Search: a new era
A presentation at jPrime 2024 in in Sofia, Bulgaria by David Pilato

Search & AI a new era David Pilato | @dadoonet

Agenda ● ● ● ● “Classic” search and its limitations ML model and usage Vector search or hybrid search in Elasticsearch OpenAI’s ChatGPT or LLMs with Elasticsearch

Elasticsearch You Know, for Search



These are not the droids you are looking for.
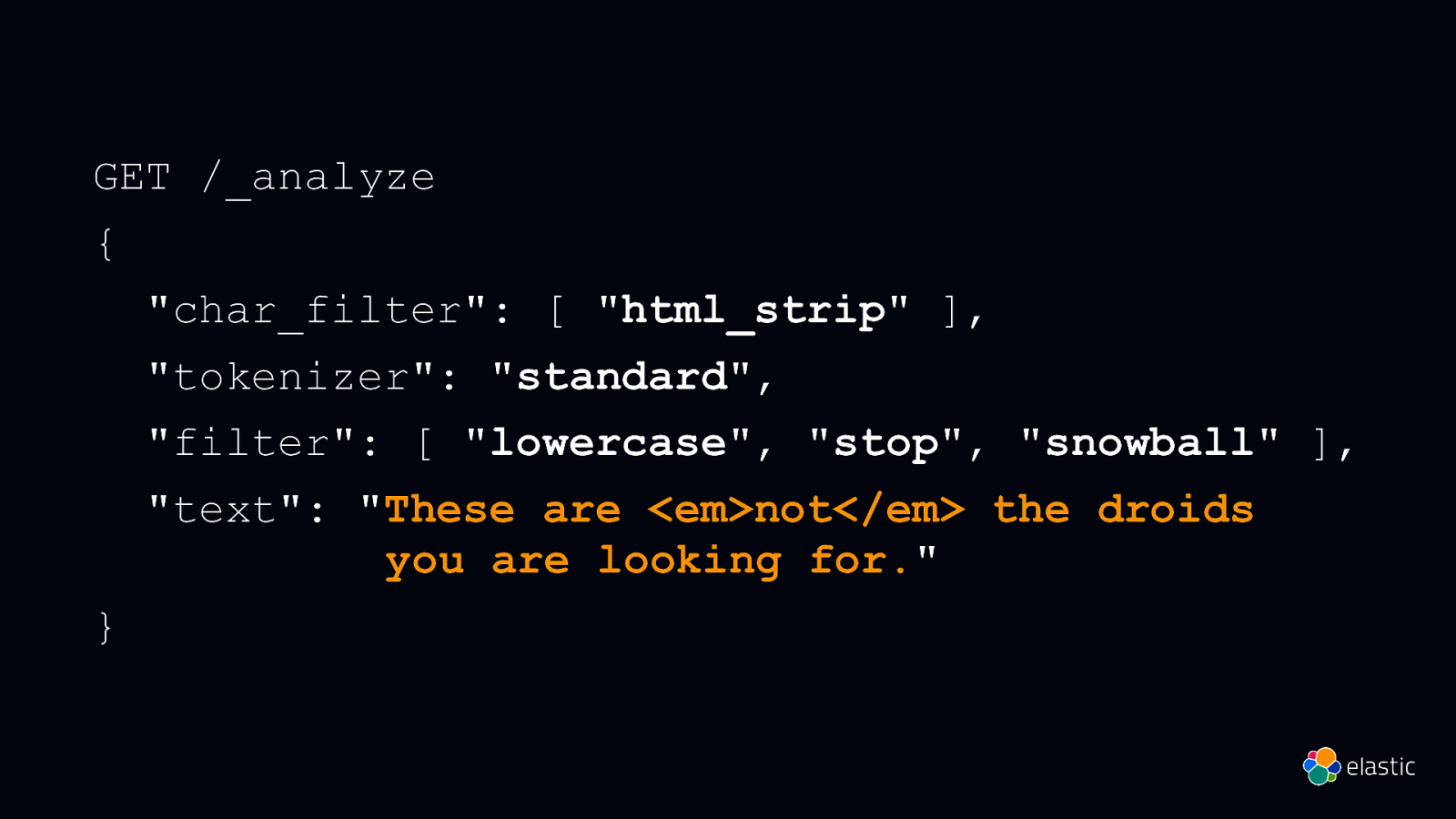
GET /_analyze { “char_filter”: [ “html_strip” ], “tokenizer”: “standard”, “filter”: [ “lowercase”, “stop”, “snowball” ], “text”: “These are <em>not</em> the droids you are looking for.” }

These are <em>not</em> the droids you are looking for. { “tokens”: [{ “token”: “droid”, “start_offset”: 27, “end_offset”: 33, “type”: “<ALPHANUM>”, “position”: 4 },{ “token”: “you”, “start_offset”: 34, “end_offset”: 37, “type”: “<ALPHANUM>”, “position”: 5 }, { “token”: “look”, “start_offset”: 42, “end_offset”: 49, “type”: “<ALPHANUM>”, “position”: 7 }]}

Semantic search ≠ Literal matches

TODAY X-wing starfighter squadron TOMORROW What ships and crews do I need to destroy an almost finished death star? Or is there a secret weakness?

