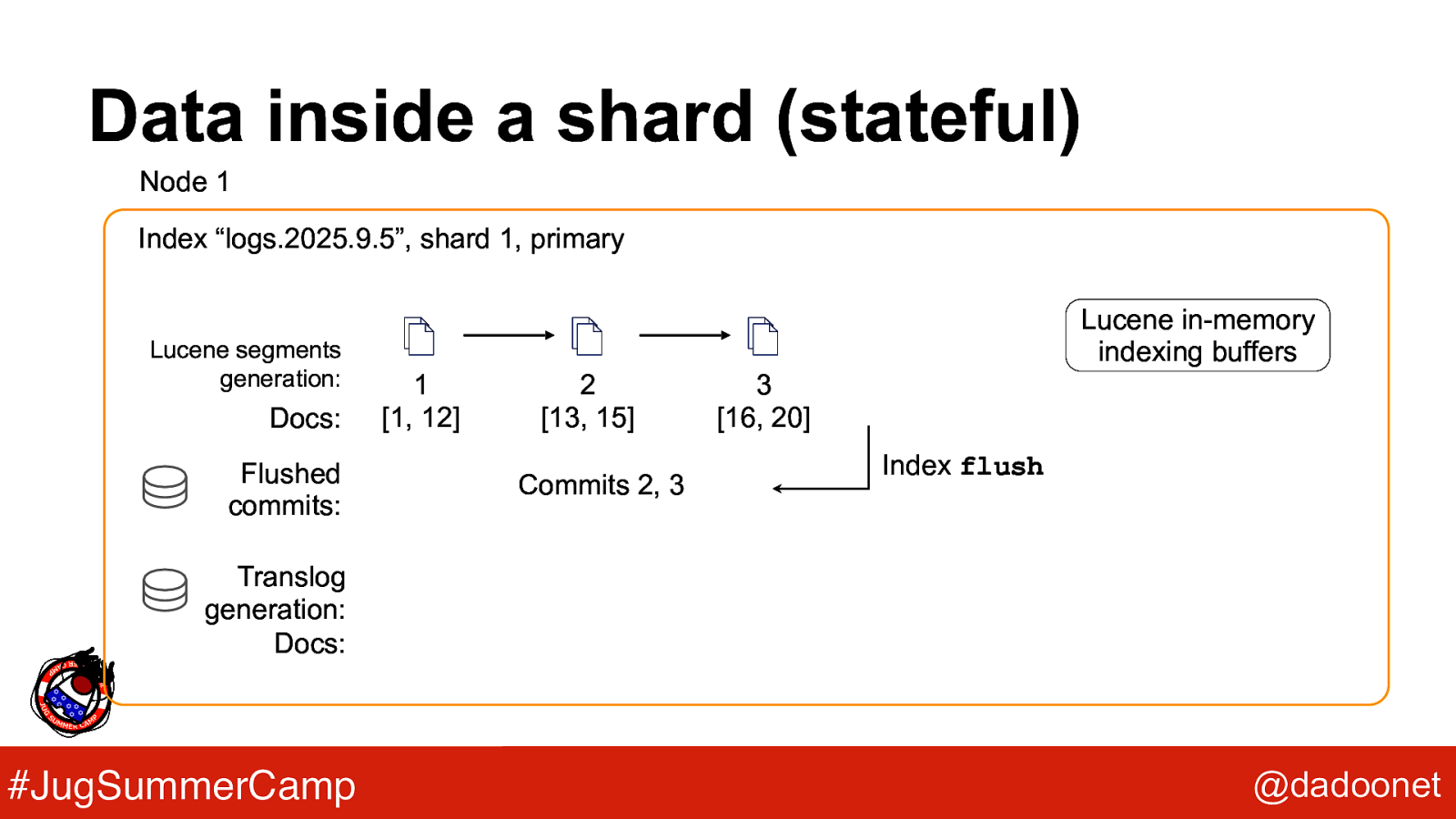
Data inside a shard (stateful) Node 1 Index “logs.2025.9.5”, shard 1, primary Lucene segments generation: Docs: Flushed commits: Lucene in-memory indexing buffers 1 [1, 12] 2 [13, 15] Commits 2, 3 3 [16, 20] Index flush Translog generation: Docs: #JugSummerCamp @dadoonet
Slide 25
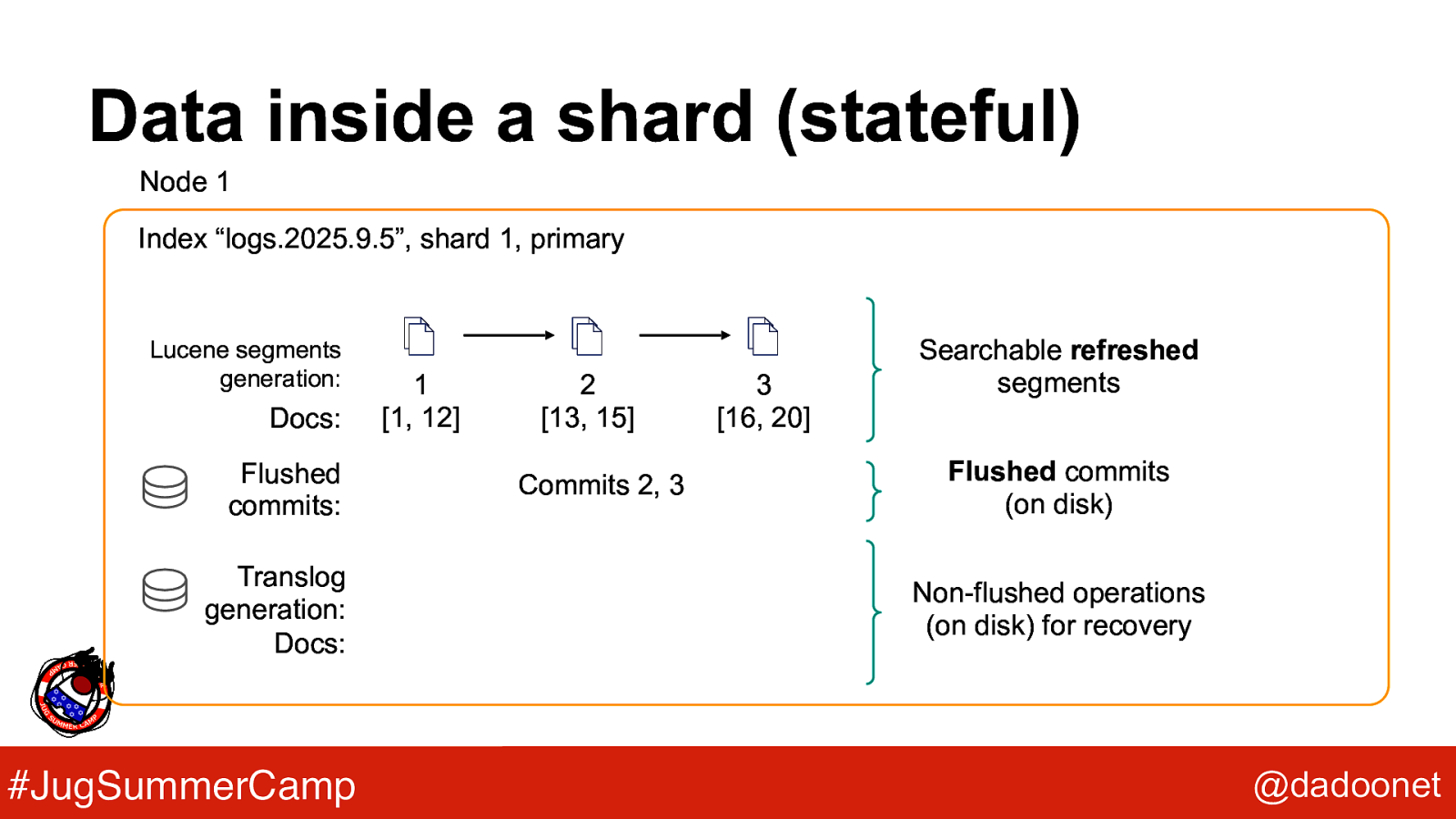
Data inside a shard (stateful) Node 1 Index “logs.2025.9.5”, shard 1, primary Lucene segments generation: Docs: Flushed commits: Translog generation: Docs: #JugSummerCamp 1 [1, 12] 2 [13, 15] Commits 2, 3 3 [16, 20] Searchable refreshed segments Flushed commits (on disk) Non-flushed operations (on disk) for recovery @dadoonet
Slide 26

Stateless example offloading shard data to an object store
Slide 27

