Managing your Black Friday Logs David Pilato Developer | Evangelist, @dadoonet
Slide 1

Slide 2

Data Platform Architectures
Slide 3

The Elastic Journey of Data Beats Log Files Wire Data Metrics your{beat} 3 @dadoonet sli.do/elastic
Slide 4
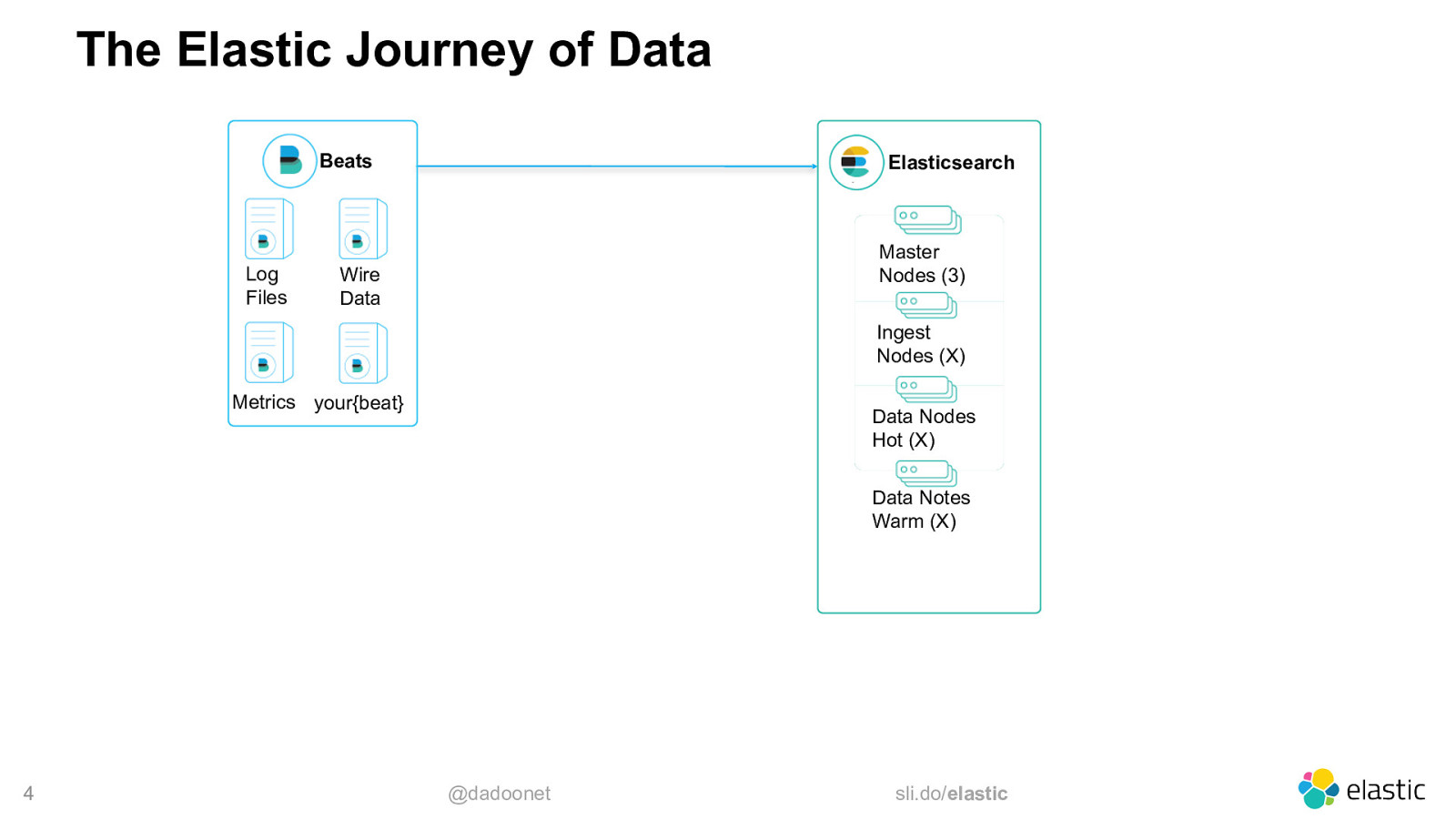
The Elastic Journey of Data Beats Log Files Elasticsearch Master Nodes (3) Wire Data Ingest Nodes (X) Metrics your{beat} Data Nodes Hot (X) Data Notes Warm (X) 4 @dadoonet sli.do/elastic
Slide 5
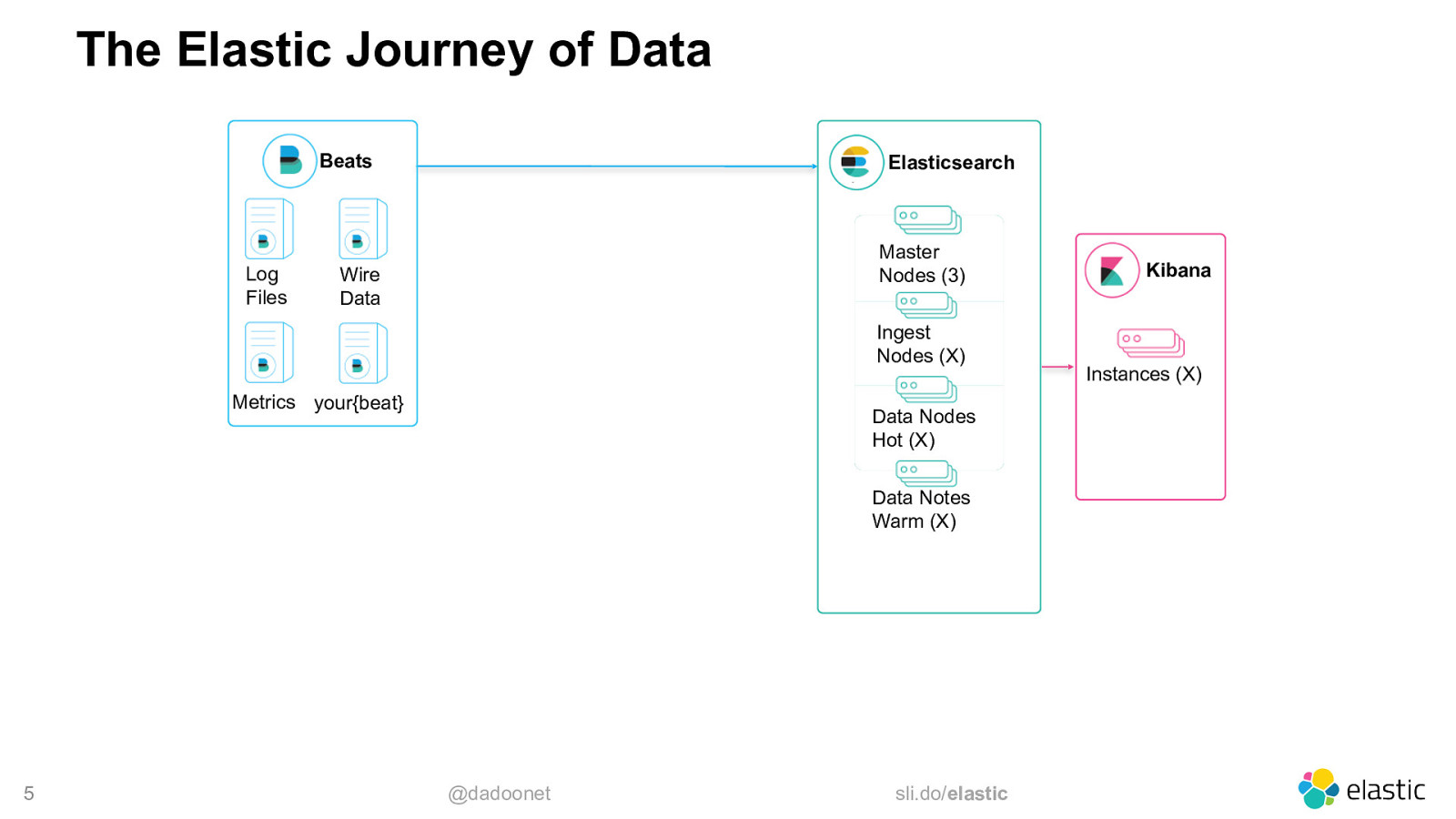
The Elastic Journey of Data Beats Log Files Elasticsearch Master Nodes (3) Wire Data Ingest Nodes (X) Metrics your{beat} Data Nodes Hot (X) Data Notes Warm (X) 5 @dadoonet sli.do/elastic Kibana Instances (X)
Slide 6
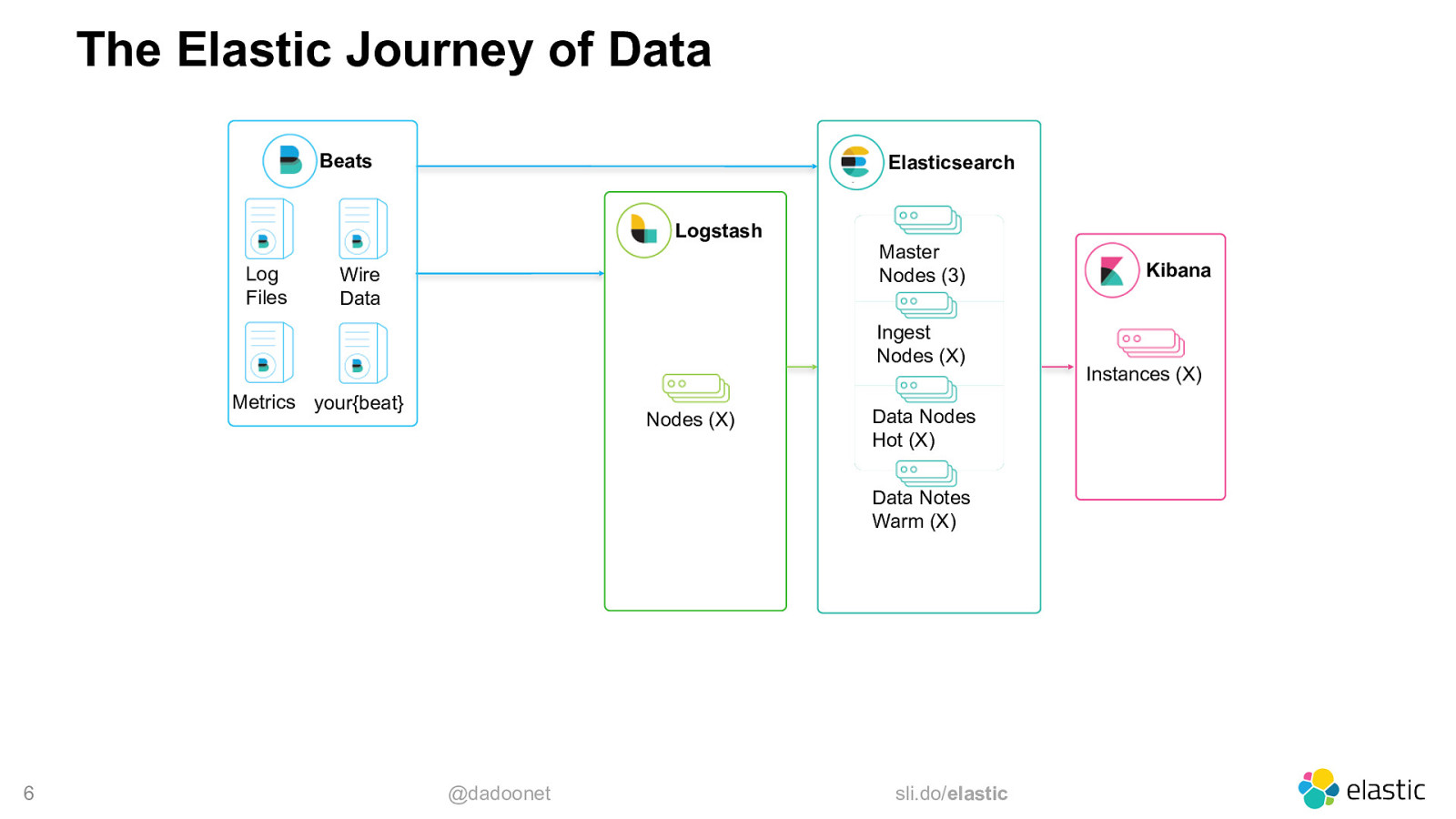
The Elastic Journey of Data Beats Elasticsearch Logstash Log Files Wire Data Master Nodes (3) Ingest Nodes (X) Metrics your{beat} Nodes (X) Data Nodes Hot (X) Data Notes Warm (X) 6 @dadoonet sli.do/elastic Kibana Instances (X)
Slide 7
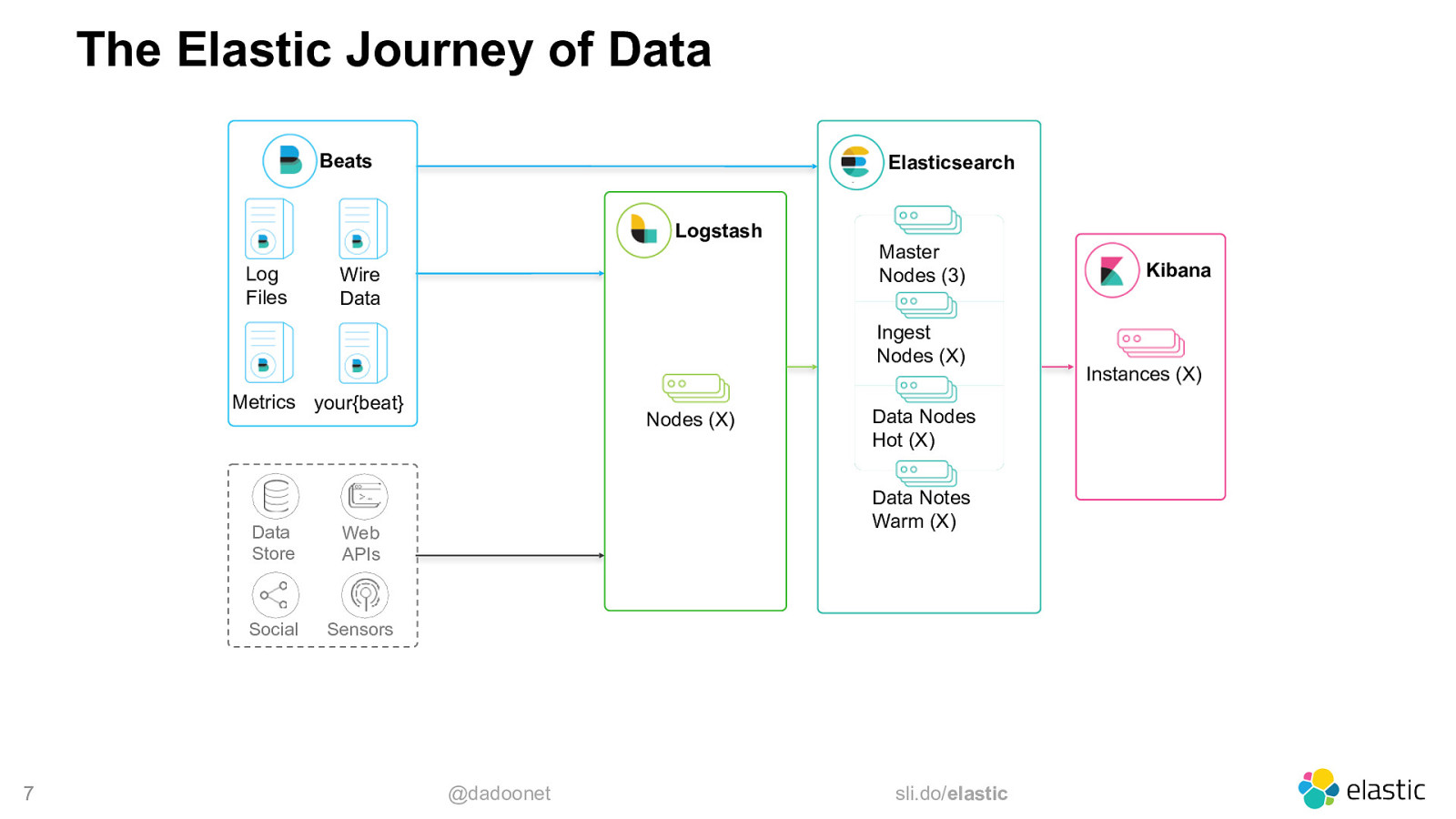
The Elastic Journey of Data Beats Elasticsearch Logstash Log Files Wire Data Master Nodes (3) Ingest Nodes (X) Metrics your{beat} 7 Data Store Web APIs Social Sensors Nodes (X) Data Nodes Hot (X) Data Notes Warm (X) @dadoonet sli.do/elastic Kibana Instances (X)
Slide 8
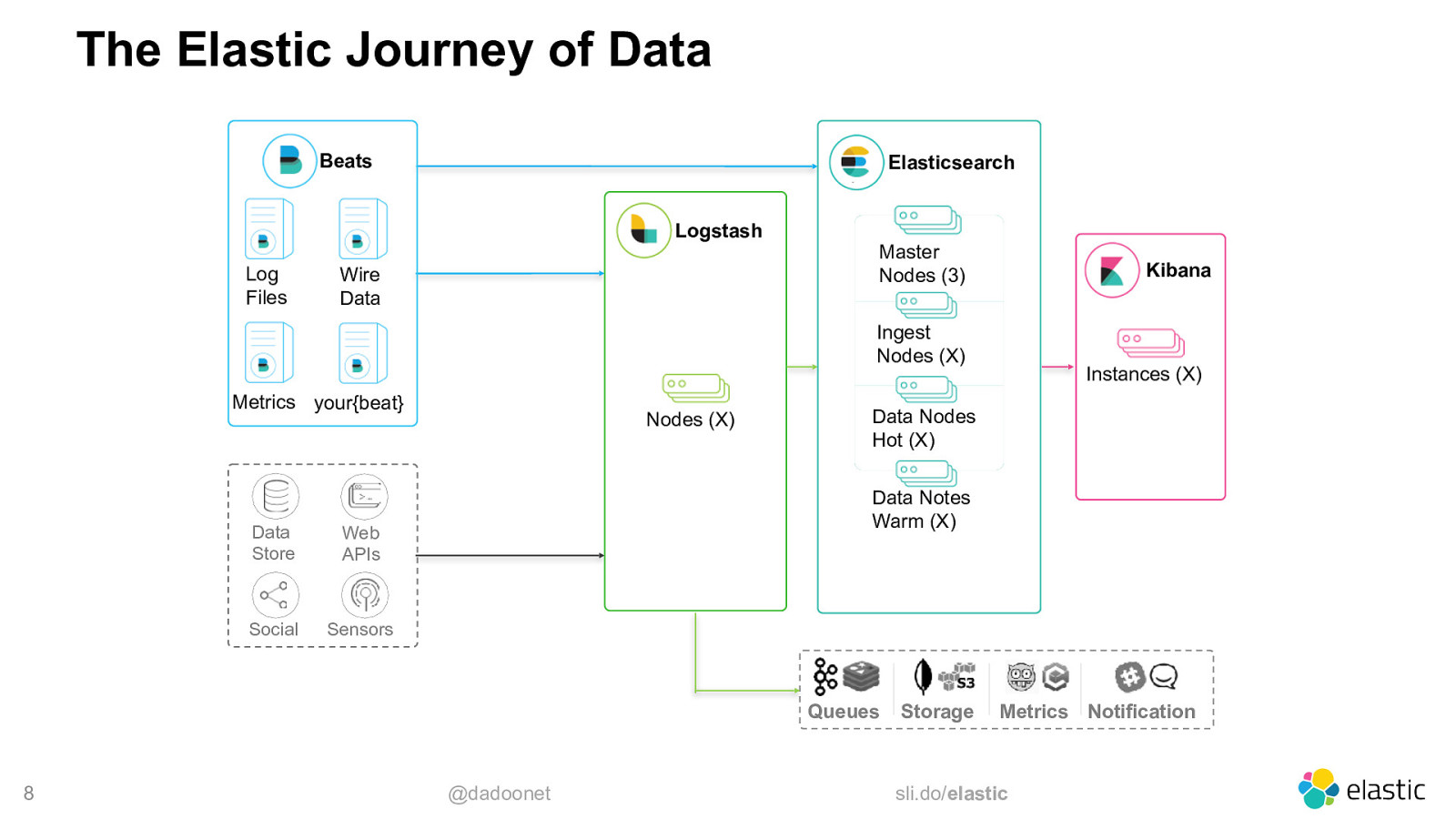
The Elastic Journey of Data Beats Elasticsearch Logstash Log Files Wire Data Master Nodes (3) Kibana Ingest Nodes (X) Metrics your{beat} Data Store Web APIs Social Sensors Nodes (X) Data Nodes Hot (X) Data Notes Warm (X) Queues 8 Instances (X) @dadoonet Storage Metrics Notification sli.do/elastic
Slide 9
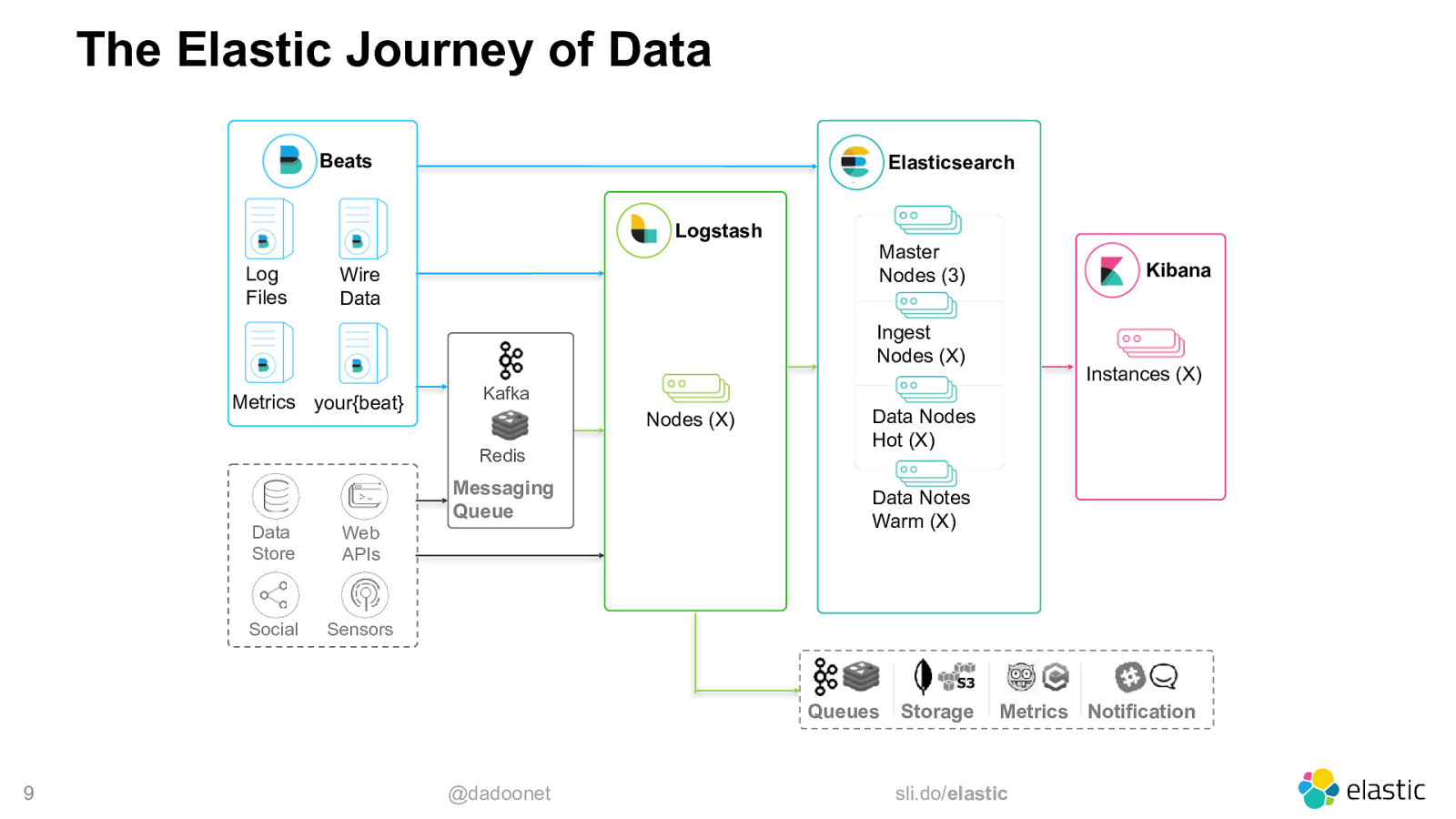
The Elastic Journey of Data Beats Elasticsearch Logstash Log Files Wire Data Master Nodes (3) Kibana Ingest Nodes (X) Metrics your{beat} Kafka Nodes (X) Redis Messaging Queue Data Store Web APIs Social Sensors Data Nodes Hot (X) Data Notes Warm (X) Queues 9 Instances (X) @dadoonet Storage Metrics Notification sli.do/elastic
Slide 10
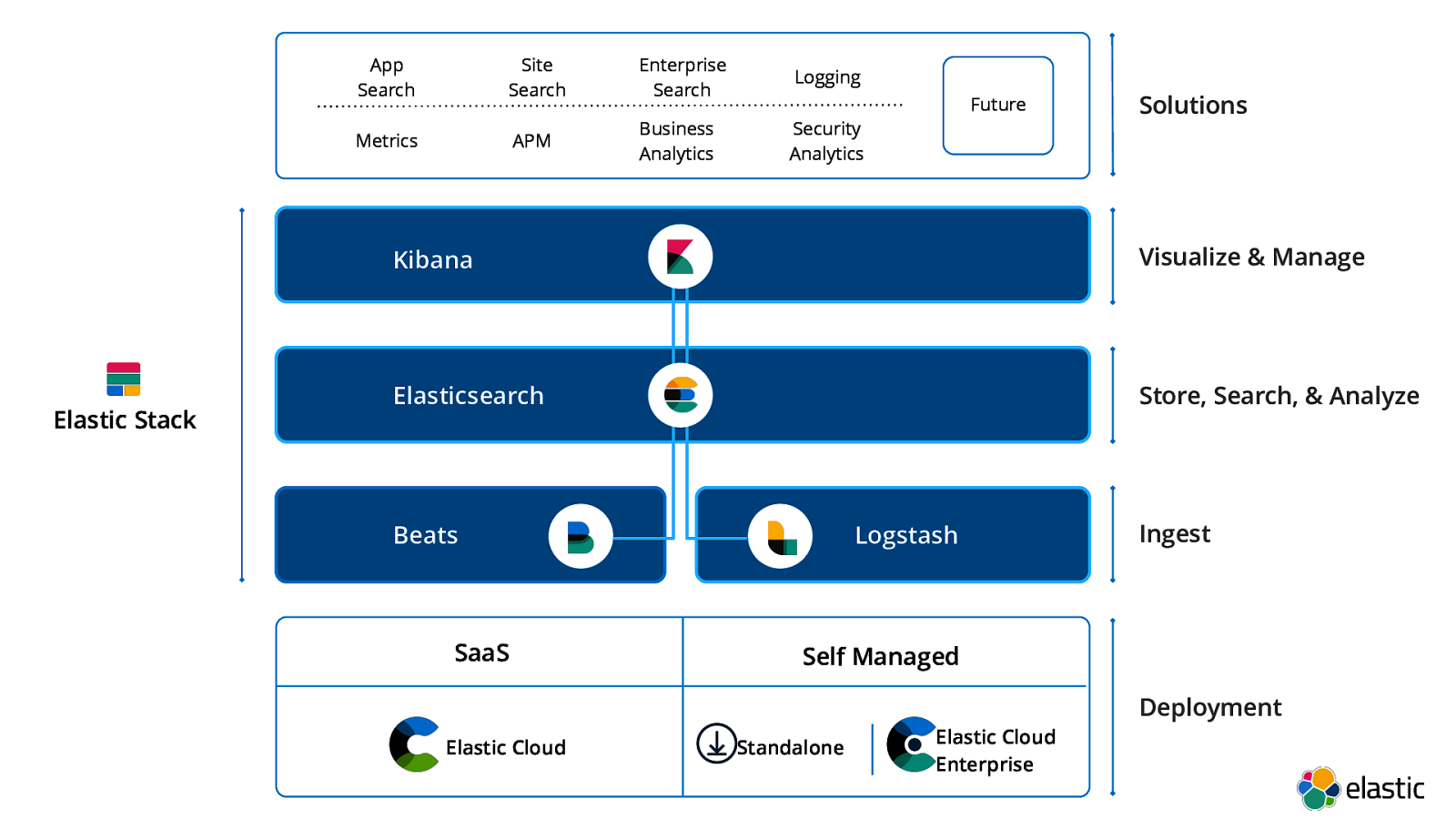
App Search Site Search Enterprise Search Logging APM Business Analytics Security Analytics Metrics Elastic Stack Future Solutions Kibana Visualize & Manage Elasticsearch Store, Search, & Analyze Beats SaaS Elastic Cloud Logstash Ingest Self Managed Standalone Elastic Cloud Enterprise Deployment
Slide 11

