Indexing your office documents with Elastic and FSCrawler David Pilato Developer | Evangelist, Community @dadoonet
Slide 1

Slide 2
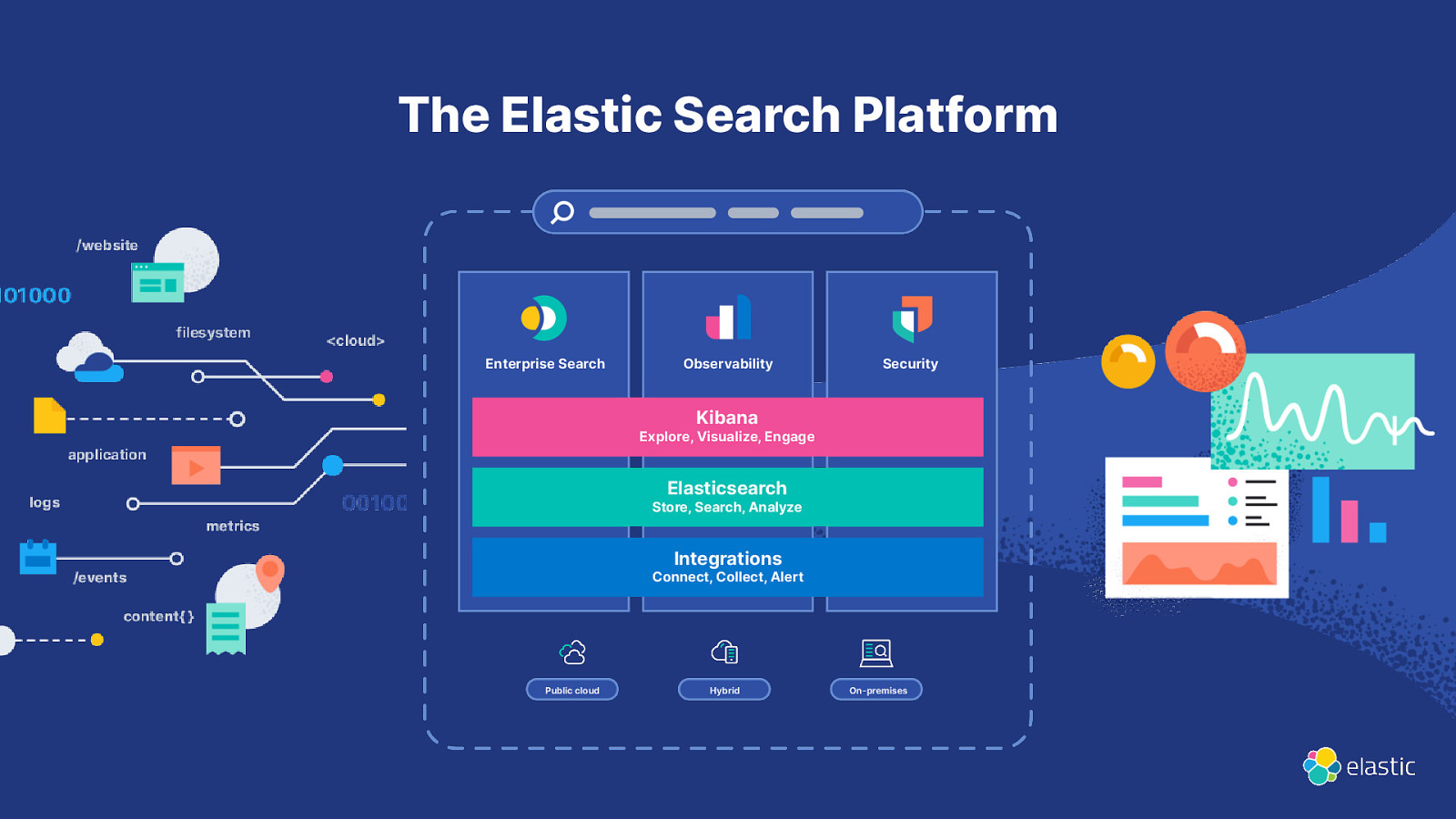
The Elastic Search Platform Enterprise Search Observability Security Kibana Explore, Visualize, Engage Elasticsearch Store, Search, Analyze Integrations Connect, Collect, Alert Public cloud Hybrid On-premises
Slide 3