Offloading index data to the object store (stateless) Node 1 (indexing) New docs [1, 5] Index “logs.2025.9.5”, shard 1 CSP object storage Lucene in-memory indexing buffers Lucene segments generation: (e.g., Amazon S3) Docs: Flushed commits: Translog generation: Docs: #JugSummerCamp 1 [1, 5] @dadoonet
Slide 28
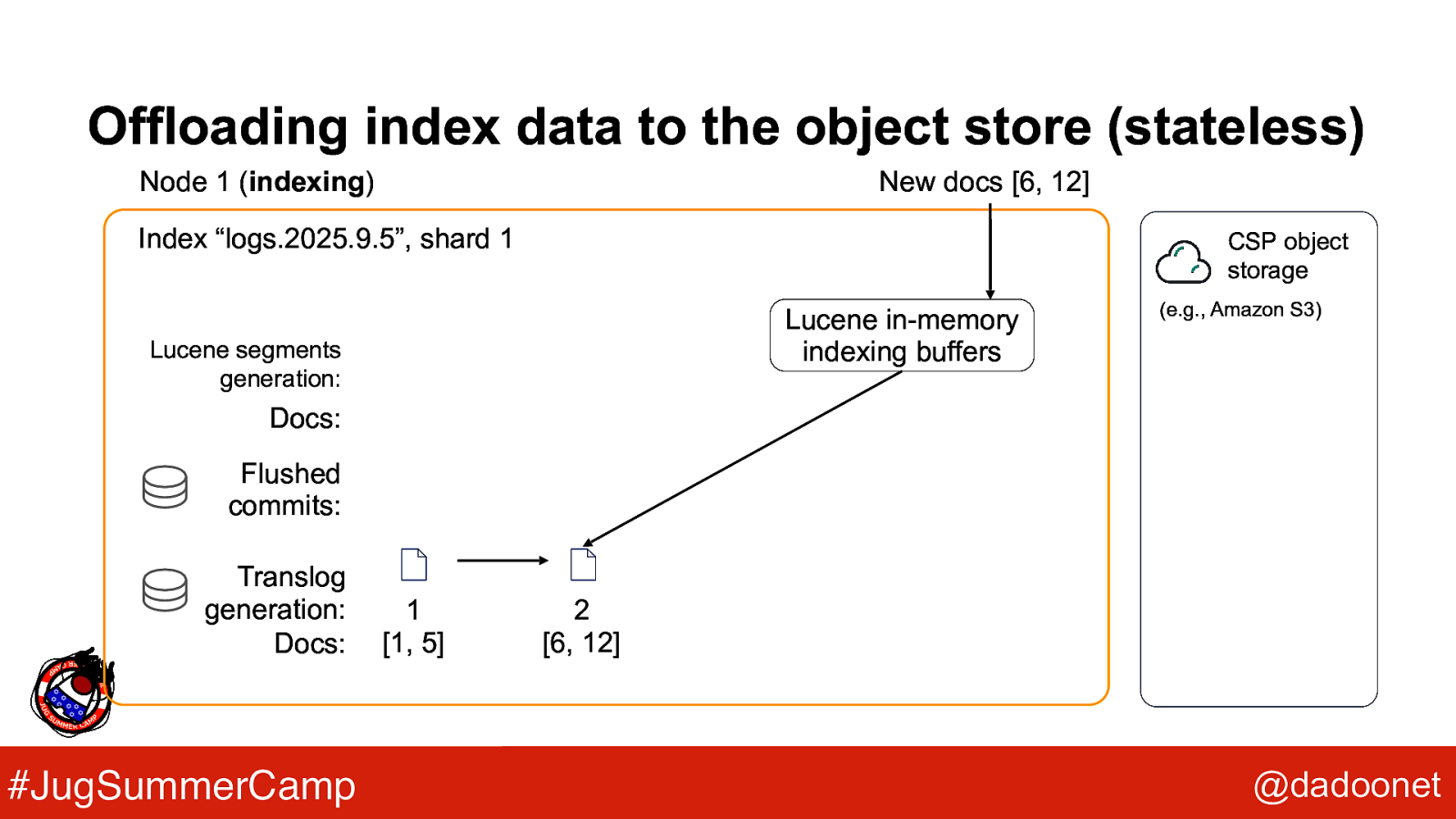
Offloading index data to the object store (stateless) Node 1 (indexing) New docs [6, 12] Index “logs.2025.9.5”, shard 1 CSP object storage Lucene in-memory indexing buffers Lucene segments generation: (e.g., Amazon S3) Docs: Flushed commits: Translog generation: Docs: #JugSummerCamp 1 [1, 5] 2 [6, 12] @dadoonet
Slide 29
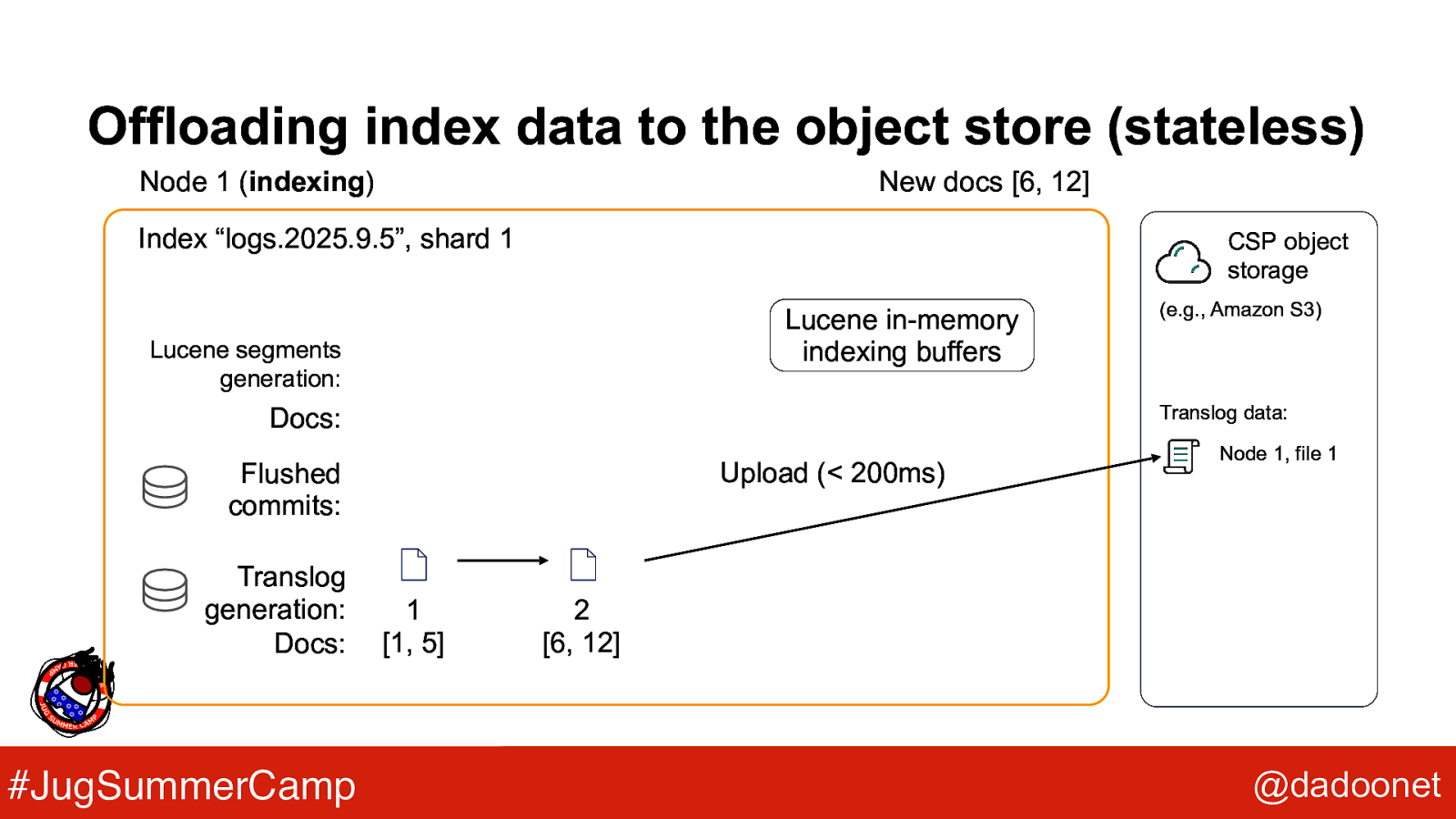
Offloading index data to the object store (stateless) Node 1 (indexing) New docs [6, 12] Index “logs.2025.9.5”, shard 1 CSP object storage Lucene in-memory indexing buffers Lucene segments generation: Translog data: Docs: Upload (< 200ms) Flushed commits: Translog generation: Docs: #JugSummerCamp (e.g., Amazon S3) 1 [1, 5] Node 1, file 1 2 [6, 12] @dadoonet