Elasticsearch Cluster Sizing
Slide 12
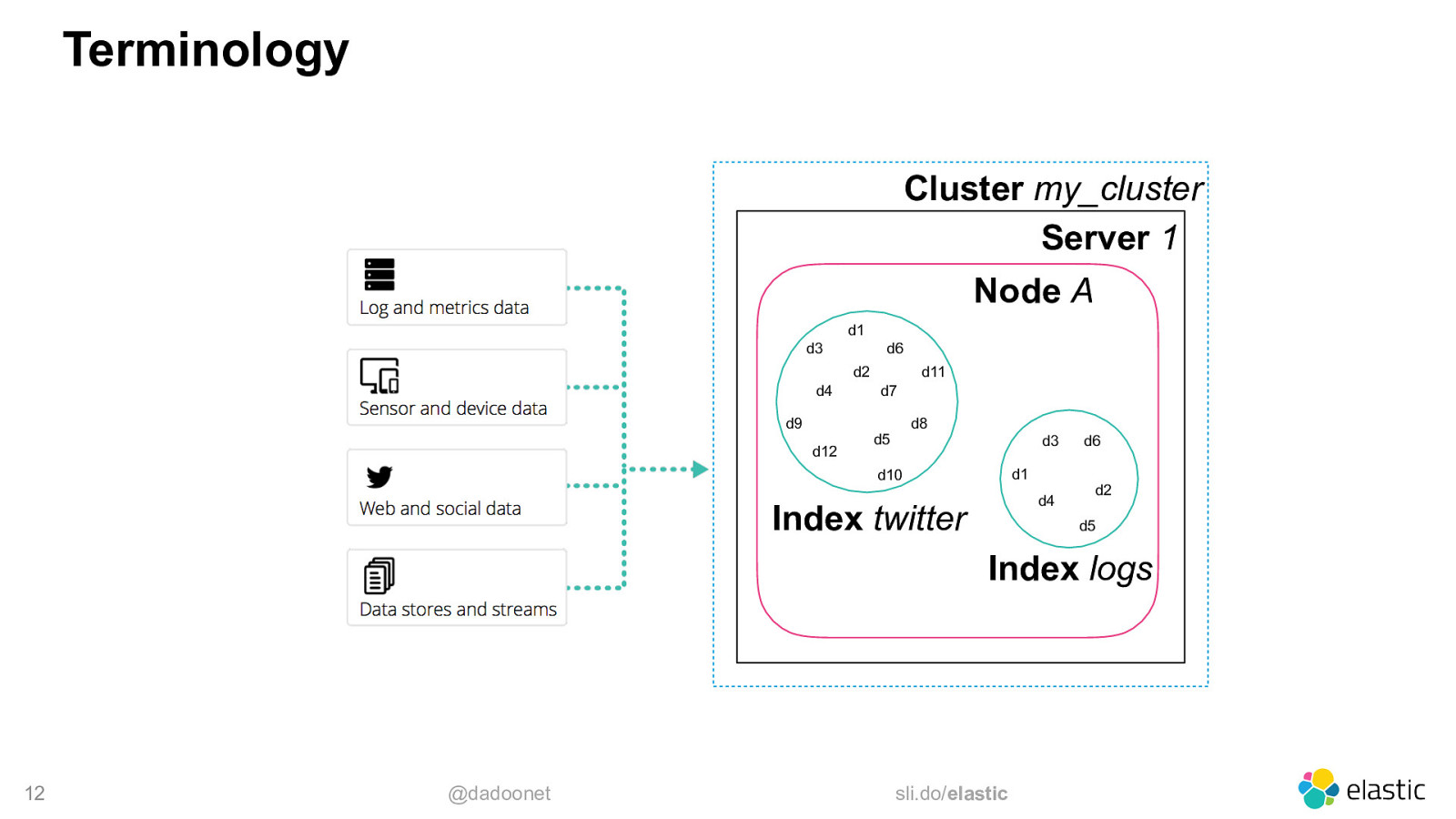
Terminology Cluster my_cluster Server 1 Node A d1 d3 d6 d2 d4 d9 d12 d11 d7 d8 d5 d3 d1 d10 d4 Index twitter d6 d2 d5 Index logs 12 @dadoonet sli.do/elastic
Slide 13
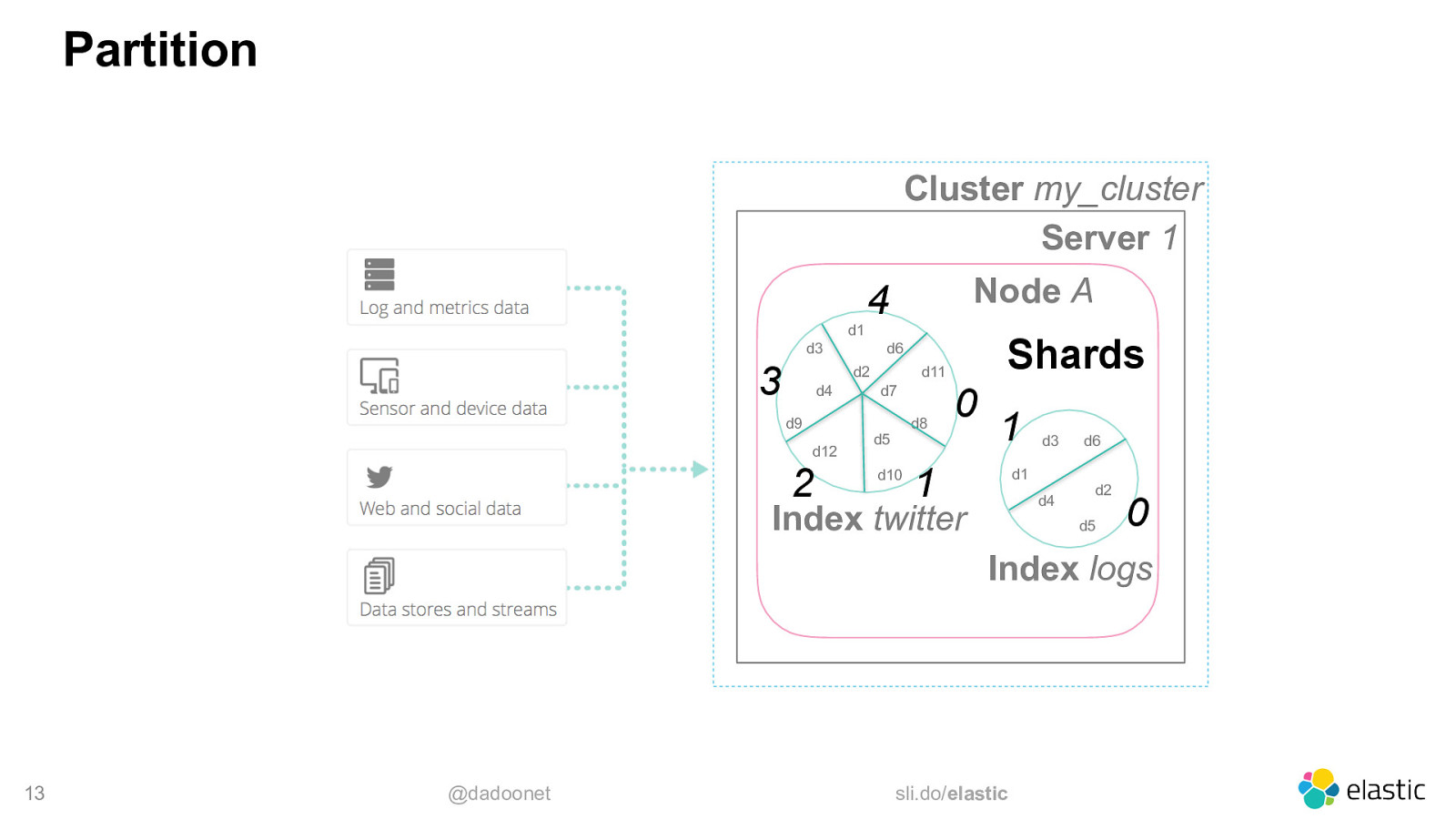
Partition Cluster my_cluster Server 1 d1 4 d3 3 Node A d2 d4 d9 d12 2 Shards d6 d11 d7 d8 d5 d10 0 1 1 d3 d1 d4 Index twitter d6 d2 d5 0 Index logs 13 @dadoonet sli.do/elastic
Slide 14
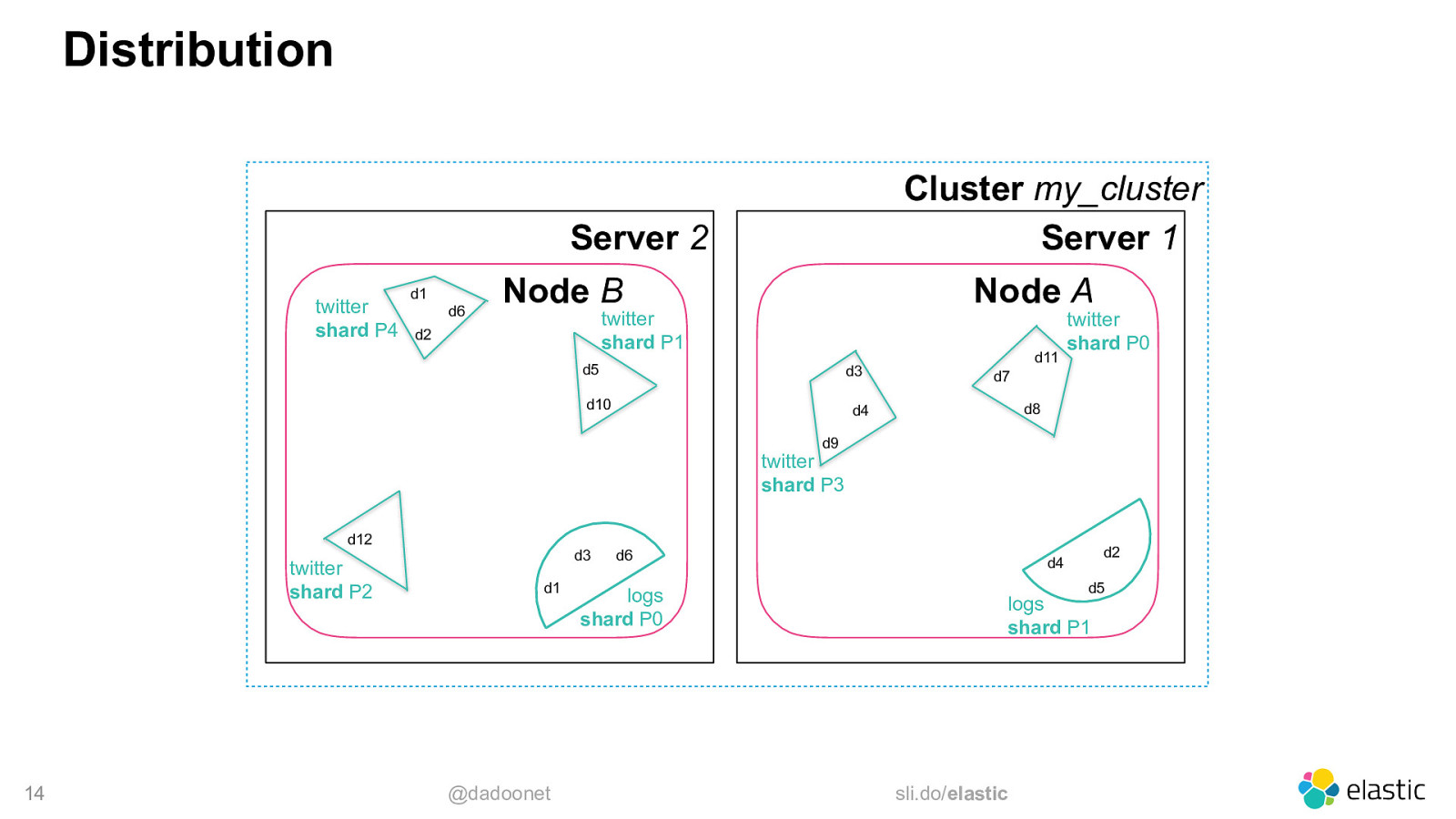
Distribution Cluster my_cluster Server 1 Server 2 twitter shard P4 d1 d6 Node B Node A twitter shard P1 d2 d5 d3 d10 d11 twitter shard P0 d7 d8 d4 d9 twitter shard P3 d12 twitter shard P2 14 d3 d1 @dadoonet d6 logs shard P0 d2 d4 d5 logs shard P1 sli.do/elastic
Slide 15
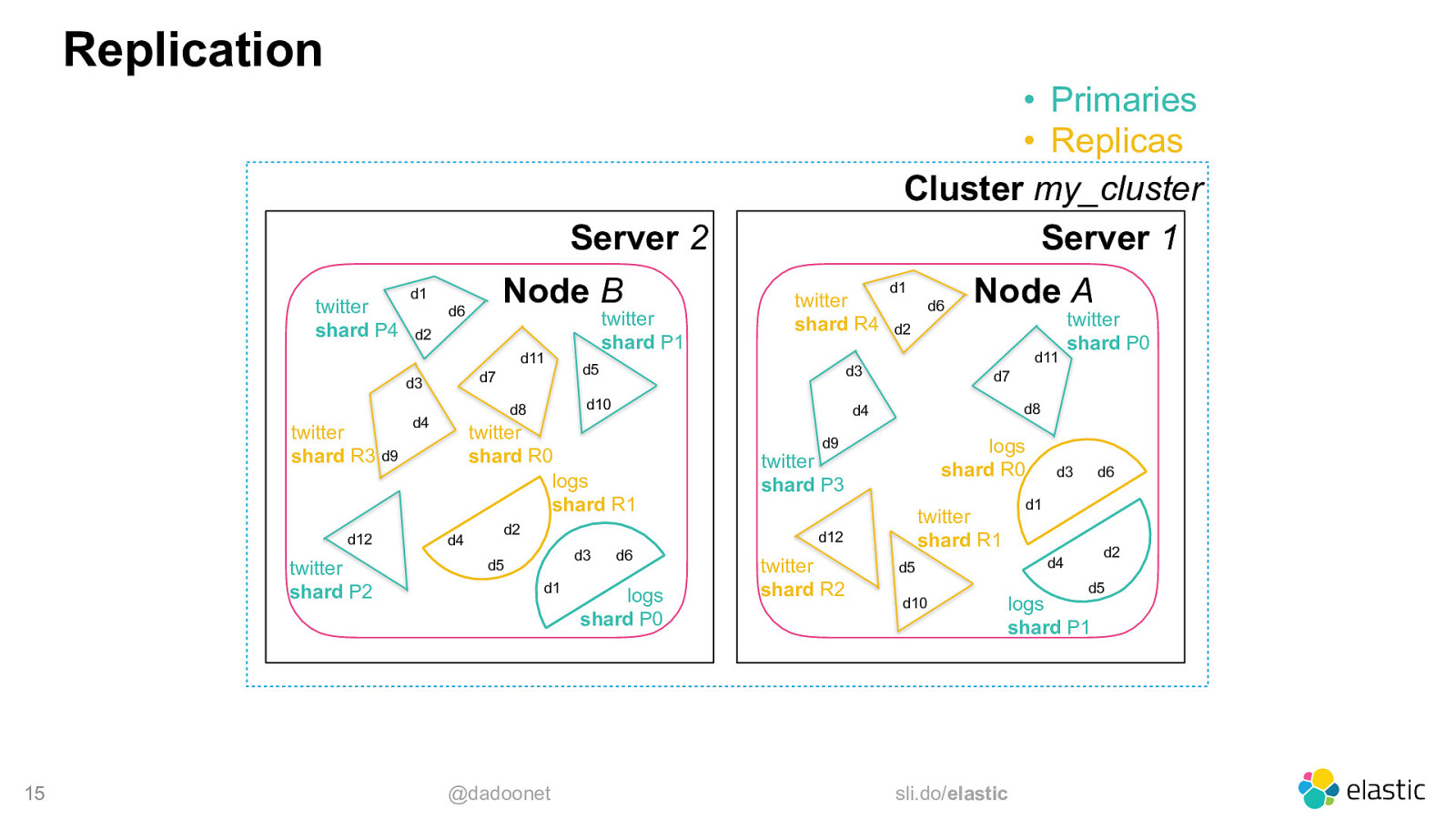
Replication • Primaries • Replicas Cluster my_cluster Server 1 Server 2 twitter shard P4 Node B d1 d6 d2 d11 d7 d3 twitter shard R3 d9 d12 twitter shard P2 15 twitter shard P1 d5 d2 d2 d11 d5 d1 @dadoonet d6 d8 d9 logs shard R0 twitter shard P3 logs shard P0 twitter shard R2 twitter shard P0 d7 d6 d2 d4 d5 d10 d3 d1 twitter shard R1 d12 d3 Node A d4 twitter shard R0 logs shard R1 d4 d6 d3 d10 d8 d4 twitter shard R4 d1 d5 logs shard P1 sli.do/elastic
Slide 16
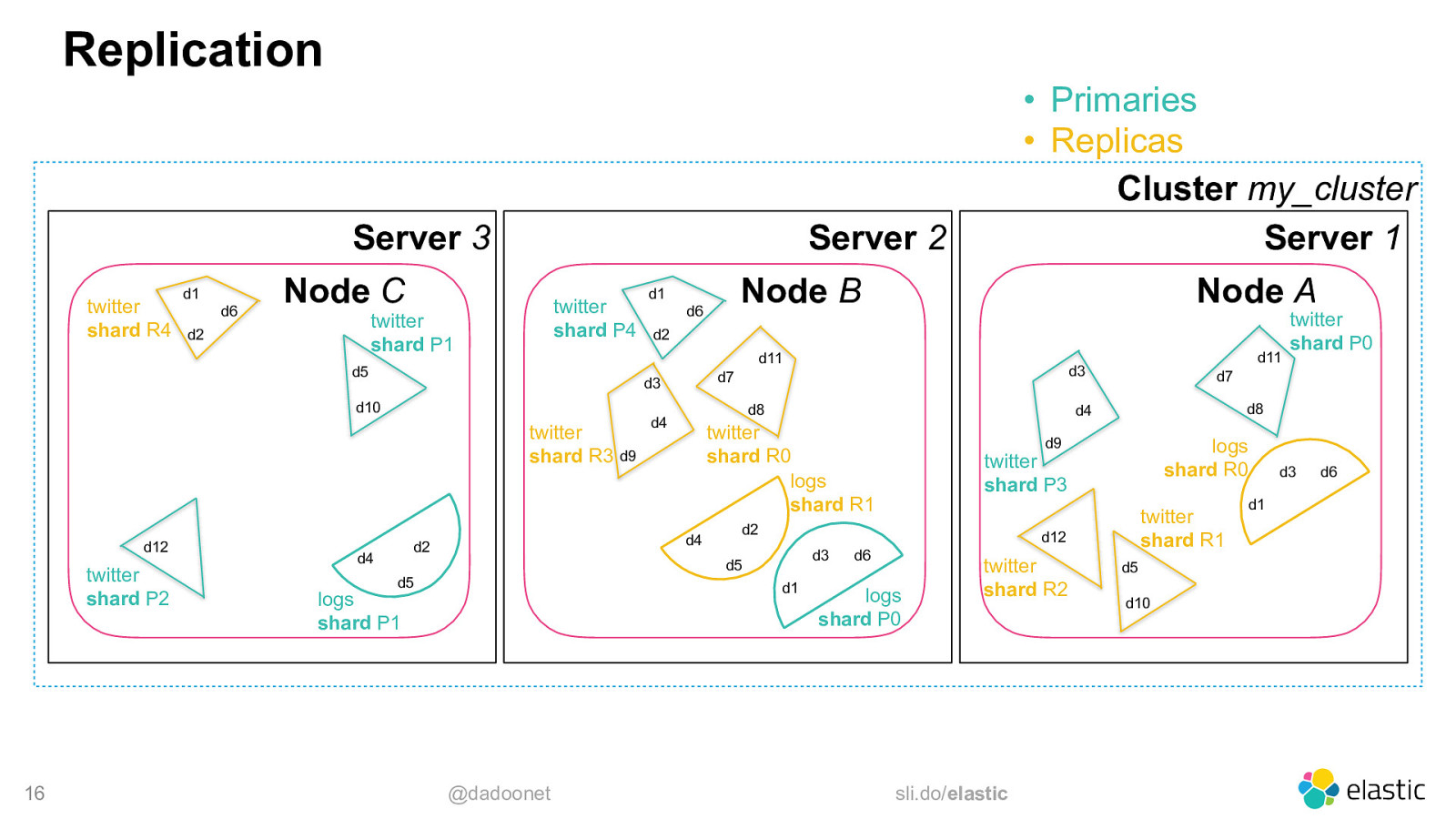
Replication Server 3 twitter shard R4 d1 d6 Server 2 Node C twitter shard P4 twitter shard P1 d2 d10 twitter shard R3 d9 twitter shard P2 16 d6 Node A d2 d8 d4 d2 d3 d1 logs shard P1 @dadoonet logs shard R0 twitter shard P3 twitter shard R1 d12 d5 d5 d8 d9 d2 d6 logs shard P0 twitter shard R2 sli.do/elastic twitter shard P0 d7 d4 twitter shard R0 logs shard R1 d4 d11 d3 d7 d3 d4 Node B d1 d11 d5 d12 • Primaries • Replicas Cluster my_cluster Server 1 d5 d10 d1 d3 d6
Slide 17