Slide 4
Slide 5

Parsing a stream and getting content and metadata static void extractTextAndMetadata(InputStream stream) throws Exception { BodyContentHandler handler = new BodyContentHandler(); Metadata metadata = new Metadata(); try (stream) { new DefaultParser().parse(stream, handler, metadata, new ParseContext()); String extractedText = handler.toString(); String title = metadata.get(TikaCoreProperties.TITLE); String keywords = metadata.get(TikaCoreProperties.KEYWORDS); String author = metadata.get(TikaCoreProperties.CREATOR); } }
Slide 6

ingest-attachment plugin extracting from BASE64 or CBOR 6
Slide 7
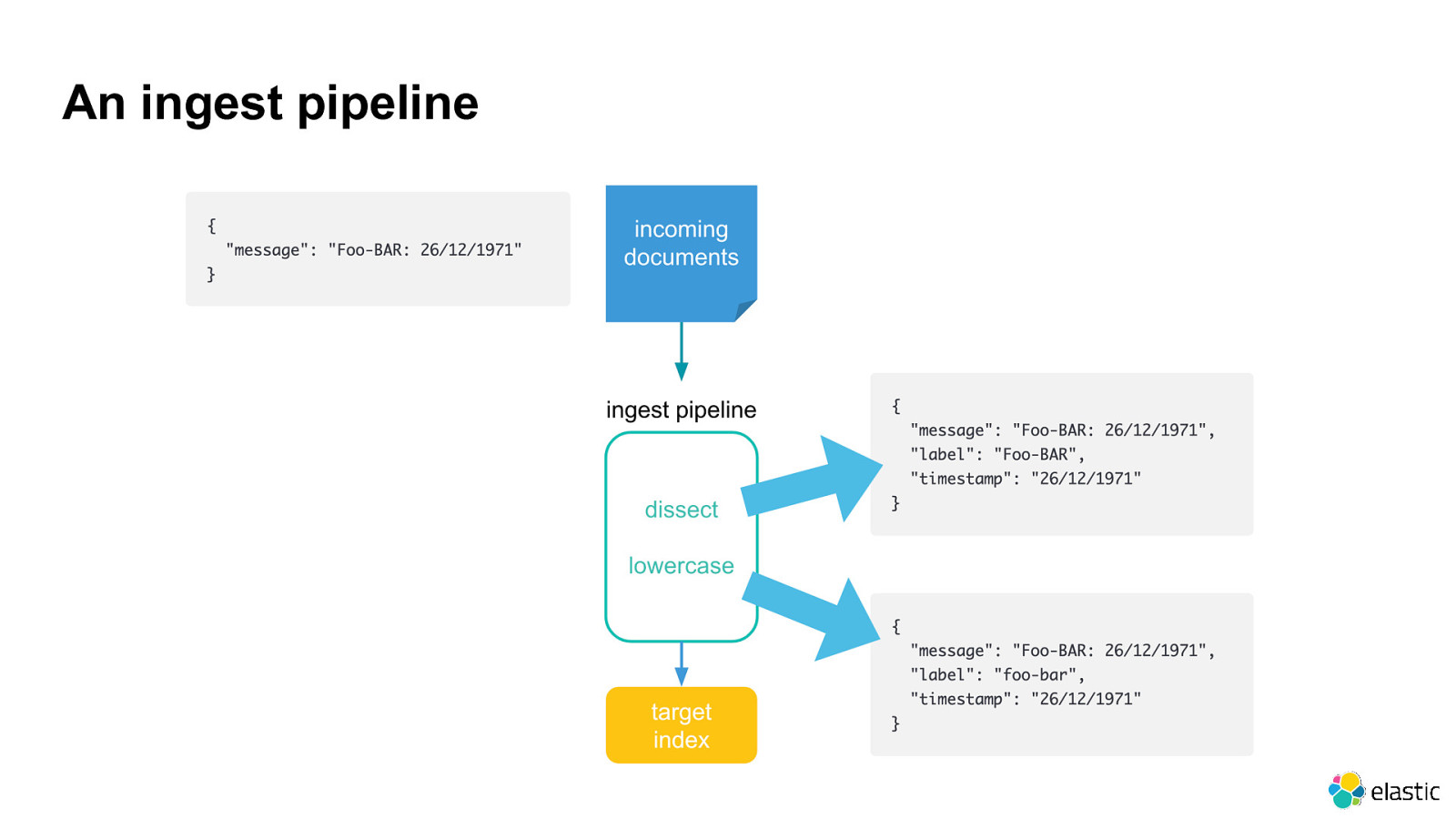
An ingest pipeline
Slide 8