Slide 30

Offloading index data to the object store (stateless) Node 1 (indexing) Acknowledged writes Index “logs.2025.9.5”, shard 1 CSP object storage Lucene in-memory indexing buffers Lucene segments generation: Translog data: Docs: Node 1, file 1 Flushed commits: Translog generation: Docs: #JugSummerCamp (e.g., Amazon S3) 1 [1, 5] 2 [6, 12] @dadoonet
Slide 31

Offloading index data to the object store (stateless) Node 1 (indexing) Index “logs.2025.9.5”, shard 1 CSP object storage refresh Lucene segments generation: Docs: Flushed commits: 1 [1, 12] Lucene in-memory indexing buffers (e.g., Amazon S3) Translog data: Node 1, file 1 Commit 1 Translog generation: Docs: #JugSummerCamp @dadoonet
Slide 32

Offloading index data to the object store (stateless) Node 1 (indexing) New docs [13, 15] Index “logs.2025.9.5”, shard 1 Lucene segments generation: Docs: Flushed commits: Translog generation: Docs: #JugSummerCamp CSP object storage Lucene in-memory indexing buffers 1 [1, 12] (e.g., Amazon S3) Translog data: Node 1, file 1 Commit 1 3 [13, 15] @dadoonet
Slide 33

Offloading index data to the object store (stateless) Node 1 (indexing) New docs [13, 15] Index “logs.2025.9.5”, shard 1 Lucene segments generation: Docs: Flushed commits: Translog generation: Docs: #JugSummerCamp CSP object storage Lucene in-memory indexing buffers 1 [1, 12] (e.g., Amazon S3) Translog data: Node 1, file 1 Commit 1 Upload (< 200ms) Node 1, file 2 3 [13, 15] @dadoonet
Slide 34

Offloading index data to the object store (stateless) Node 1 (indexing) Acknowledged writes Index “logs.2025.9.5”, shard 1 Lucene segments generation: Docs: Flushed commits: Translog generation: Docs: #JugSummerCamp