Elasticsearch You Know, for Vector Search

What is a Vector ?
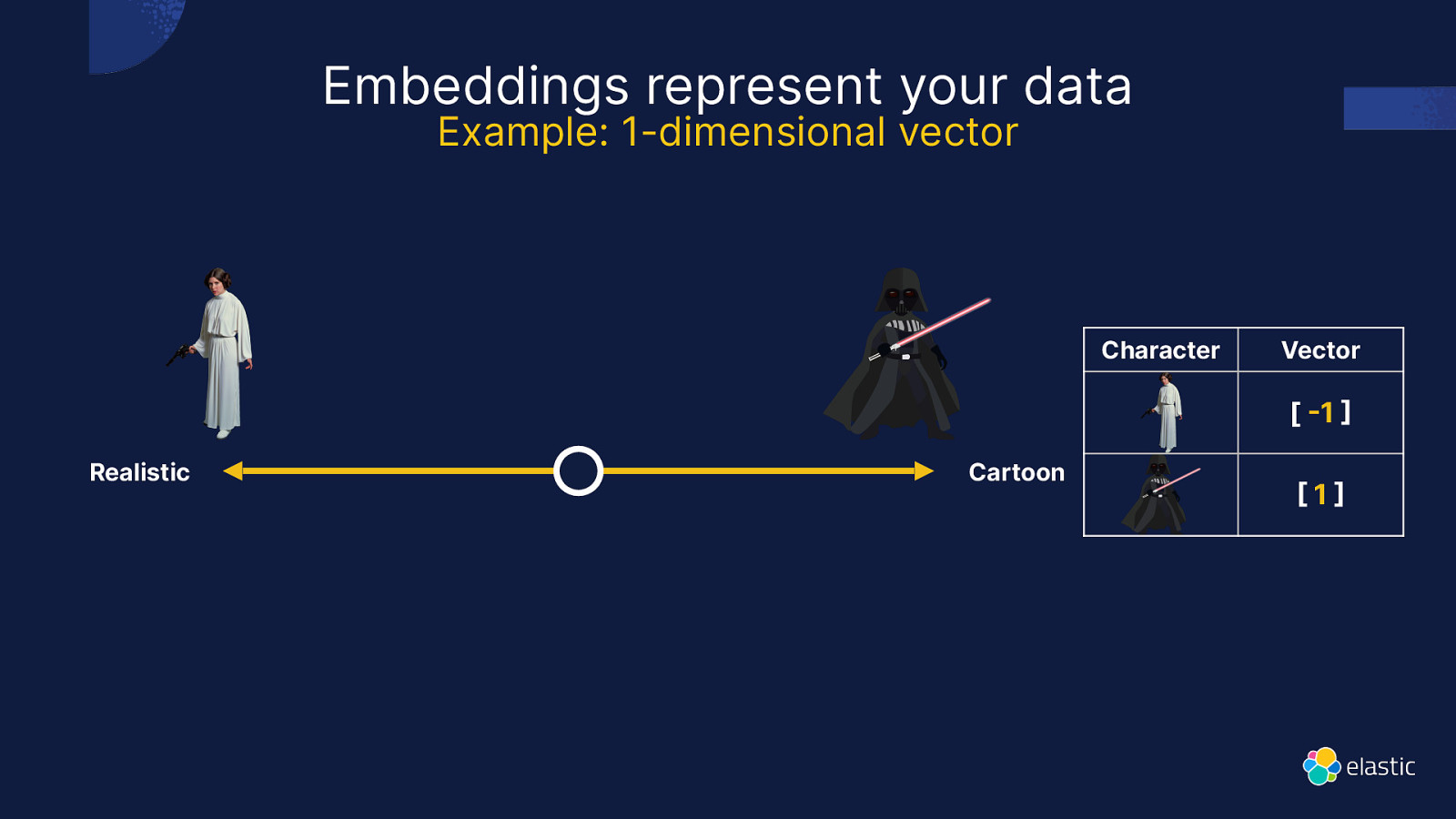
Embeddings represent your data Example: 1-dimensional vector Character Vector [ 1 Realistic Cartoon 1