ingest-attachment processor plugin using Tika behind the scene
Slide 9

Demo https://cloud.elastic.co 9
Slide 10

FSCrawler You know, for files… 10
Slide 11
Slide 12

Disclaimer This project is a community project. It is not officially supported by Elastic. Support is only provided by FSCrawler community on discuss and stackoverflow. http://discuss.elastic.co/ https://stackoverflow.com/questions/tagged/fscrawler
Slide 13
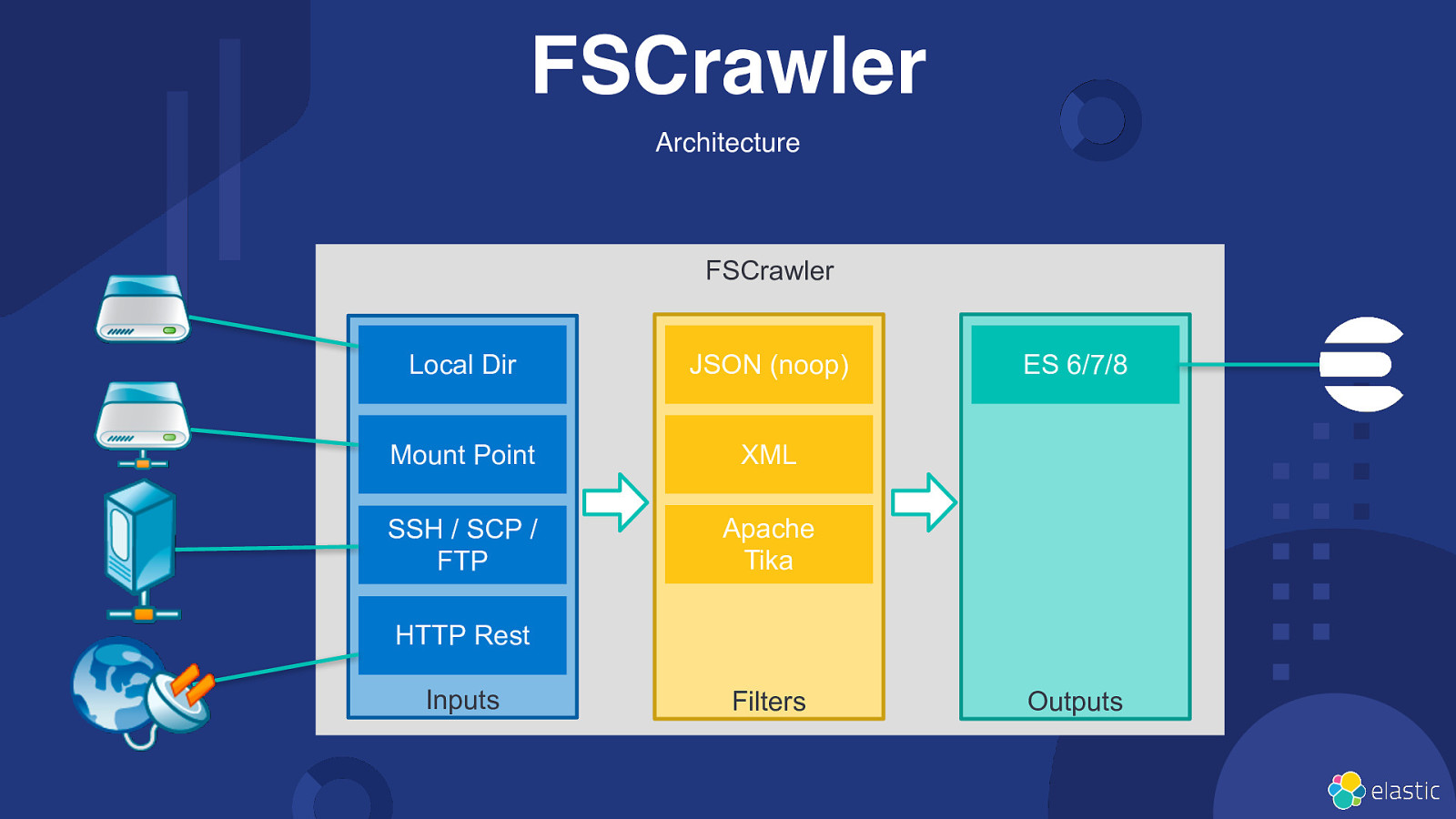
FSCrawler Architecture FSCrawler Local Dir JSON (noop) Mount Point XML SSH / SCP / FTP Apache Tika ES 6/7/8 HTTP Rest Inputs Filters Outputs
Slide 14

FSCrawler Key Features • • • Much more formats than ingest attachment plugin OCR (Tesseract) Much more metadata than ingest attachment plugin (See https://fscrawler.readthedocs.io/en/latest/admin/fs/elasticsearch.html#generated-fields) • Extraction of non standard metadata
Slide 15