CSP object storage Lucene in-memory indexing buffers 1 [1, 12] (e.g., Amazon S3) Translog data: Node 1, file 1 Commit 1 Node 1, file 2 3 [13, 15] @dadoonet
Slide 35

Offloading index data to the object store (stateless) Node 1 (indexing) Index “logs.2025.9.5”, shard 1 Lucene segments generation: Docs: Flushed commits: CSP object storage refresh Lucene in-memory indexing buffers 1 [1, 12] 2 [13, 15] (e.g., Amazon S3) Translog data: Node 1, file 1 Commits 1, 2 Node 1, file 2 Translog generation: Docs: #JugSummerCamp @dadoonet
Slide 36

Offloading index data to the object store (stateless) Node 1 (indexing) Index “logs.2025.9.5”, shard 1 Lucene segments generation: Docs: Flushed commits: Translog generation: Docs: #JugSummerCamp CSP object storage Lucene in-memory indexing buffers 1 [1, 12] 2 [13, 15] Commits 1, 2 (e.g., Amazon S3) Translog data: Index flush Upload (deleted) Index data: logs.2025.9.5 shard 1, BCC1 (Batched compound commit) @dadoonet
Slide 37

Offloading index data to the object store (stateless) Node 2 (search) Index “logs.2025.9.5”, shard 1 Lucene segments generation: Docs: Flushed commits: Translog generation: Docs: #JugSummerCamp CSP object storage Lucene in-memory indexing buffers 1 [1, 12] 2 [13, 15] Commits 1, 2 Node Cache (e.g., Amazon S3) Translog data: Partially mounted: Index data: logs.2025.9.5 shard 1, BCC1 (Batched compound commit) @dadoonet
Slide 38
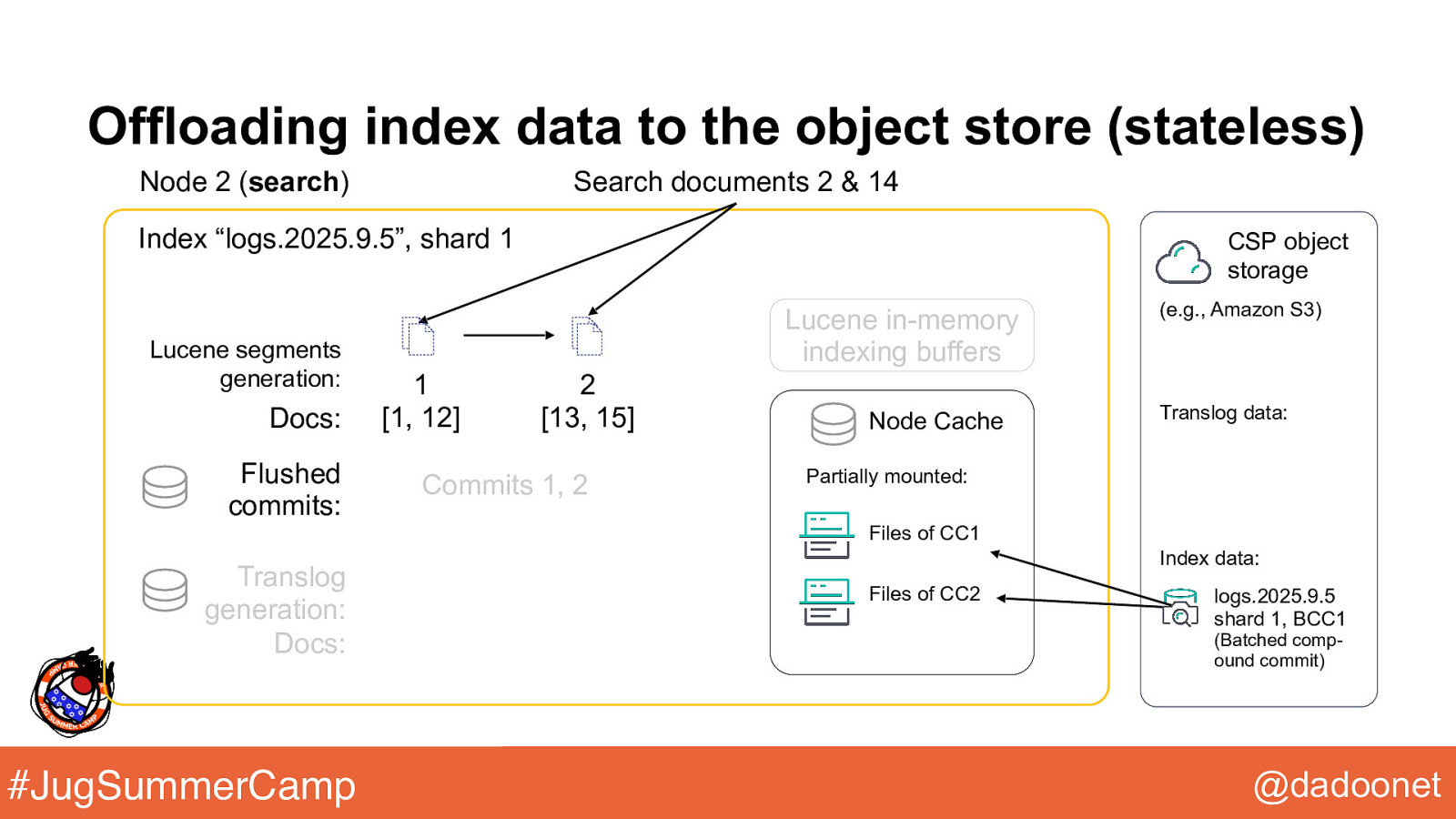
Offloading index data to the object store (stateless) Node 2 (search) Search documents 2 & 14 Index “logs.2025.9.5”, shard 1 Lucene segments generation: Docs: Flushed commits: CSP object storage Lucene in-memory indexing buffers 1 [1, 12] 2 [13, 15] Commits 1, 2 Node Cache (e.g., Amazon S3) Translog data: Partially mounted: Files of CC1 Translog generation: Docs: #JugSummerCamp Index data: Files of CC2 logs.2025.9.5 shard 1, BCC1 (Batched compound commit) @dadoonet
Slide 39
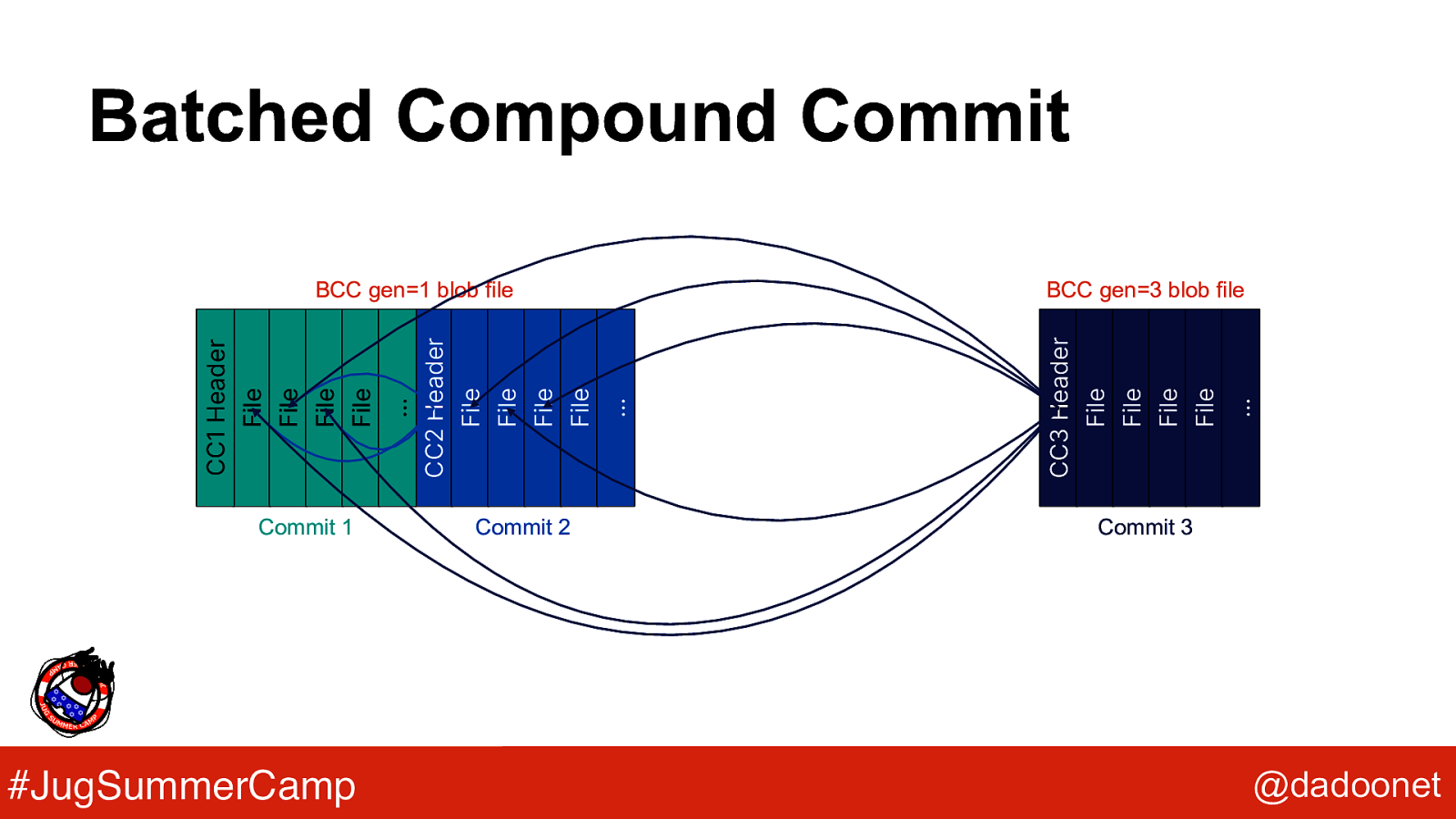
Batched Compound Commit Commit 1 #JugSummerCamp Commit 2 File File File … BCC gen=3 blob file CC3 Header File File File File File … CC2 Header File File File File … CC1 Header BCC gen=1 blob file Commit 3 @dadoonet
Slide 40
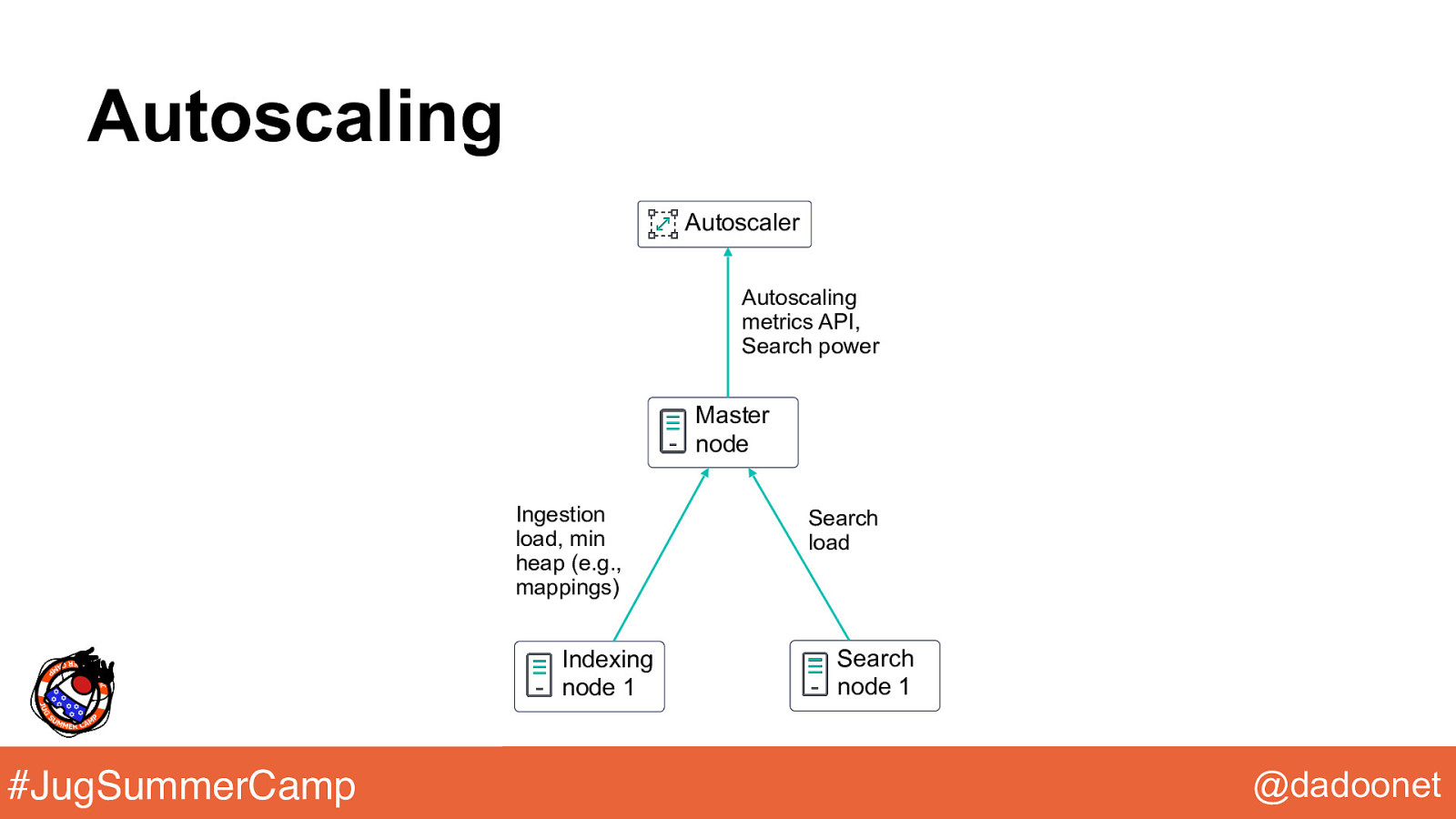
Autoscaling Autoscaler Autoscaling metrics API, Search power Master node Ingestion load, min heap (e.g., mappings) Indexing node 1 #JugSummerCamp Search load Search node 1 @dadoonet
Slide 41
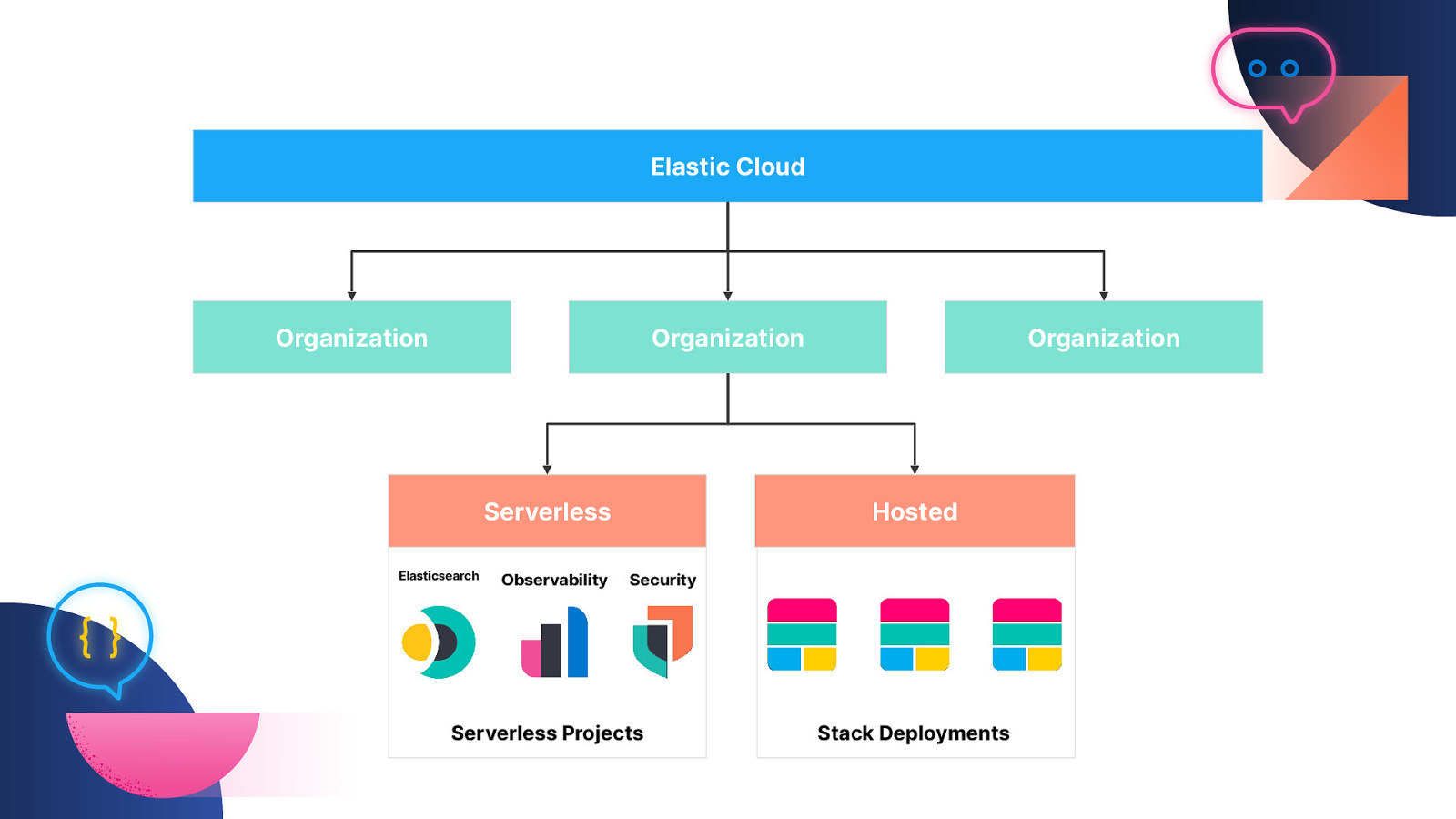
Elastic Cloud Organization Organization Serverless Elasticsearch Observability Organization Hosted Security Serverless Projects Stack Deployments
Slide 42
#JugSummerCamp @dadoonet
Slide 43