Scaling Data 17 @dadoonet sli.do/elastic
Slide 18

Scaling Data 18 @dadoonet sli.do/elastic
Slide 19
Scaling Data 19 @dadoonet sli.do/elastic
Slide 20
Scaling Big Data … 20 @dadoonet … sli.do/elastic
Slide 21
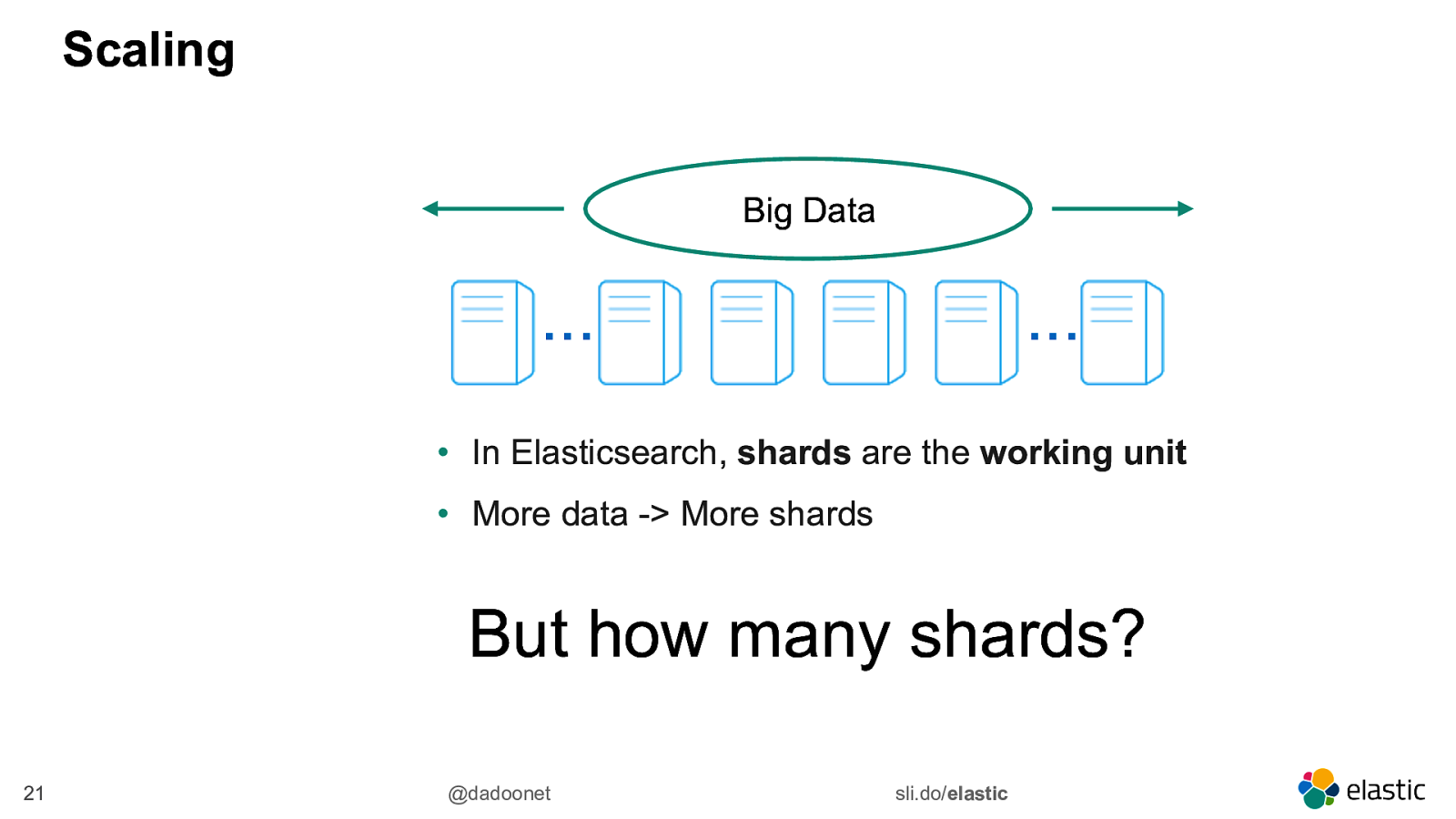
Scaling Big Data … … • In Elasticsearch, shards are the working unit • More data -> More shards But how many shards? 21 @dadoonet sli.do/elastic
Slide 22

How much data? • ~1000 events per second • 60s * 60m * 24h * 1000 events => ~87M events per day • 1kb per event => ~82GB per day • 3 months => ~7TB 22 @dadoonet sli.do/elastic
Slide 23