FSCrawler even better with a UI 15
Slide 16
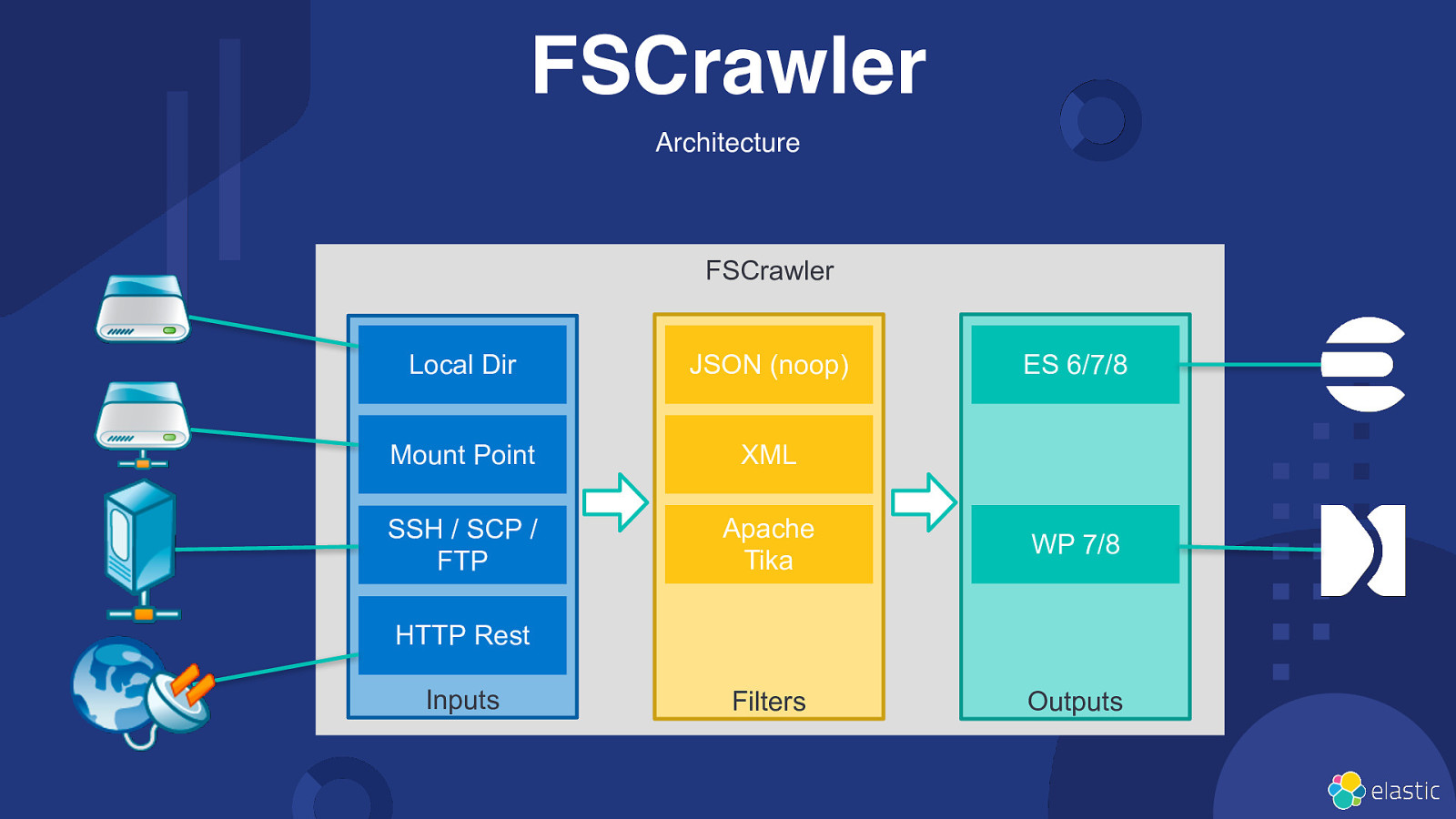
FSCrawler Architecture FSCrawler Local Dir JSON (noop) Mount Point XML SSH / SCP / FTP Apache Tika WP 7/8 Filters Outputs ES 6/7/8 HTTP Rest Inputs
Slide 17

Demo https://cloud.elastic.co 17
Slide 18

Be t 8. a 2 Network drives connector package for Enterprise Search https://github.com/elastic/enterprise-search-network-drives-connector/
Slide 19

Thanks! PR are warmly welcomed! https://github.com/dadoonet/fscrawler