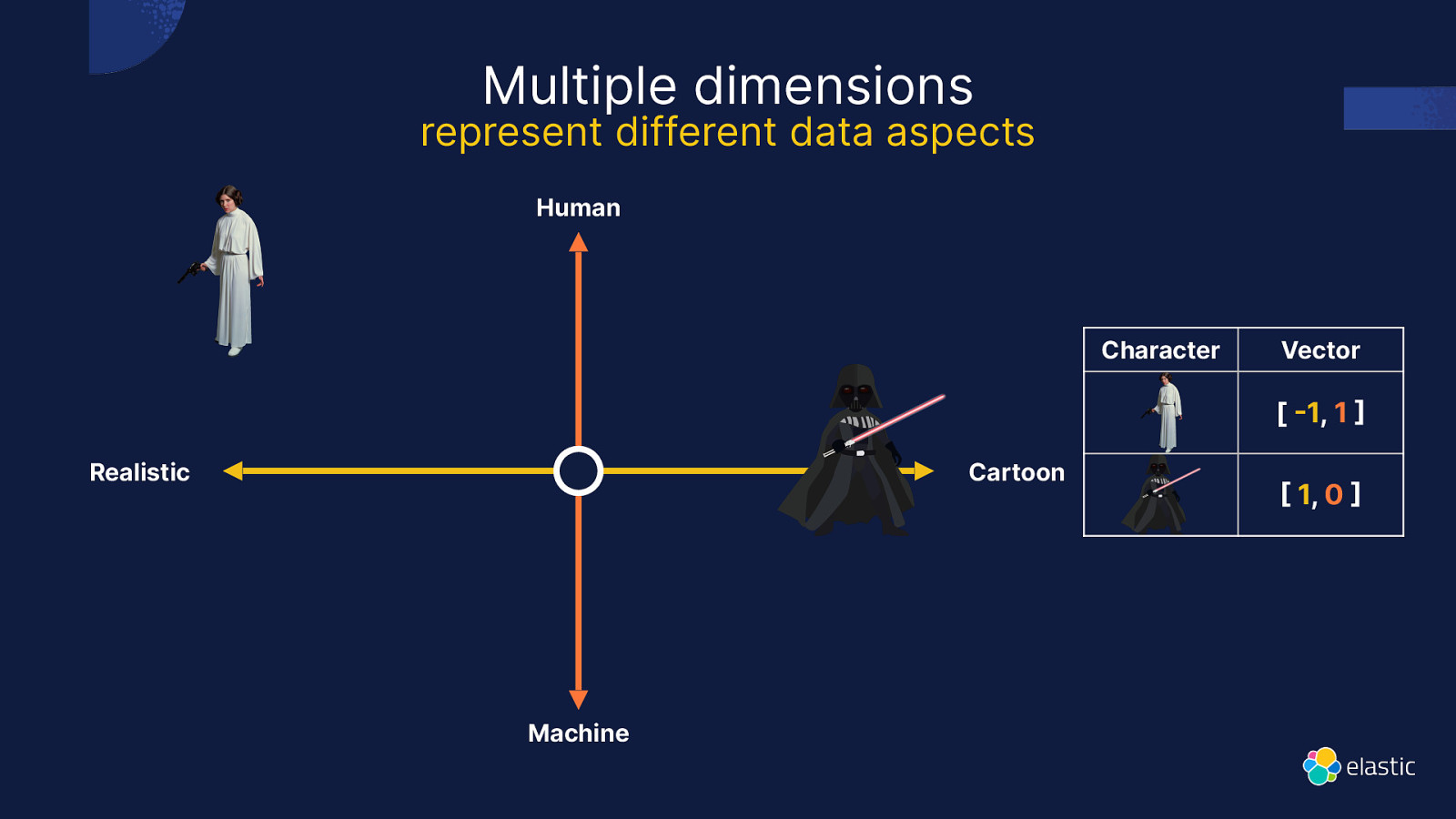
Multiple dimensions represent different data aspects Human Character Vector [ 1, 1 Realistic Cartoon Machine 1, 0
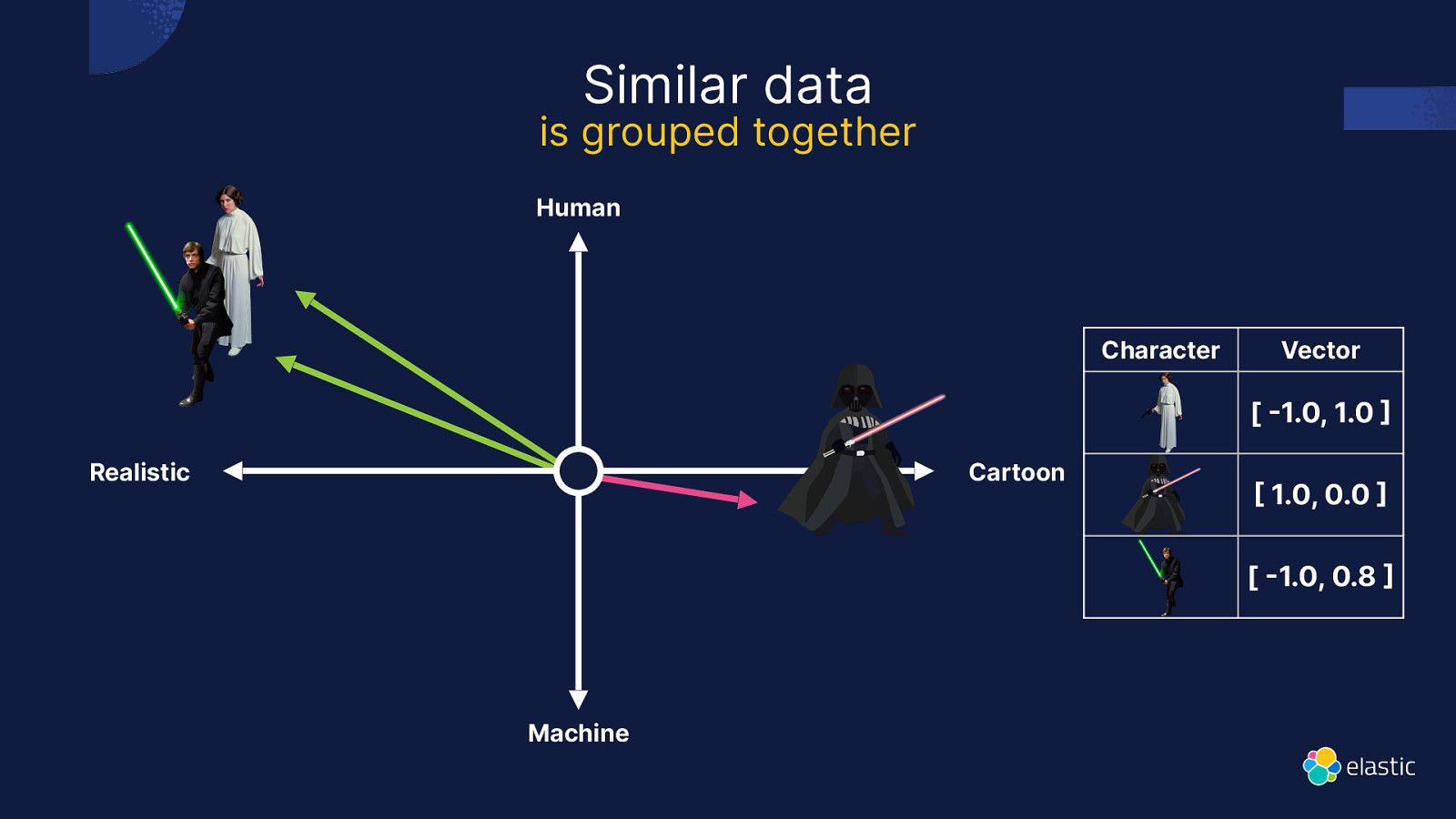