Shard Size • It depends on many different factors ‒ document size, mapping, use case, kinds of queries being executed, desired response time, peak indexing rate, budget, … • After the shard sizing*, each shard should handle 45GB • Up to 10 shards per machine
- https://www.elastic.co/elasticon/conf/2016/sf/quantitative-cluster-sizing 23 @dadoonet sli.do/elastic
Slide 24
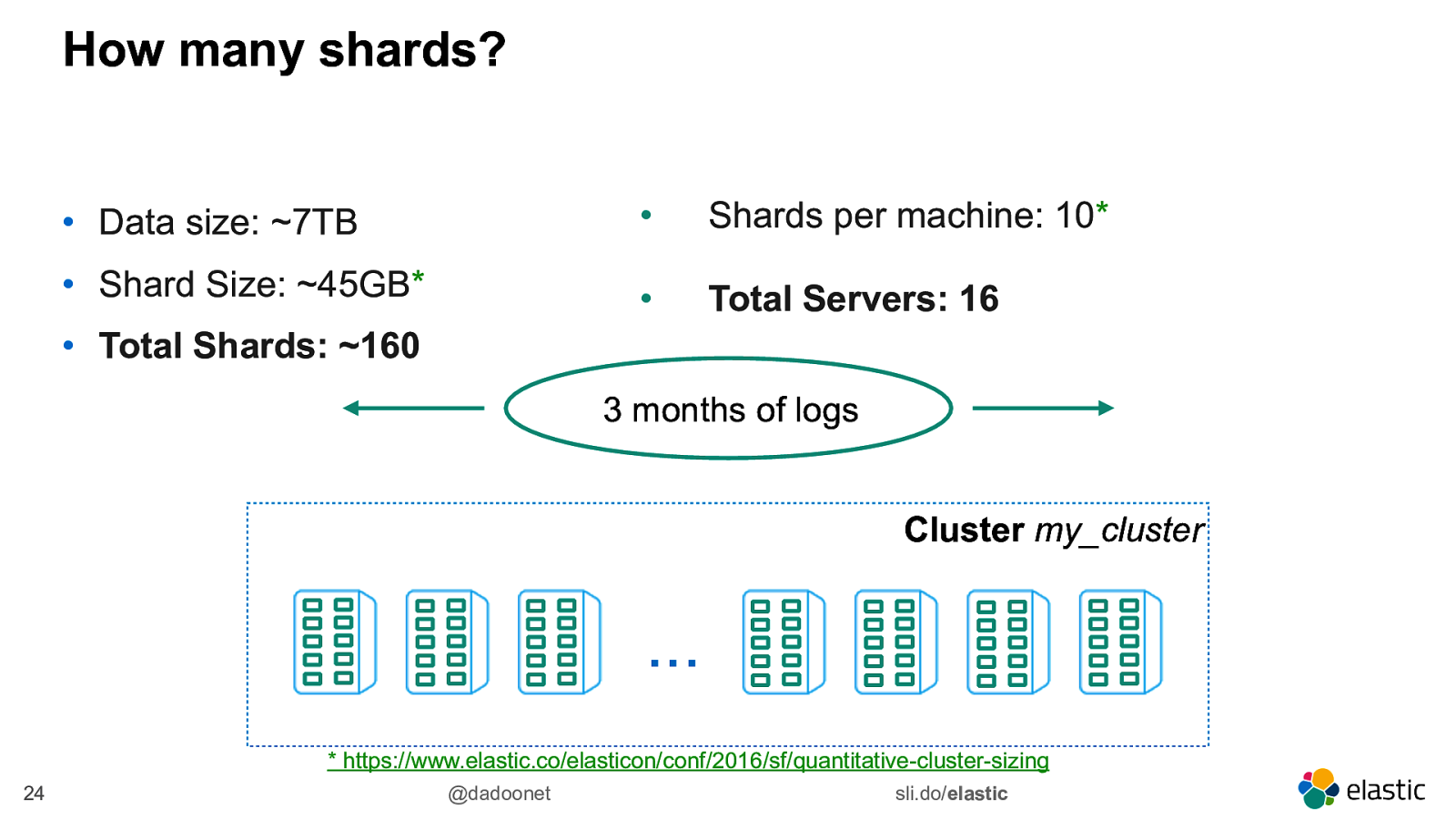
How many shards? • Data size: ~7TB • Shards per machine: 10* • Shard Size: ~45GB* • Total Servers: 16 • Total Shards: ~160 3 months of logs Cluster my_cluster … * https://www.elastic.co/elasticon/conf/2016/sf/quantitative-cluster-sizing 24 @dadoonet sli.do/elastic
Slide 25

But… • How many indices? • What do you do if the daily data grows? • What do you do if you want to delete old data? 25 @dadoonet sli.do/elastic
Slide 26

Time-Based Data • Logs, social media streams, time-based events • Timestamp + Data • Do not change • Typically search for recent events • Older documents become less important • Hard to predict the data size 26 @dadoonet sli.do/elastic
Slide 27

Time-Based Data • Time-based Indices is the best option ‒ create a new index each day, week, month, year, … ‒ search the indices you need in the same request 27 @dadoonet sli.do/elastic
Slide 28
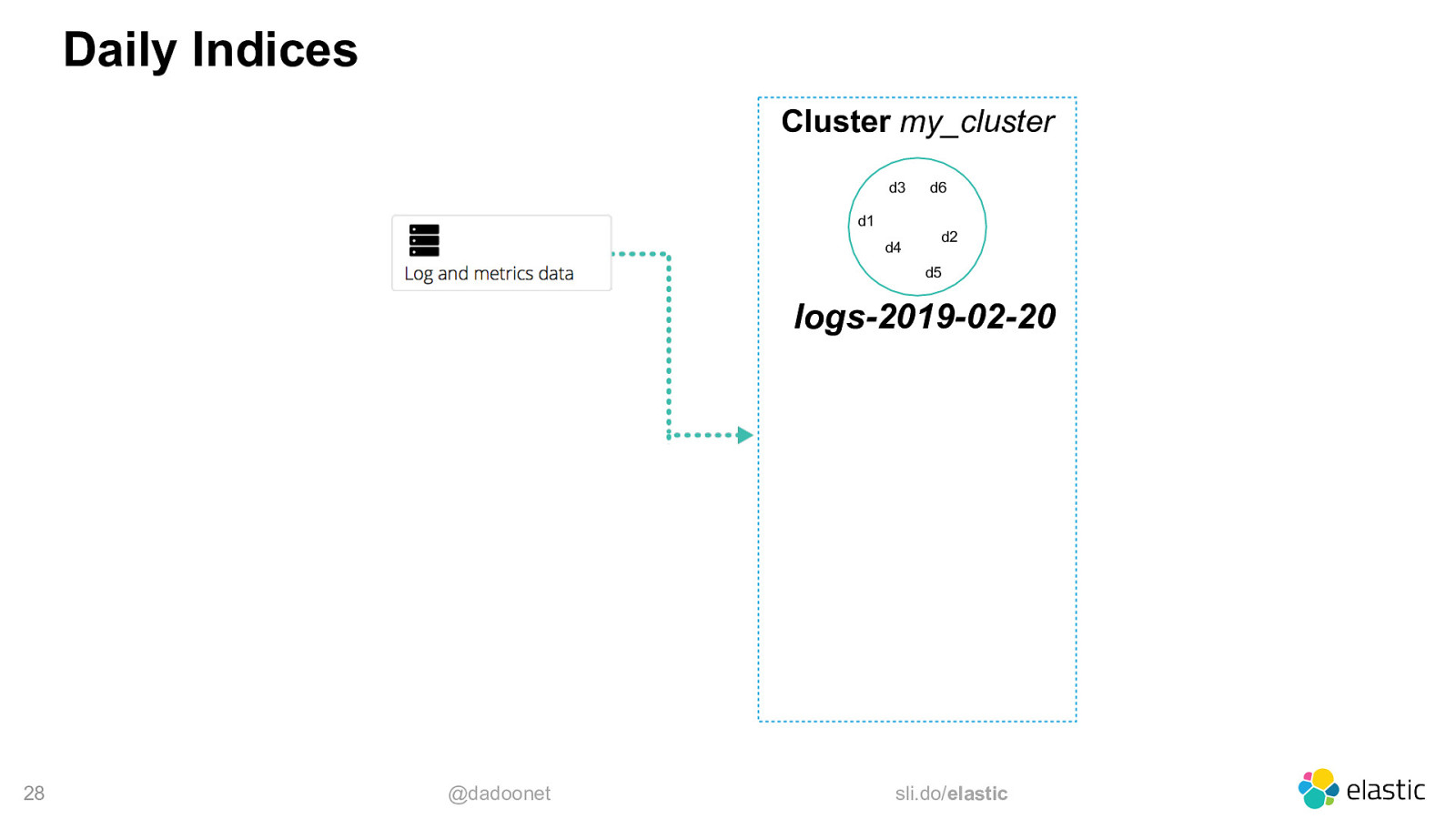
Daily Indices Cluster my_cluster d3 d1 d4 d6 d2 d5 logs-2019-02-20 28 @dadoonet sli.do/elastic
Slide 29
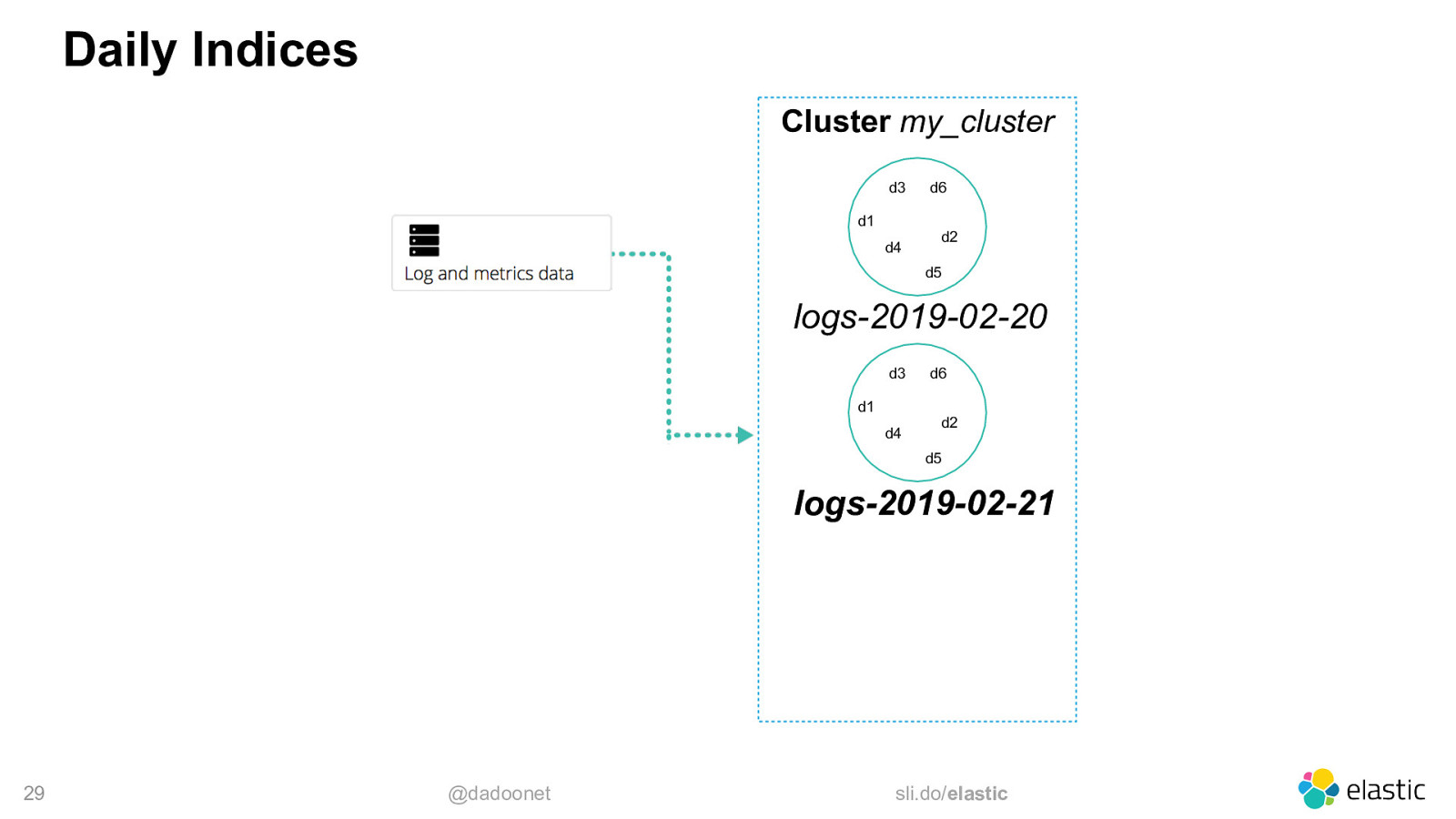
Daily Indices Cluster my_cluster d3 d1 d4 d6 d2 d5 logs-2019-02-20 d3 d1 d4 d6 d2 d5 logs-2019-02-21 29 @dadoonet sli.do/elastic
Slide 30
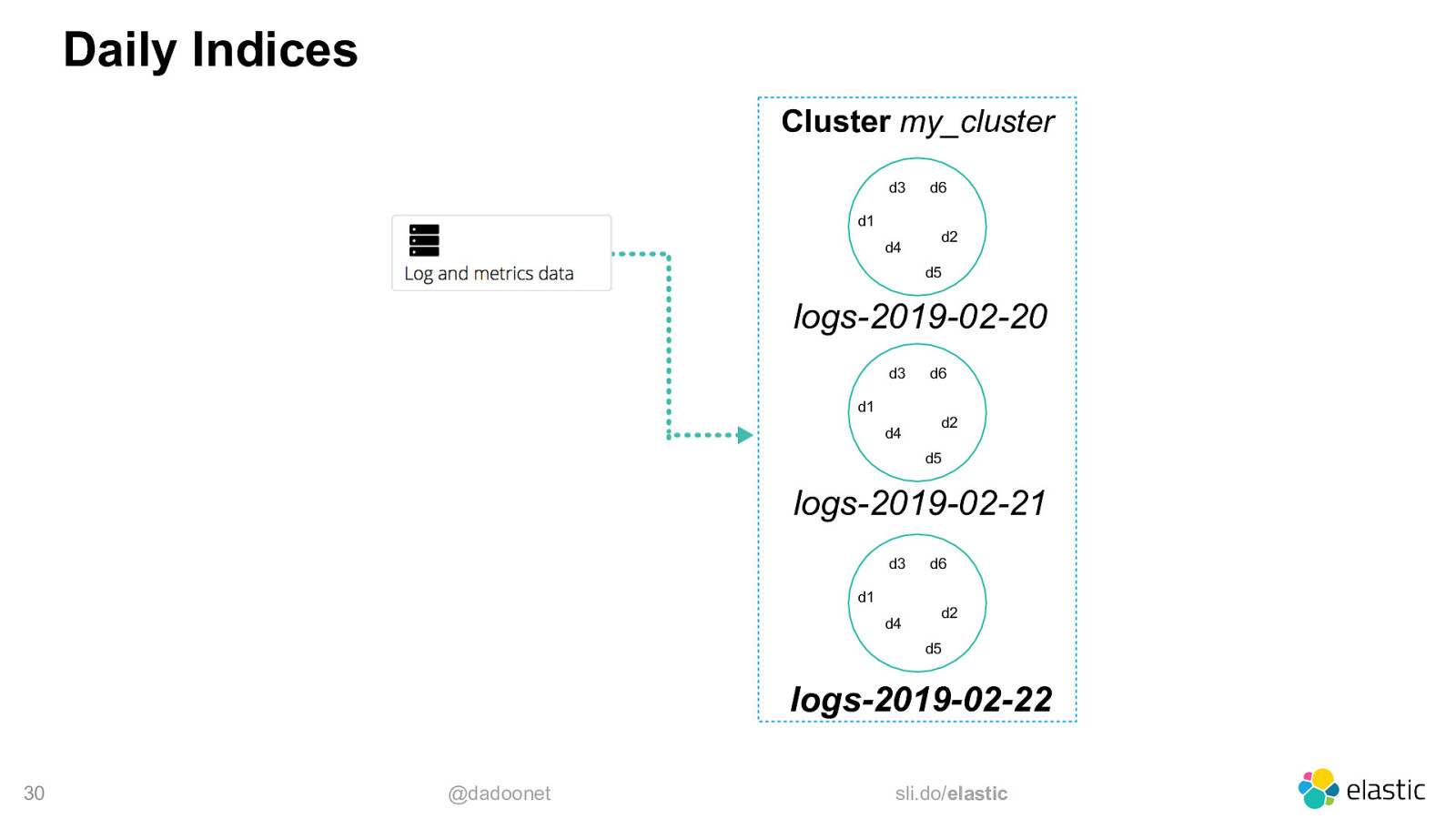
Daily Indices Cluster my_cluster d3 d1 d4 d6 d2 d5 logs-2019-02-20 d3 d1 d4 d6 d2 d5 logs-2019-02-21 d3 d1 d4 d6 d2 d5 logs-2019-02-22 30 @dadoonet sli.do/elastic
Slide 31