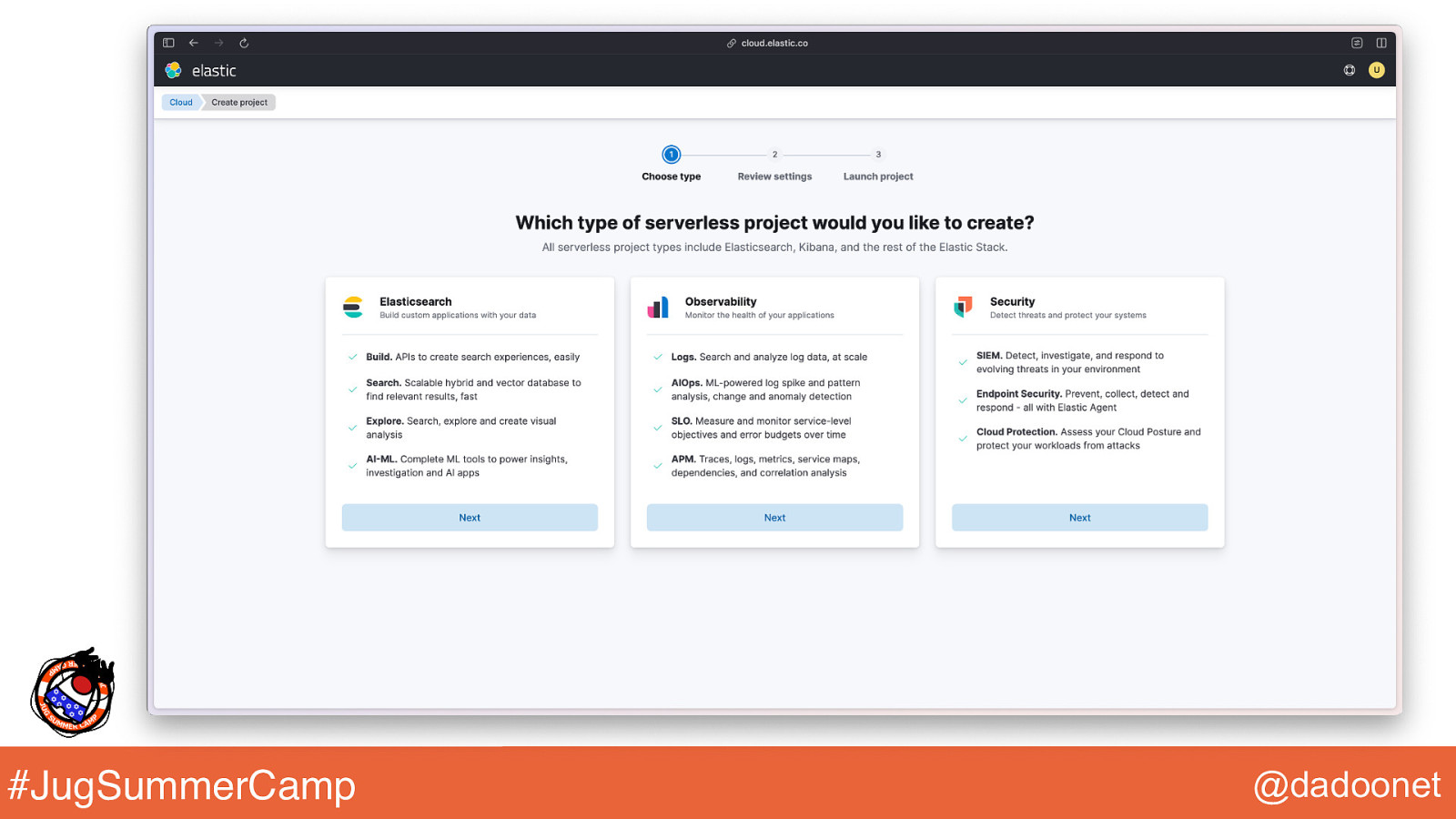
#JugSummerCamp @dadoonet
Slide 44

Summary ● Elasticsearch is an unparalleled scalable search & analytics engine ● ES has been stateful, relying on disk durability ● New Serverless ES is stateless; durability on CSP object store ● Just two tiers, indexing and search → independent workloads ● Partial caching enables indexing and searching limitless data ● Thin shards that can relocate/recover fast ● Users just use the same API ● Pay-as-you-go model for data retention, indexing, searching #JugSummerCamp @dadoonet
Slide 45

Limitations ● Links to external resources in Kibana is not supported ● Refresh rate non adjustable to less than x per minute ● No dashboard export as PNG/PDF (no headless browser) ● Subset of APIs only ● Can not define the number of shards #JugSummerCamp @dadoonet
Slide 46

Feedback Do MORE with StateLESS Elasticsearch