Similar data is grouped together Human Character Vector [ 1.0, 1.0 Realistic Cartoon 1.0, 0.0 [ 1.0, 0.8 Machine
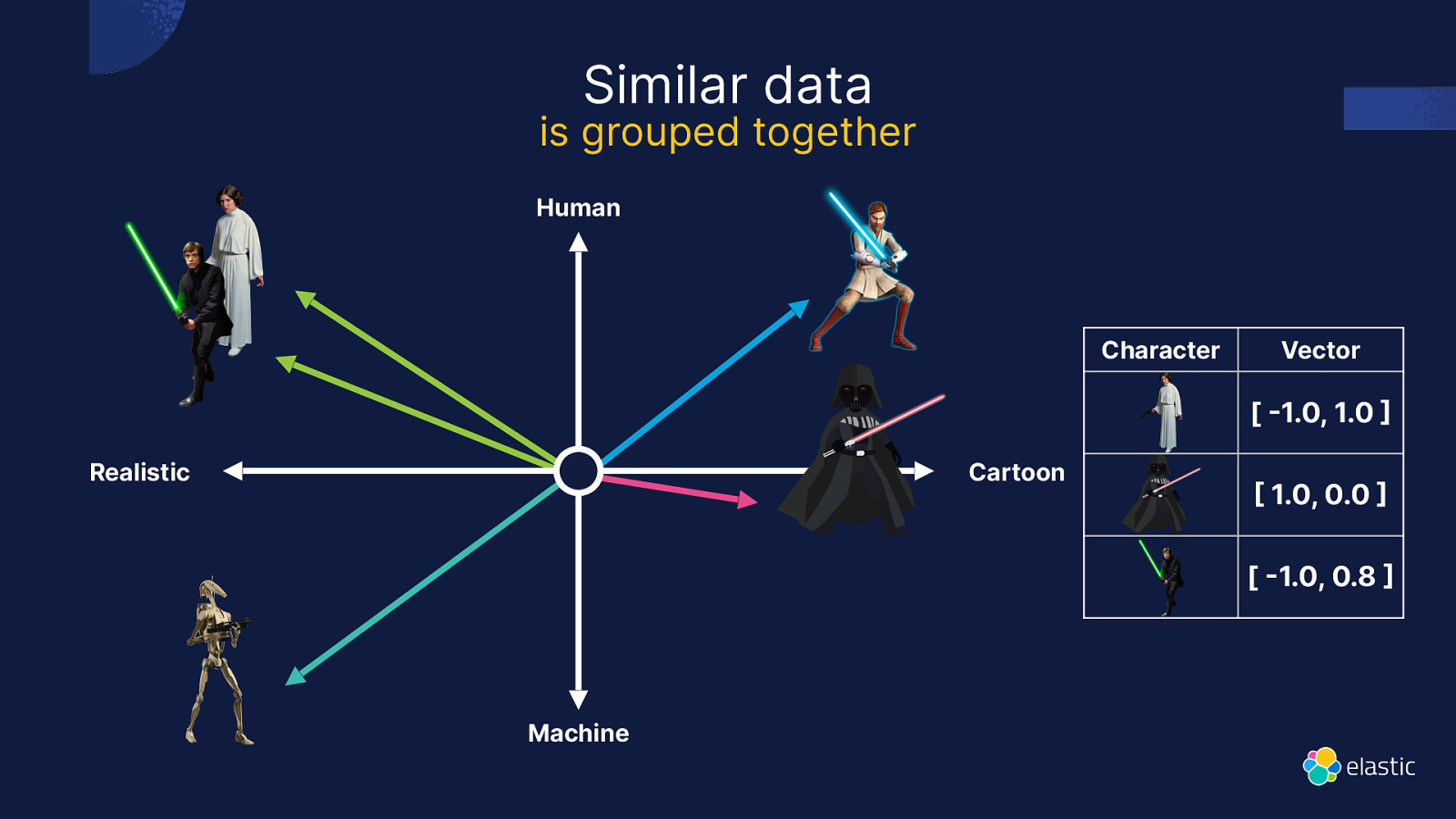
Similar data is grouped together Human Character