Templates • Every new created index starting with ‘logs-’ will have ‒ 2 shards ‒ 1 replica (for each primary shard) ‒ 60 seconds refresh interval PUT _template/logs { “template”: “logs-*”, “settings”: { “number_of_shards”: 2, “number_of_replicas”: 1, “refresh_interval”: “60s” } } More on that later 31 @dadoonet
Slide 32
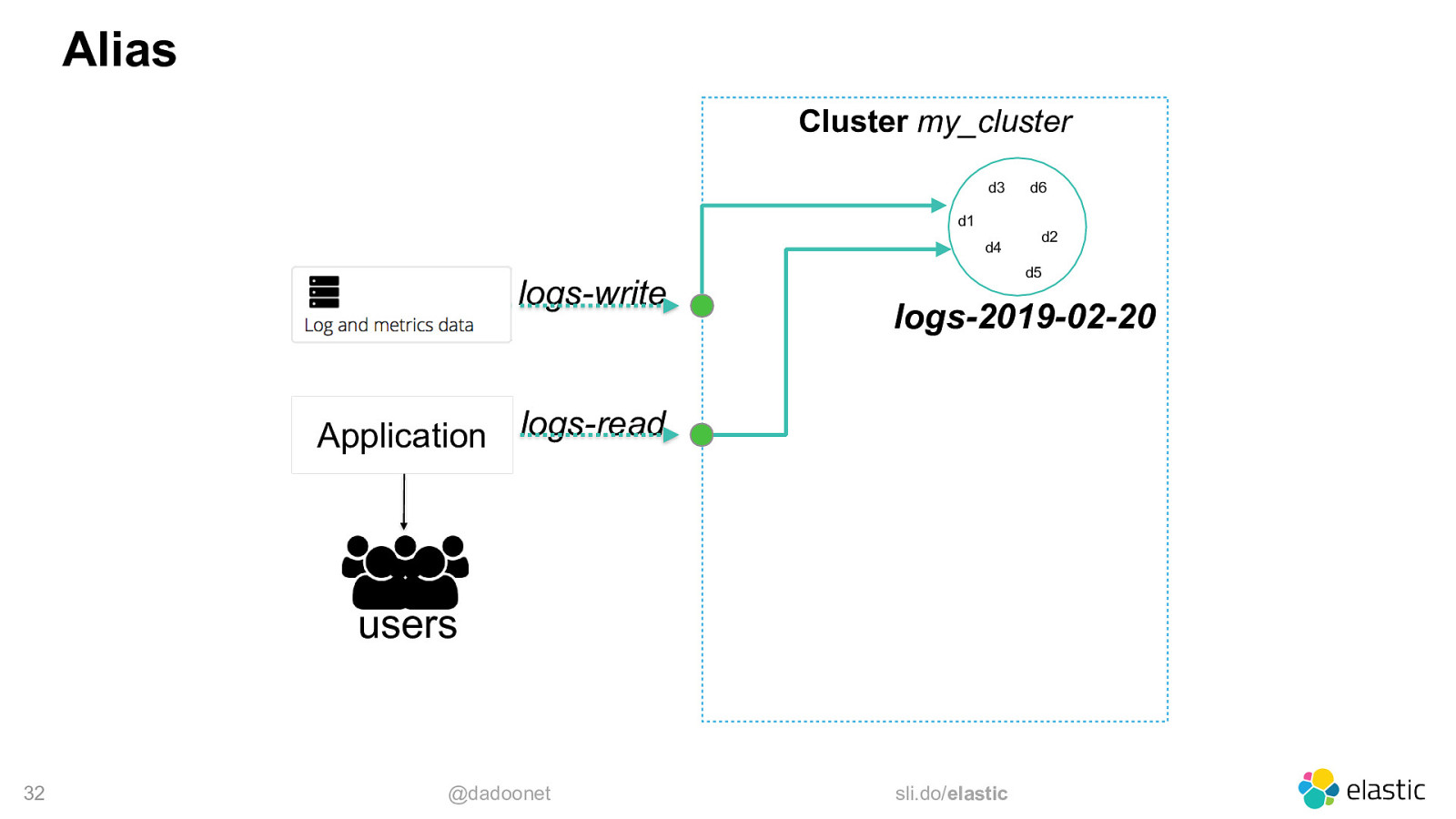
Alias Cluster my_cluster d3 d1 d4 logs-write logs-2019-02-20 users @dadoonet d2 d5 logs-read Application 32 d6 sli.do/elastic
Slide 33
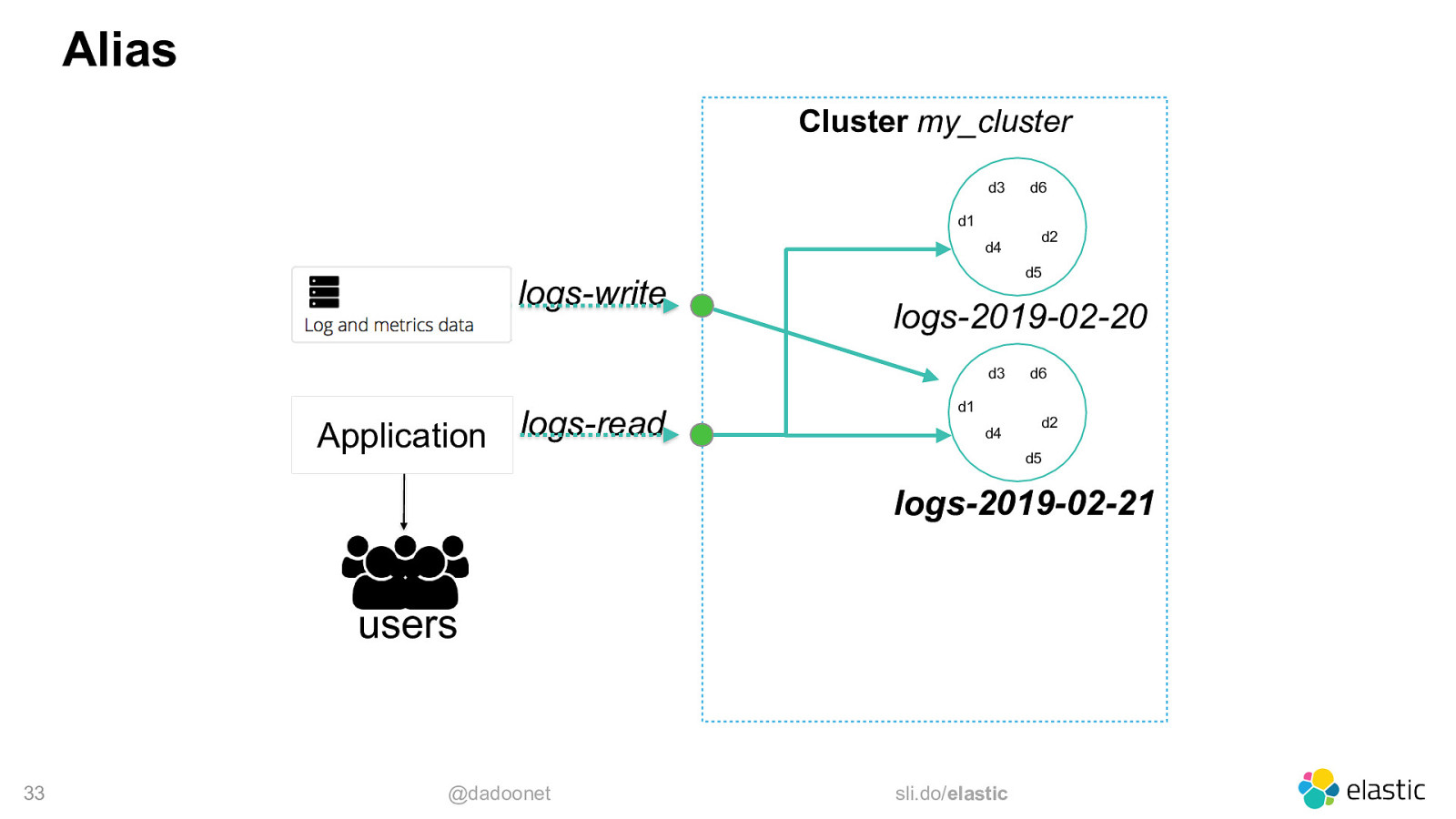
Alias Cluster my_cluster d3 d1 d4 logs-write d2 d5 logs-2019-02-20 d3 logs-read Application d6 d1 d4 d6 d2 d5 logs-2019-02-21 users 33 @dadoonet sli.do/elastic
Slide 34
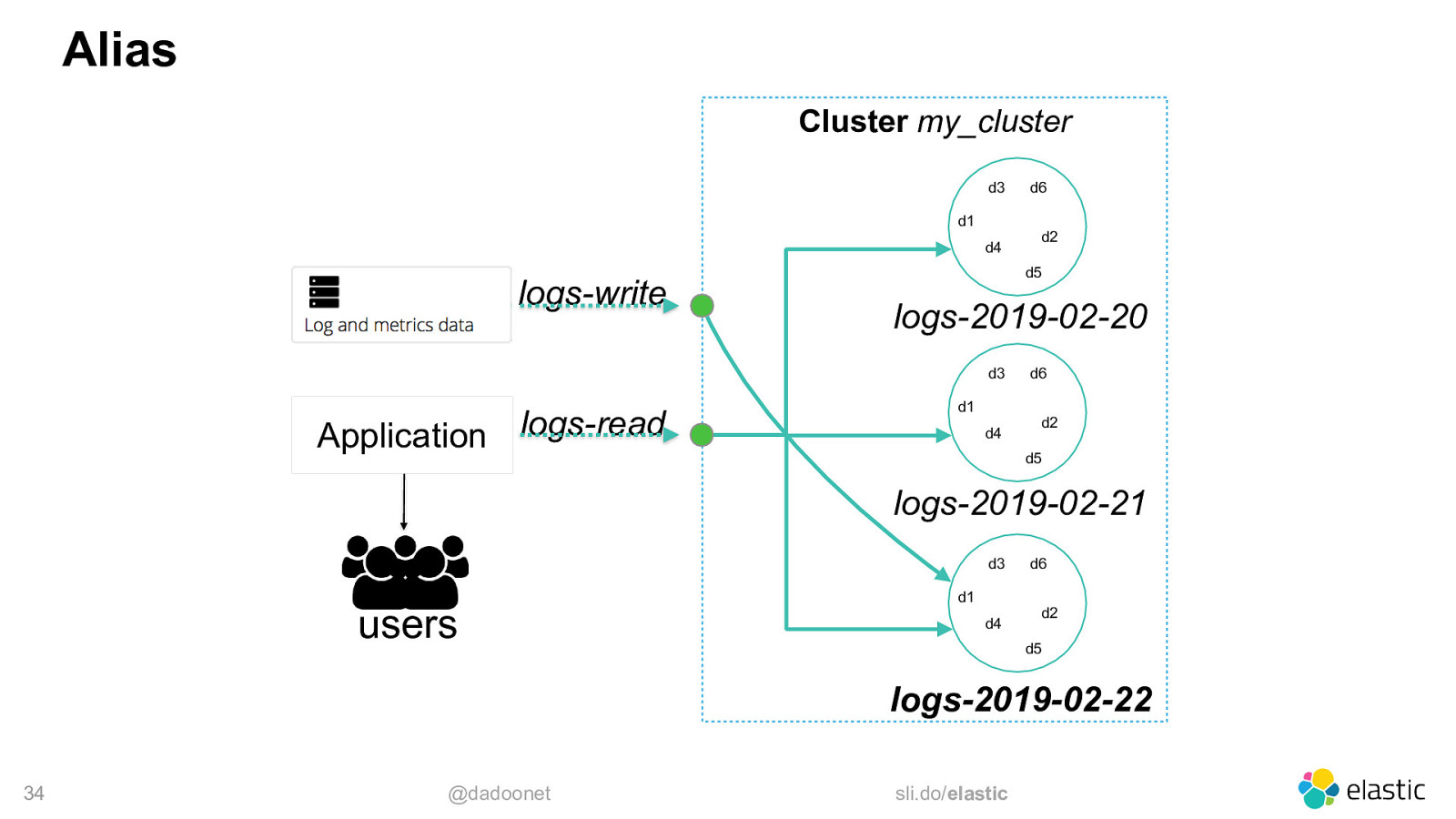
Alias Cluster my_cluster d3 d1 d4 logs-write d2 d5 logs-2019-02-20 d3 logs-read Application d6 d1 d4 d6 d2 d5 logs-2019-02-21 d3 users d1 d4 d6 d2 d5 logs-2019-02-22 34 @dadoonet sli.do/elastic
Slide 35

Detour: Rollover API https://www.elastic.co/guide/en/elasticsearch/reference/6.6/indices-rollover-index.html
Slide 36

Do not Overshard don’t keep default values! Cluster my_cluster d3 d6 d1 • 3 different logs d2 d4 d5 • 1 index per day each access-… • 1GB each d5 • 5 shards (default): so 200mb / shard vs 45gb d1 d7 d6 d9 d5 • 6 months retention application-… • ~900 shards for ~180GB d59 • we needed ~4 shards! d0 d4 d10 d3 d5 mysql-… 36 @dadoonet sli.do/elastic
Slide 37
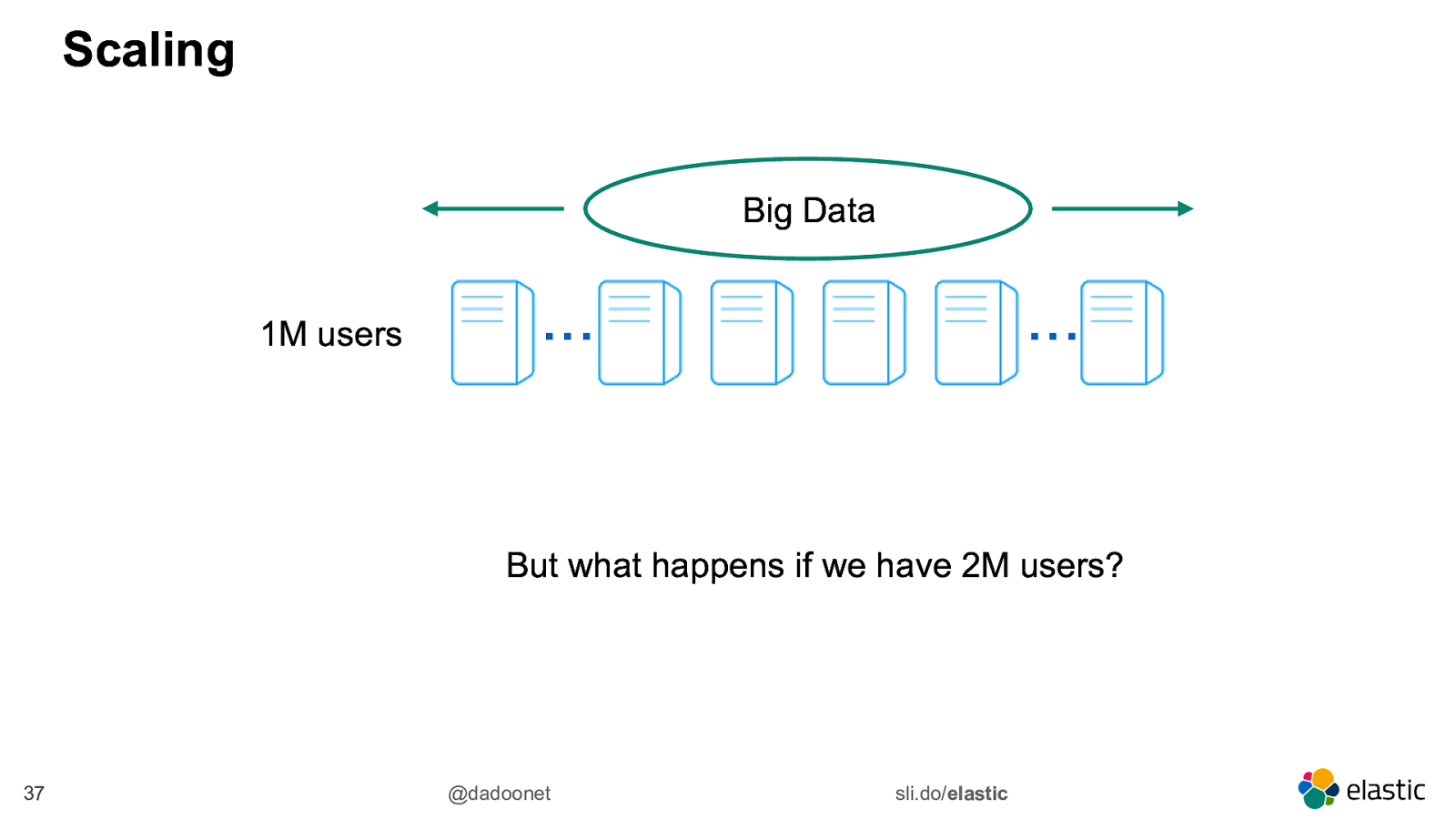
Scaling Big Data 1M users … … But what happens if we have 2M users? 37 @dadoonet sli.do/elastic
Slide 38
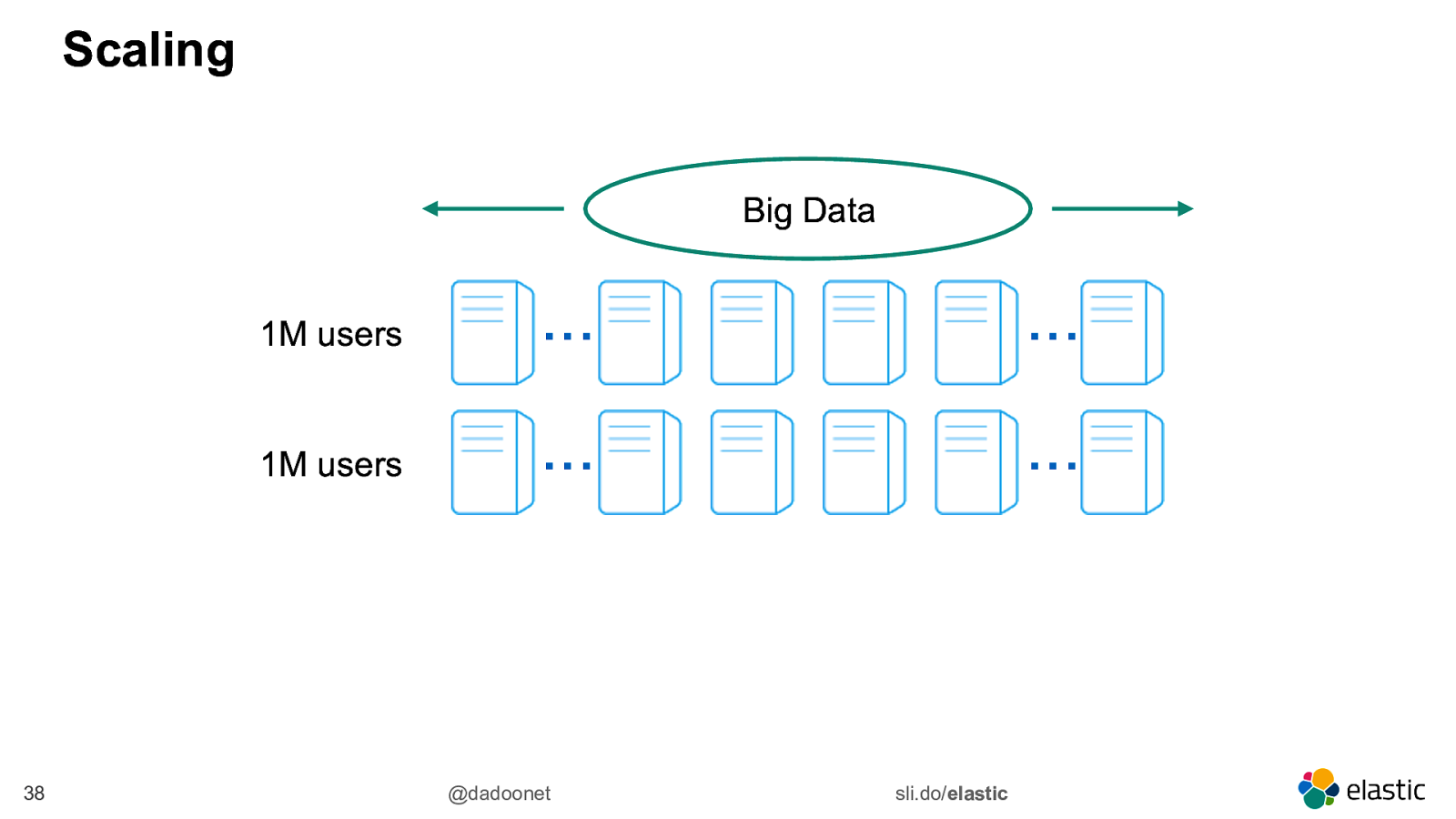
Scaling Big Data 38 1M users … … 1M users … … @dadoonet sli.do/elastic
Slide 39
Scaling Big Data 39 1M users … … 1M users … … 1M users … … @dadoonet sli.do/elastic
Slide 40
Scaling Big Data U s e r s 40 … … … … … … @dadoonet sli.do/elastic
Slide 41