Vector [ 1.0, 1.0 Realistic Cartoon 1.0, 0.0 [ 1.0, 0.8 Machine
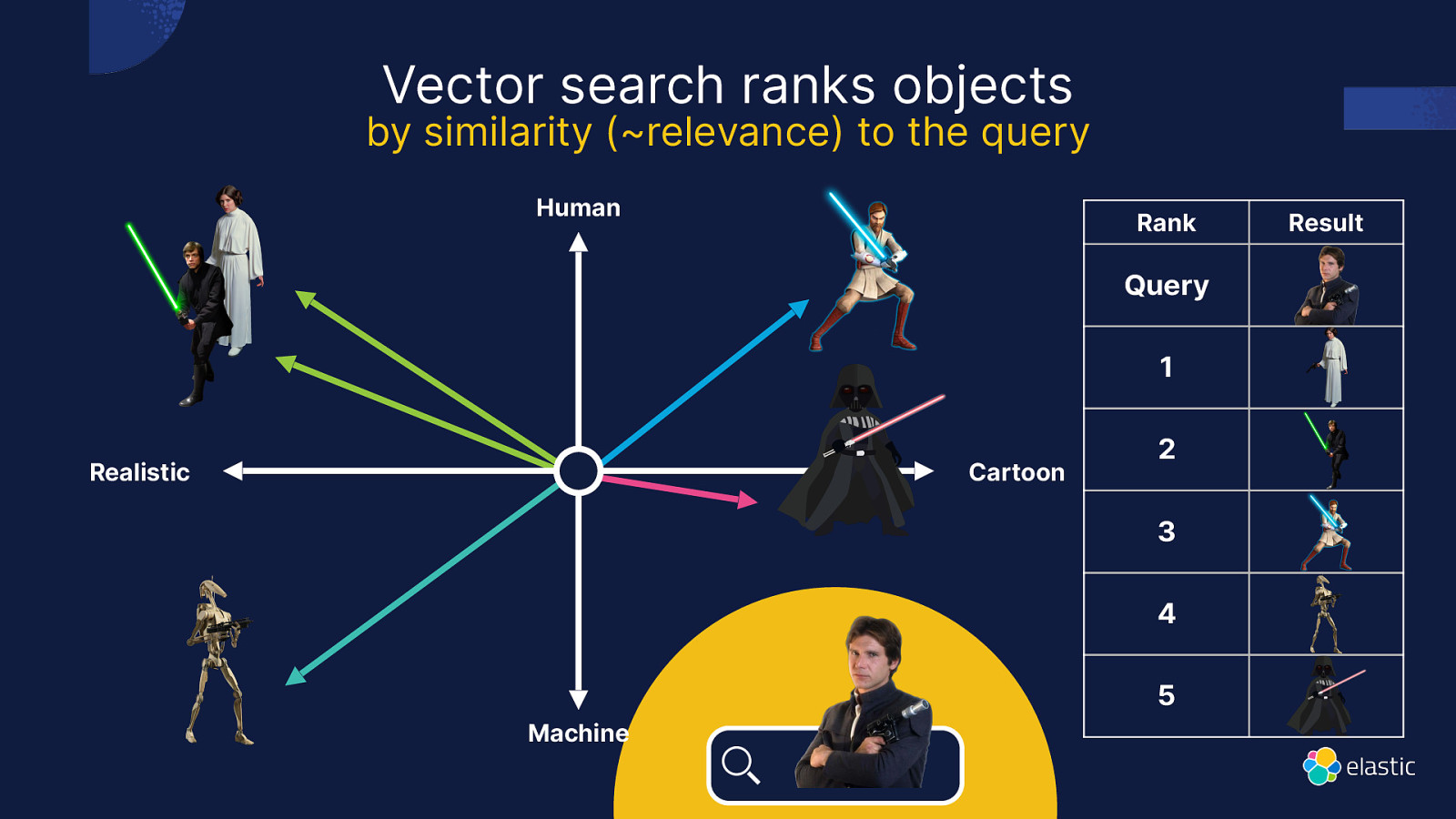
Vector search ranks objects by similarity (~relevance) to the query Human Rank Query 1 Realistic