Shards are the working unit • Primaries ‒ More data -> More shards ‒ write throughput (More writes -> More primary shards) • Replicas ‒ high availability (1 replica is the default) ‒ read throughput (More reads -> More replicas) 41 @dadoonet sli.do/elastic
Slide 42

Detour: Shrink API https://www.elastic.co/guide/en/elasticsearch/reference/6.6/indices-shrink-index.html
Slide 43

Detour: Split API https://www.elastic.co/guide/en/elasticsearch/reference/6.6/indices-split-index.html
Slide 44

Optimal Bulk Size
Slide 45
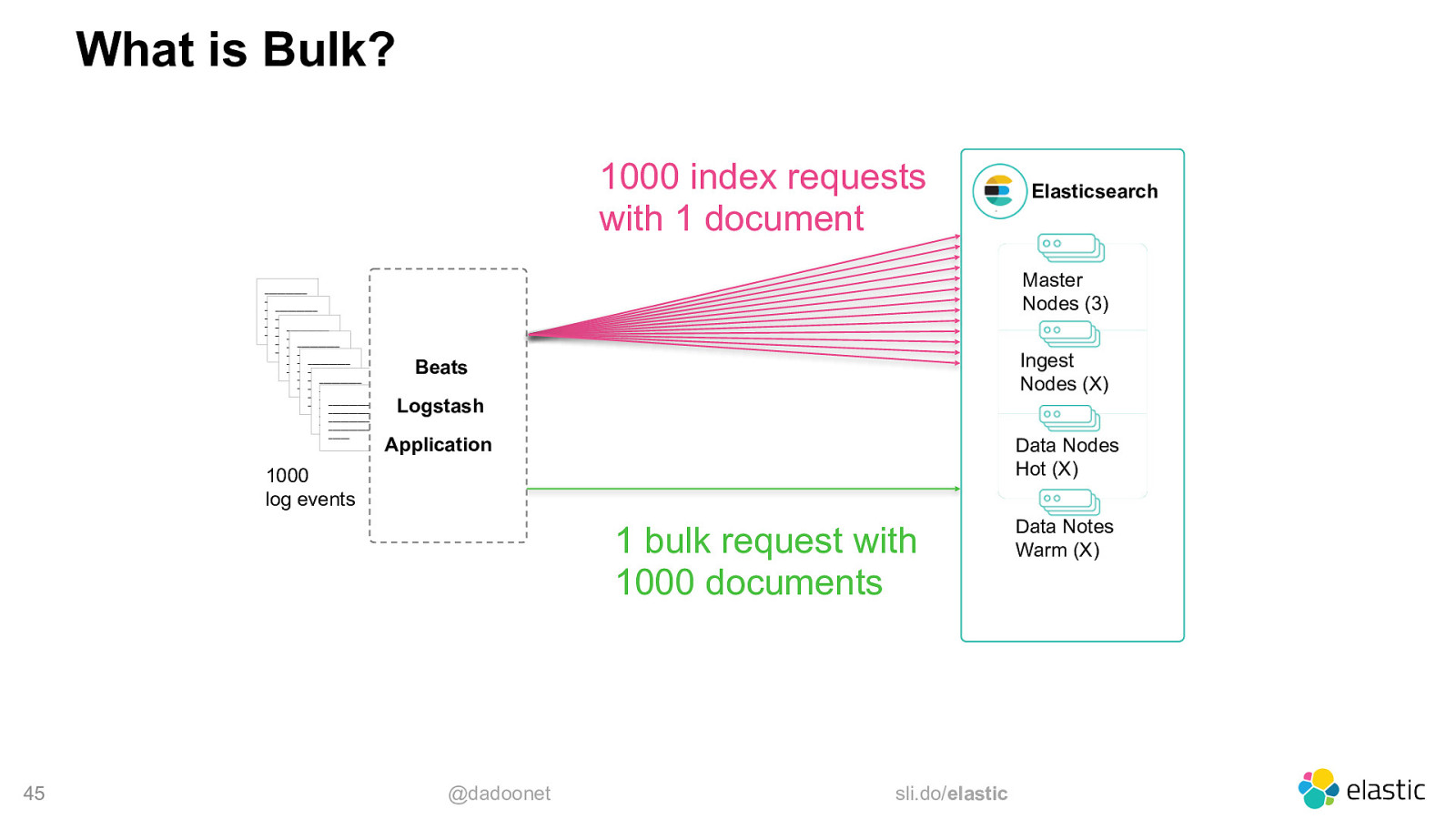
What is Bulk? 1000 index requests with 1 document __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ __________ _____ Master Nodes (3) Ingest Nodes (X) Beats Logstash Application Data Nodes Hot (X) 1000 log events 1 bulk request with 1000 documents 45 Elasticsearch @dadoonet sli.do/elastic Data Notes Warm (X)
Slide 46
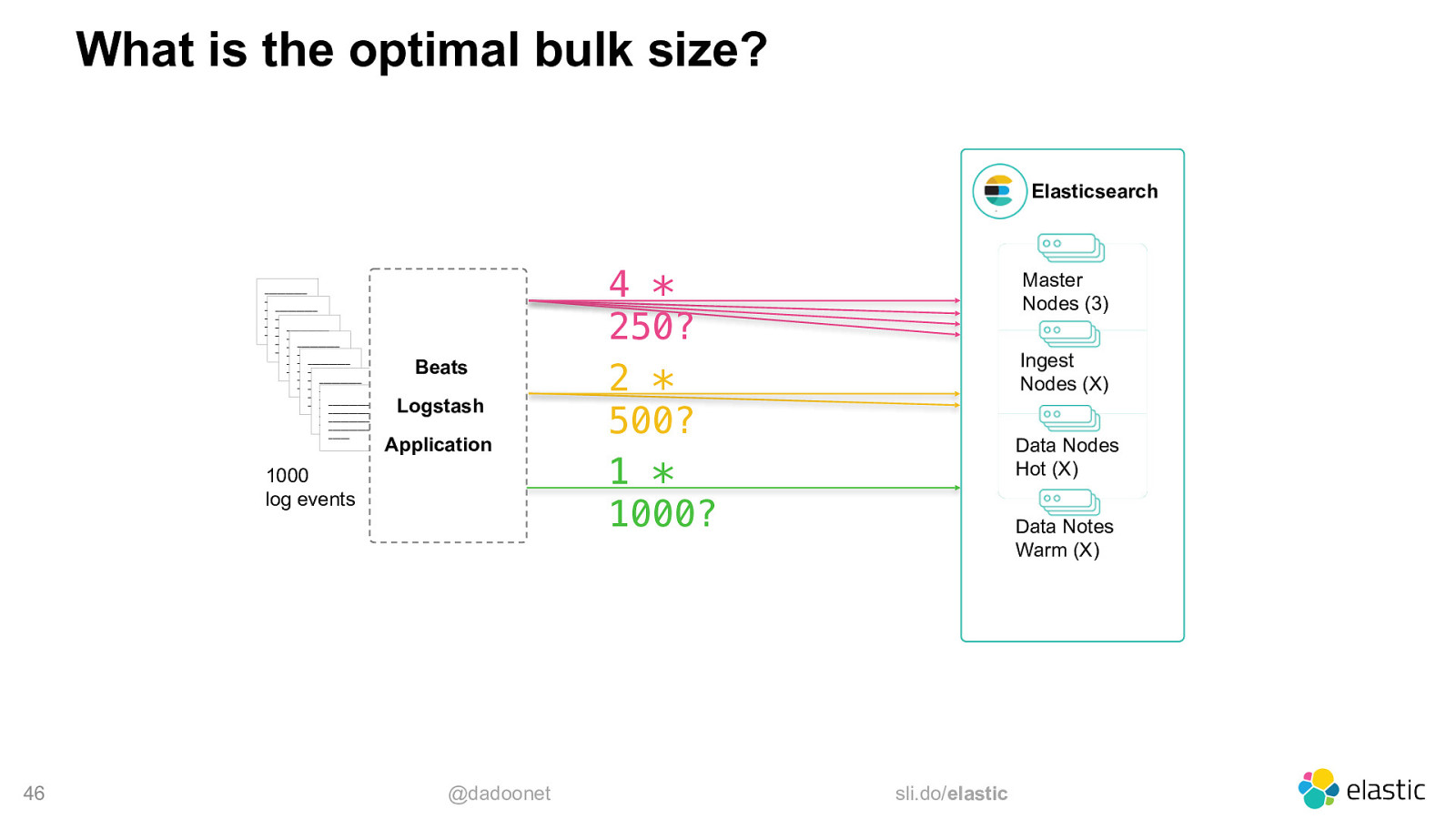
What is the optimal bulk size? Elasticsearch
Beats Logstash Application 1000 log events 46 @dadoonet 4 * 250? 2 * 500? 1 * 1000? Master Nodes (3) Ingest Nodes (X) Data Nodes Hot (X) Data Notes Warm (X) sli.do/elastic
Slide 47

It depends… • on your application (language, libraries, …) • document size (100b, 1kb, 100kb, 1mb, …) • number of nodes • node size • number of shards • shards distribution 47 @dadoonet sli.do/elastic
Slide 48
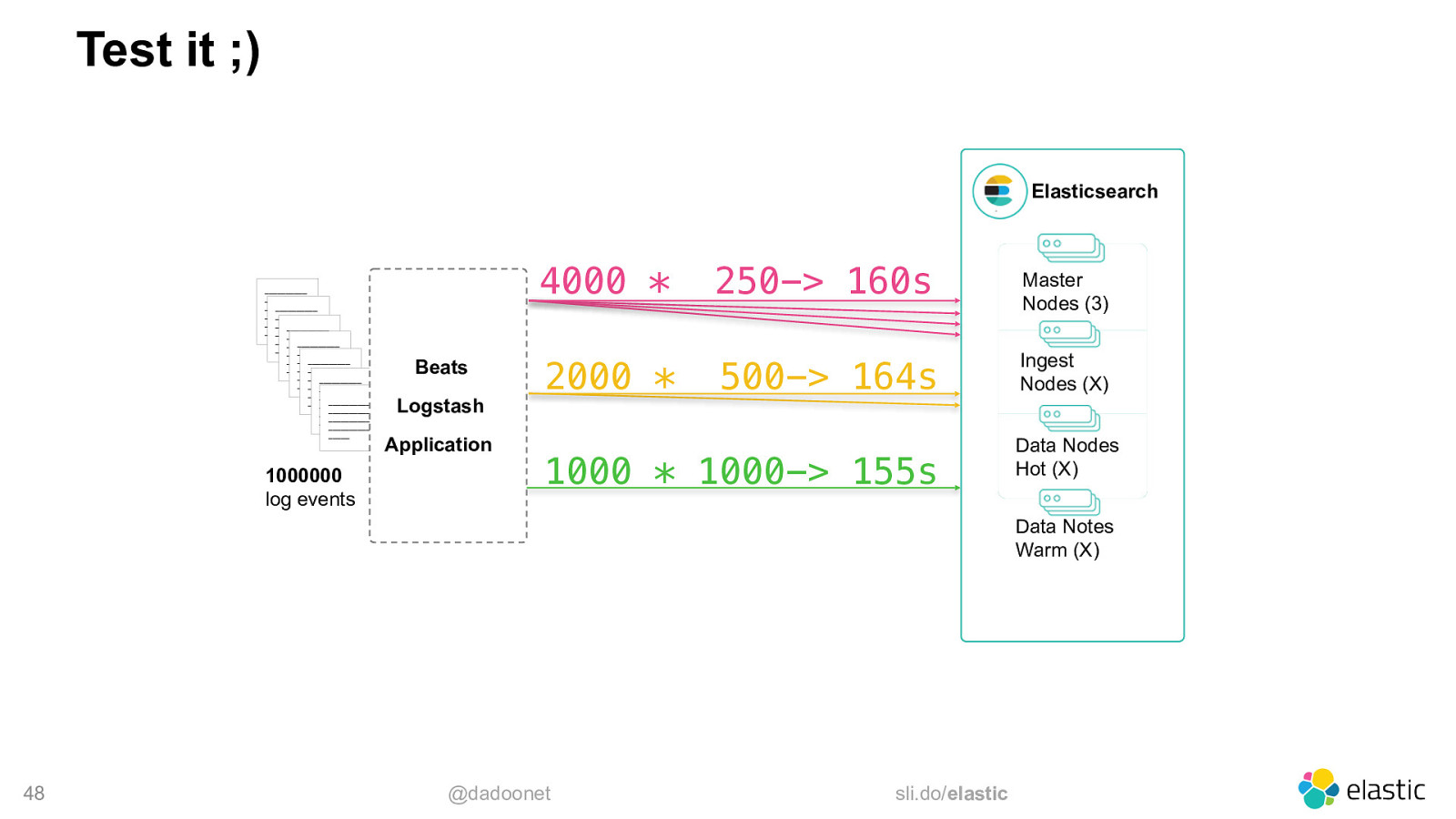
Test it ;) Elasticsearch
1000000 log events 4000 * Beats Logstash Application 2000 * 250-> 160s Master Nodes (3) 500-> 164s Ingest Nodes (X) 1000 * 1000-> 155s Data Nodes Hot (X) Data Notes Warm (X) 48 @dadoonet sli.do/elastic
Slide 49
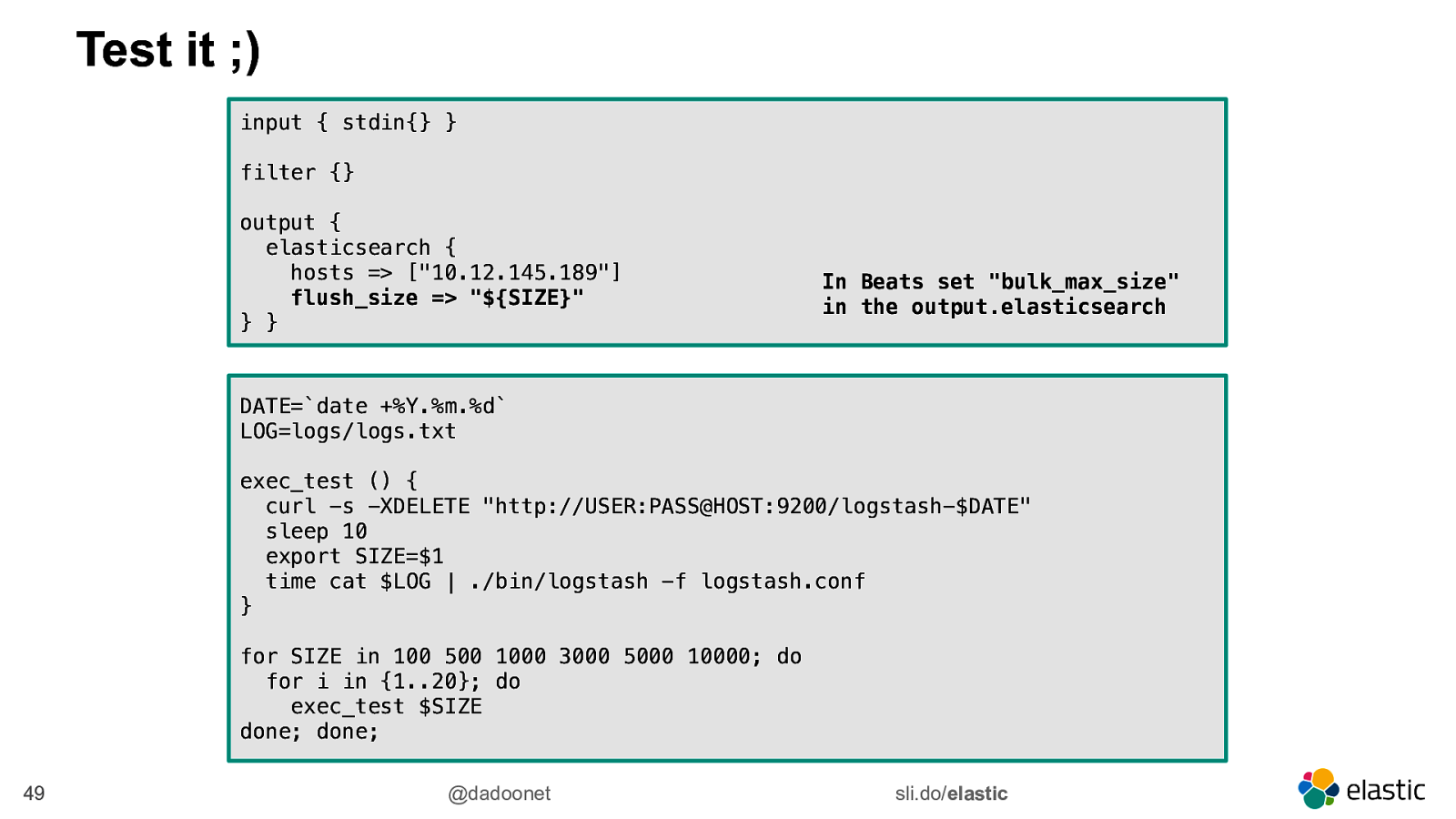
Test it ;) input { stdin{} } filter {} output { elasticsearch { hosts => [“10.12.145.189”] flush_size => “${SIZE}” } }
In Beats set “bulk_max_size” in the output.elasticsearch
DATE=date +%Y.%m.%d LOG=logs/logs.txt exec_test () { curl -s -XDELETE “http://USER:PASS@HOST:9200/logstash-$DATE” sleep 10 export SIZE=$1 time cat $LOG | ./bin/logstash -f logstash.conf } for SIZE in 100 500 1000 3000 5000 10000; do for i in {1..20}; do exec_test $SIZE done; done; 49
@dadoonet
sli.do/elastic
Slide 50

Test it ;) • 2 node cluster (m3.large) ‒ 2 vCPU, 7.5GB Memory, 1x32GB SSD • 1 index server (m3.large) ‒ logstash ‒ kibana 50
docs
100 500 1000 3000 5000 10000 time(s) 191.7 161.9 163.5 160.7 160.7 161.5 @dadoonet
Slide 51

Distribute the Load
Slide 52
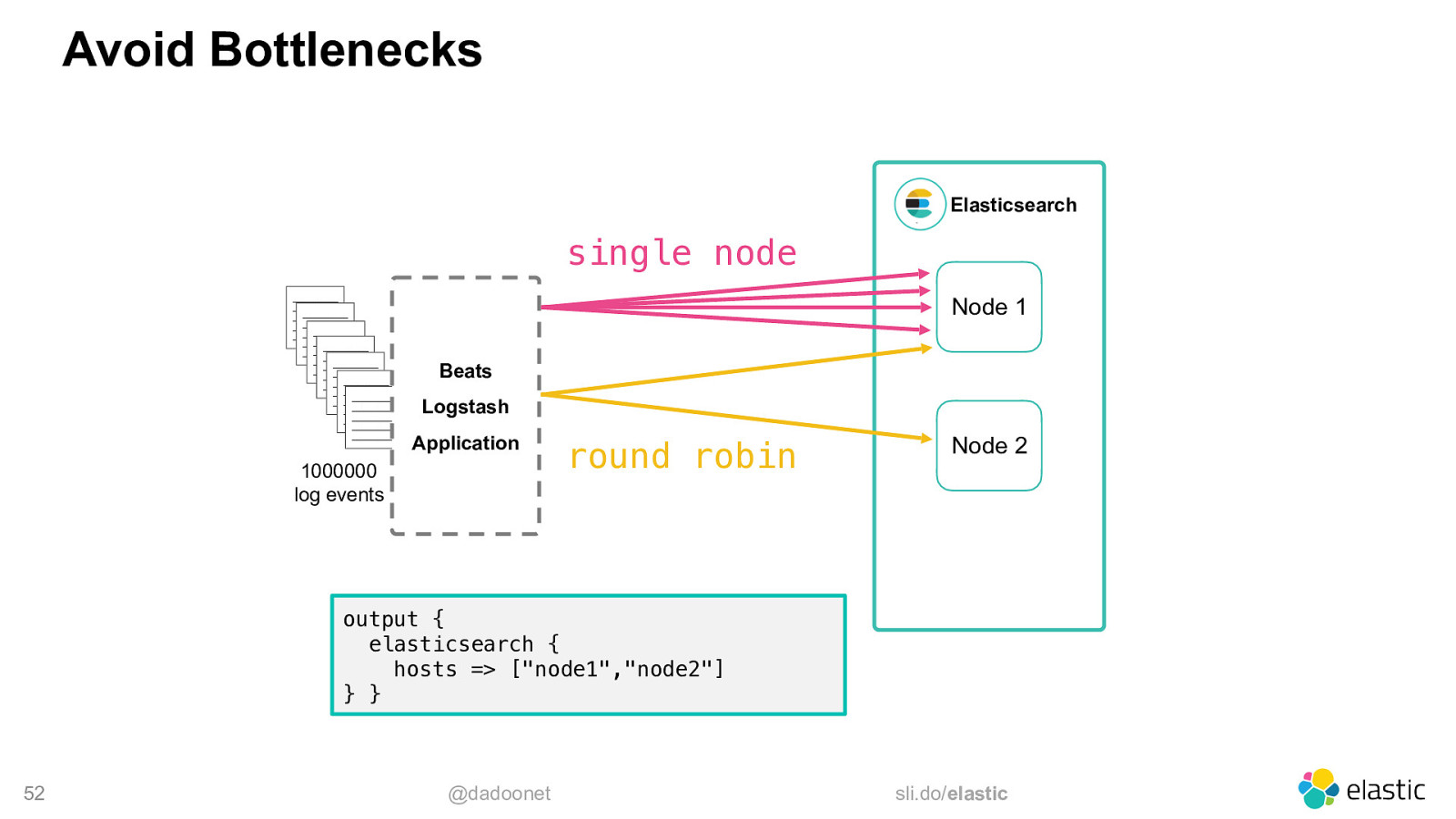
Avoid Bottlenecks Elasticsearch single node _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ Node 1 Beats Logstash Application 1000000 log events round robin Node 2 output { elasticsearch { hosts => [“node1”,”node2”] } } 52 @dadoonet sli.do/elastic
Slide 53
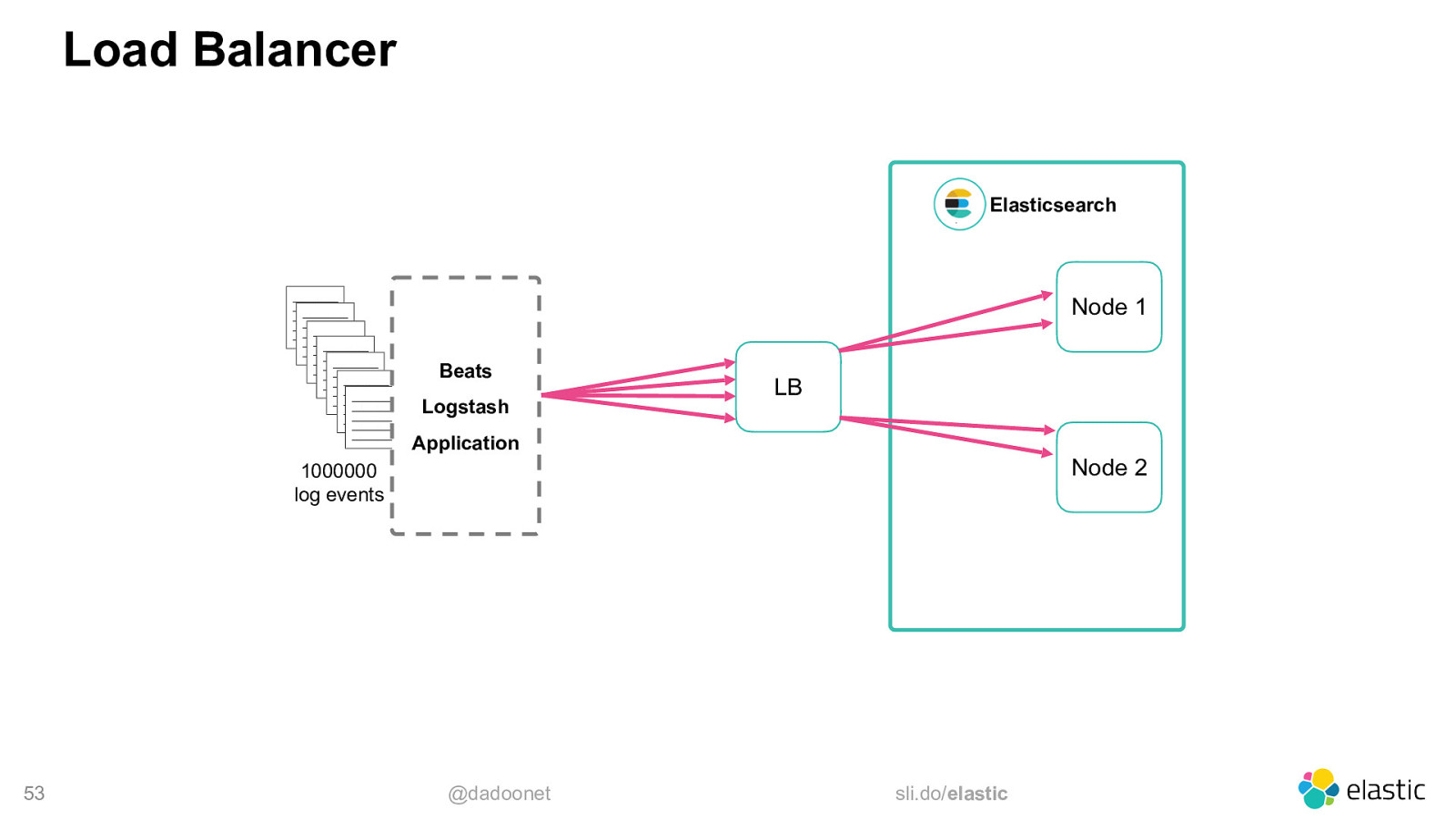
Load Balancer Elasticsearch
Node 1 Beats Logstash LB Application Node 2 1000000 log events 53 @dadoonet sli.do/elastic
Slide 54
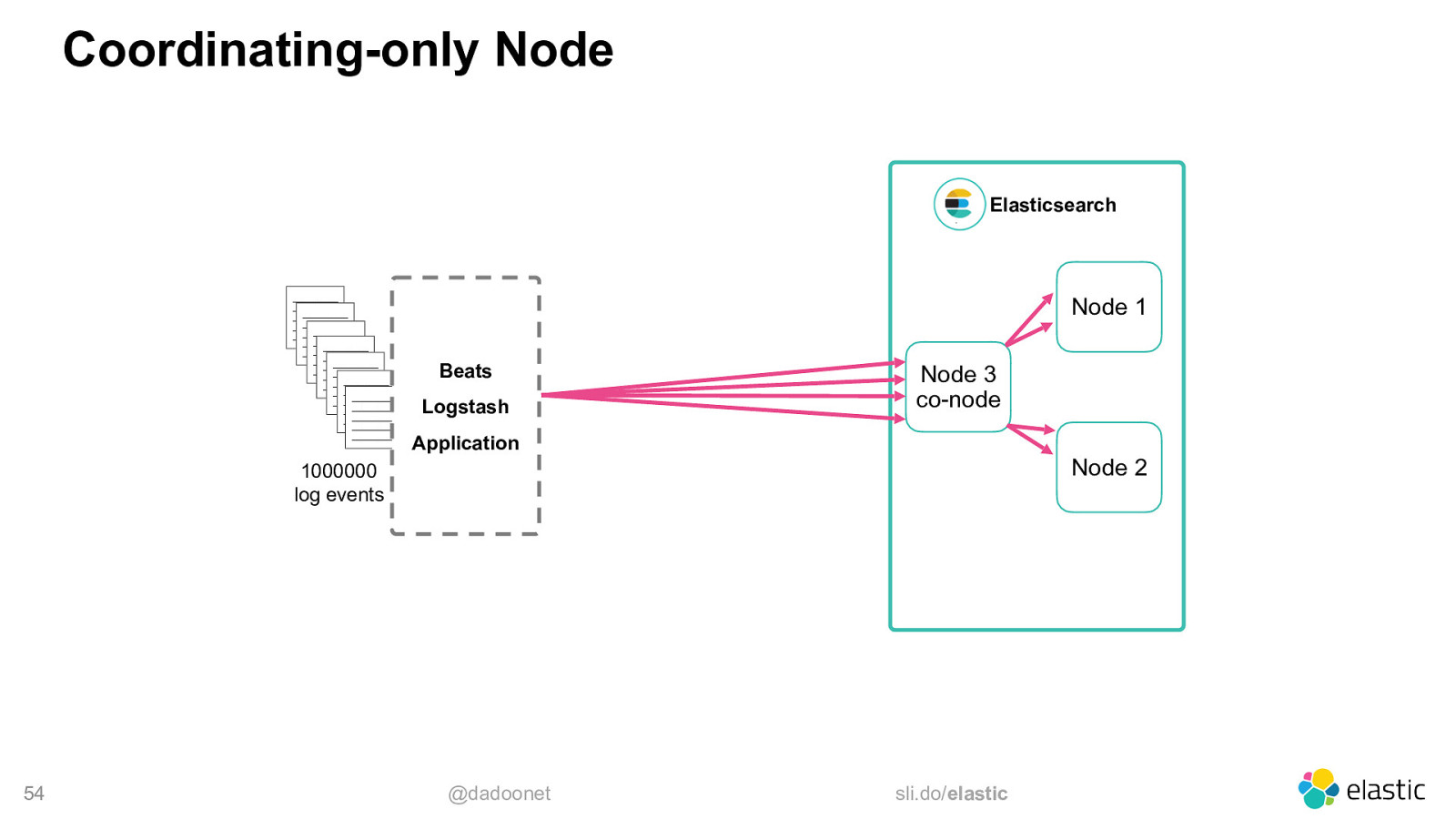
Coordinating-only Node Elasticsearch
Node 1 Beats Logstash Node 3 co-node Application Node 2 1000000 log events 54 @dadoonet sli.do/elastic
Slide 55
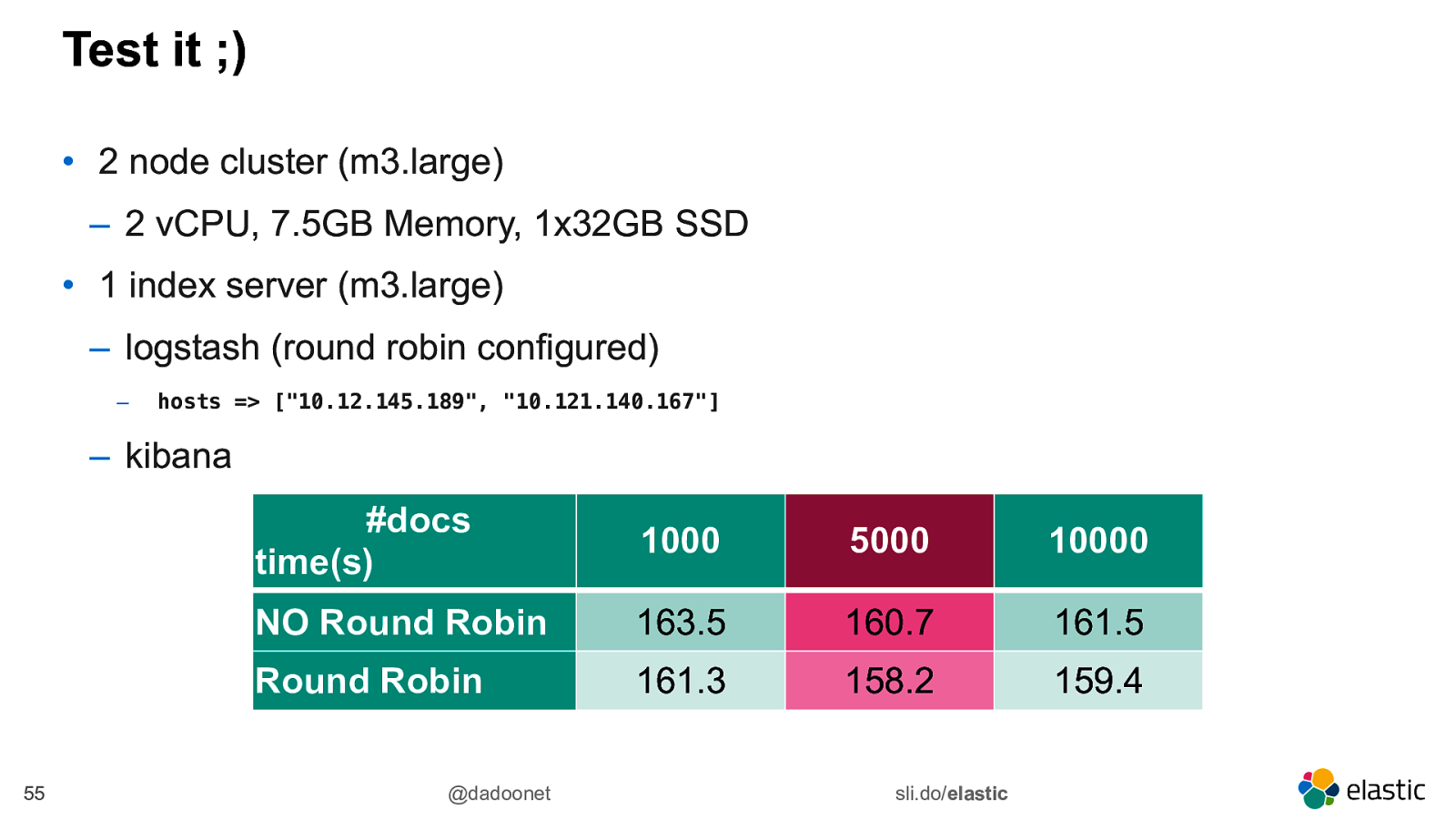
Test it ;) • 2 node cluster (m3.large) ‒ 2 vCPU, 7.5GB Memory, 1x32GB SSD • 1 index server (m3.large) ‒ logstash (round robin configured) ‒ hosts => [“10.12.145.189”, “10.121.140.167”] ‒ kibana 55 #docs time(s) 1000 5000 10000 NO Round Robin 163.5 160.7 161.5 Round Robin 161.3 158.2 159.4 @dadoonet sli.do/elastic
Slide 56

Optimizing Disk IO
Slide 57
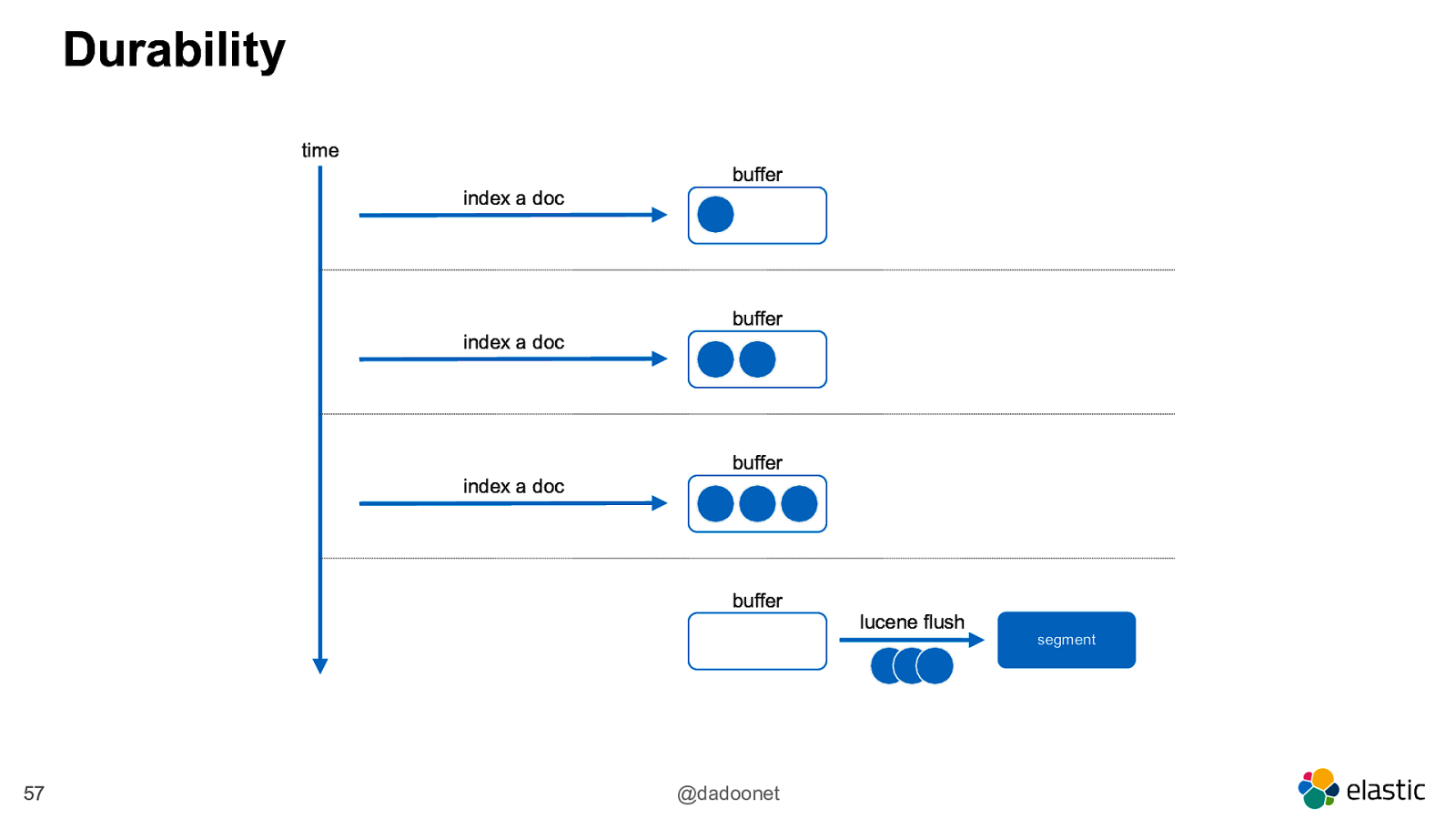
Durability time buffer index a doc buffer index a doc buffer index a doc buffer 57 @dadoonet lucene flush segment
Slide 58

refresh_interval • Dynamic per-index setting PUT logstash-2017.05.16/_settings { “refresh_interval”: “60s” } • Increase to get better write throughput to an index • New documents will take more time to be available for Search. 58 #docs time(s) 1000 5000 10000 1s refresh 60s refresh 161.3 156.7 158.2 152.1 159.4 152.6 @dadoonet
Slide 59
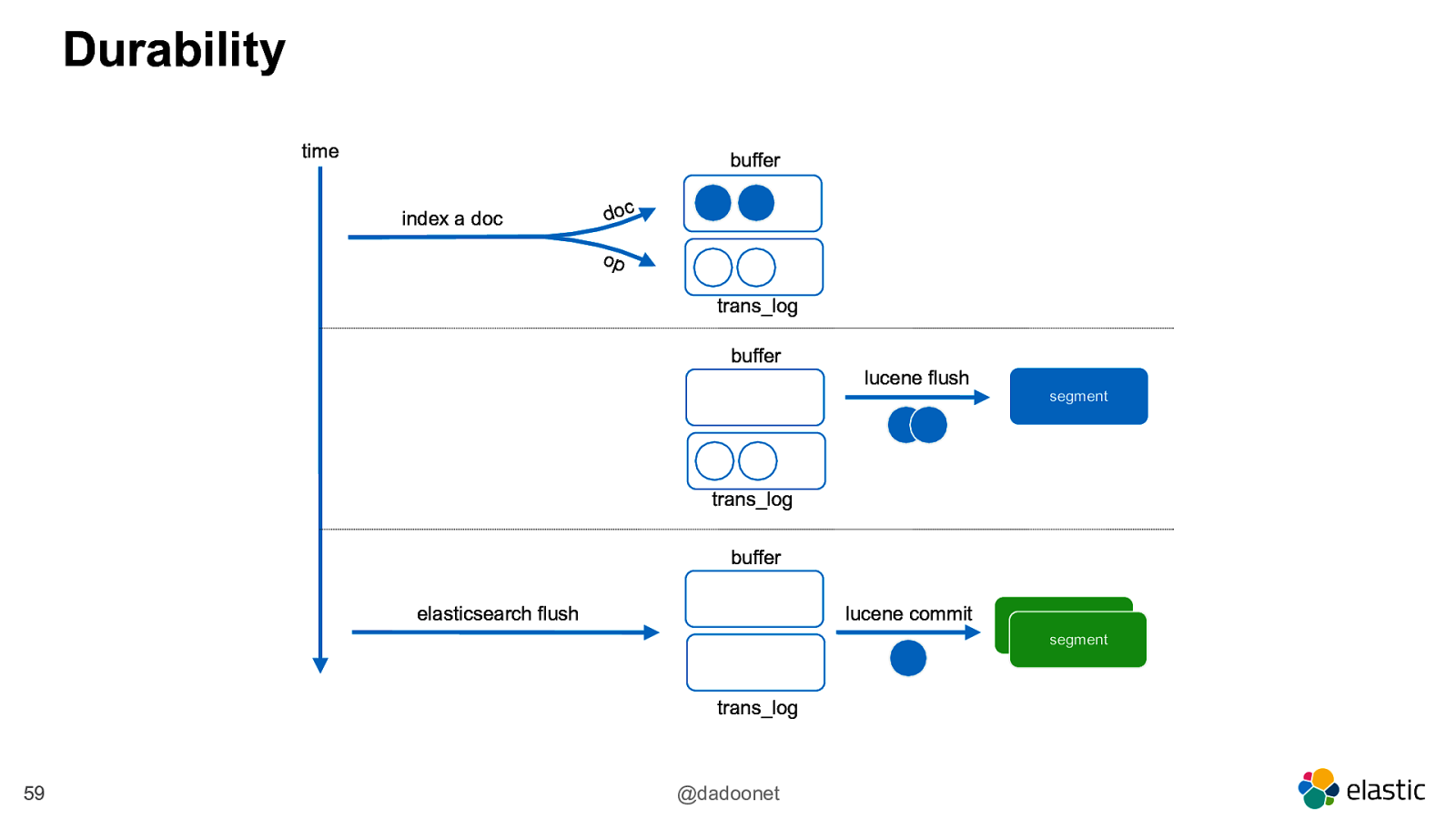
Durability time buffer index a doc doc op trans_log buffer lucene flush segment trans_log buffer elasticsearch flush lucene commit trans_log 59 @dadoonet segment segment
Slide 60
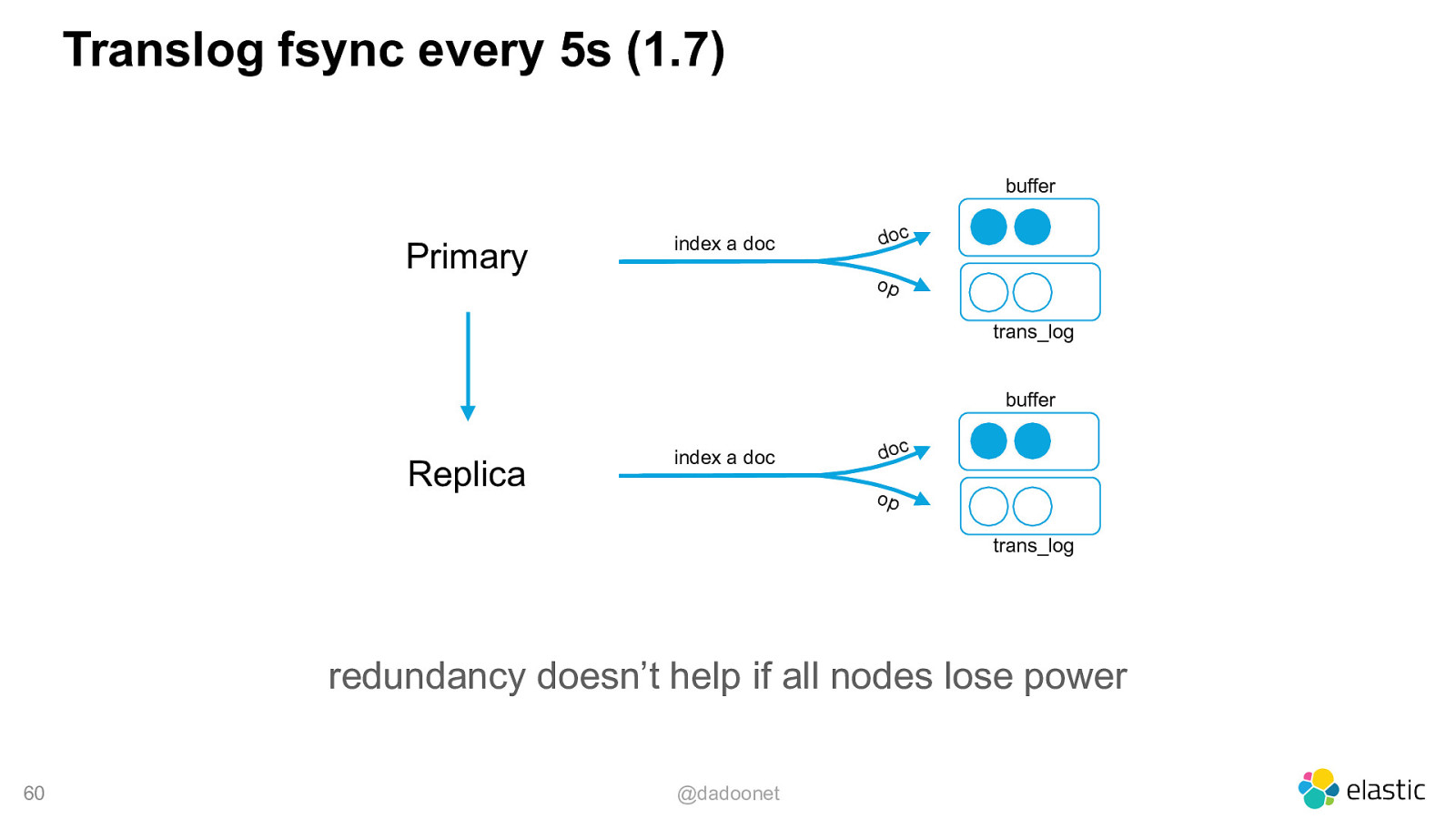
Translog fsync every 5s (1.7) buffer Primary index a doc doc op trans_log buffer Replica index a doc doc op trans_log redundancy doesn’t help if all nodes lose power 60 @dadoonet
Slide 61
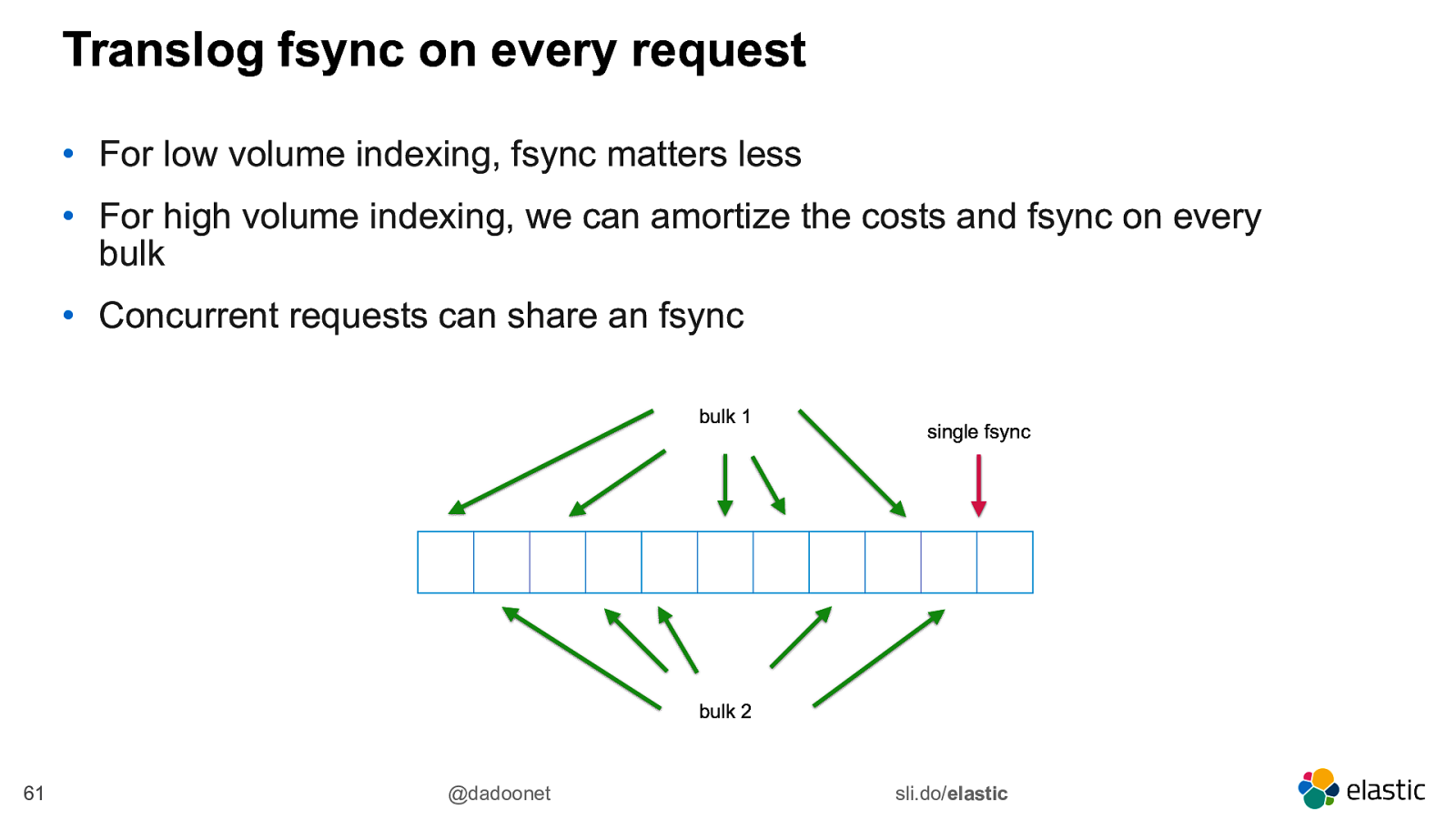
Translog fsync on every request • For low volume indexing, fsync matters less • For high volume indexing, we can amortize the costs and fsync on every bulk • Concurrent requests can share an fsync bulk 1 single fsync bulk 2 61 @dadoonet sli.do/elastic
Slide 62

Async Transaction Log • index.translog.durability ‒ request (default) ‒ async • index.translog.sync_interval (only if async is set) • Dynamic per-index settings • Be careful, you are relaxing the safety guarantees 62 #docs time(s) 1000 5000 10000 Request fsync 161.3 158.2 159.4 5s sync 152.4 149.1 150.3 @dadoonet
Slide 63

Final Remarks
Slide 64
App Search Site Search Enterprise Search Logging APM Business Analytics Security Analytics Metrics Elastic Stack Future Solutions Kibana Visualize & Manage Elasticsearch Store, Search, & Analyze Beats SaaS Elastic Cloud Logstash Ingest Self Managed Standalone Elastic Cloud Enterprise Deployment
Slide 65
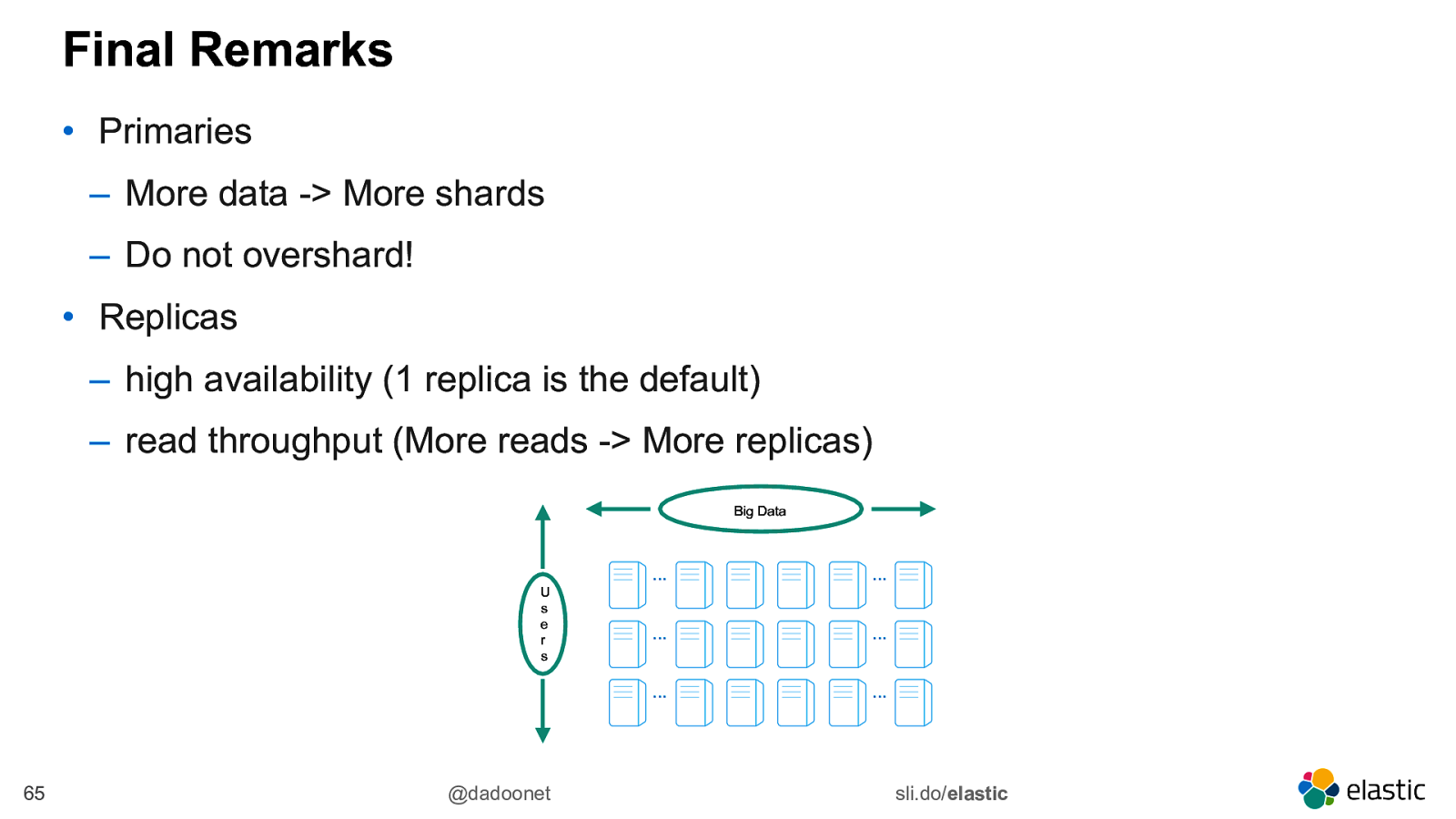
Final Remarks • Primaries ‒ More data -> More shards ‒ Do not overshard! • Replicas ‒ high availability (1 replica is the default) ‒ read throughput (More reads -> More replicas) Big Data U s e r s 65 @dadoonet … … … … … … sli.do/elastic
Slide 66

Final Remarks • Bulk and Test • Distribute the Load • Refresh Interval • Async Trans Log (careful) 66 #docs per bulk 1000 5000 10000 Default 163.5 160.7 161.5 RR+60s+Async5s 152.4 149.1 150.3 @dadoonet
Slide 67

Managing your Black Friday Logs David Pilato Developer | Evangelist, @dadoonet