Cartoon 2 3 4 5 Machine Result

Choice of Embedding Model Start with Off-the Shelf Models Extend to Higher Relevance ●Text data: Hugging Face (like Microsoft’s E5 ●Apply hybrid scoring ●Images: OpenAI’s CLIP ●Bring Your Own Model: requires expertise + labeled data

Problem training vs actual use-case
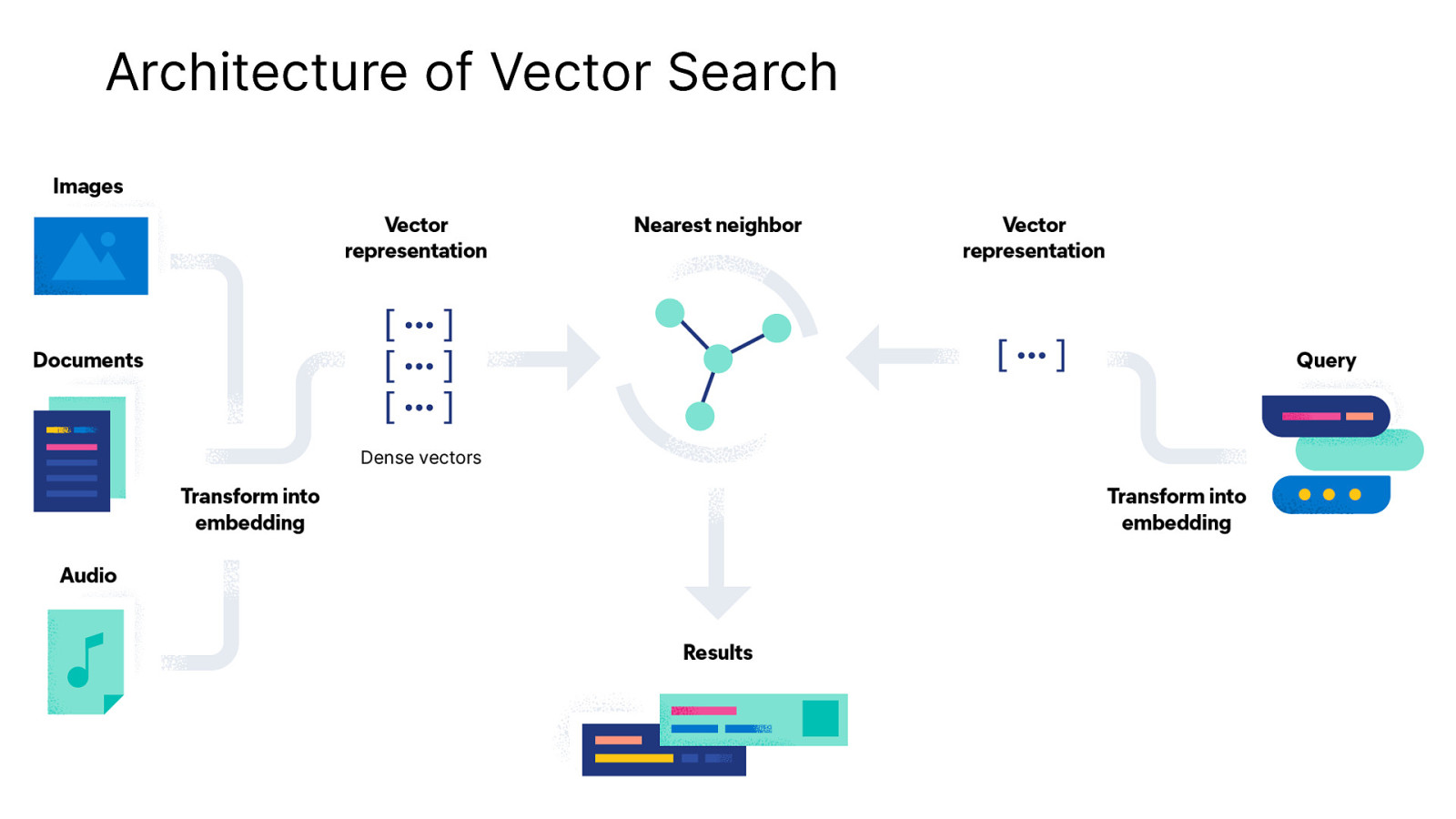
Architecture of Vector Search

How do you index vectors ?
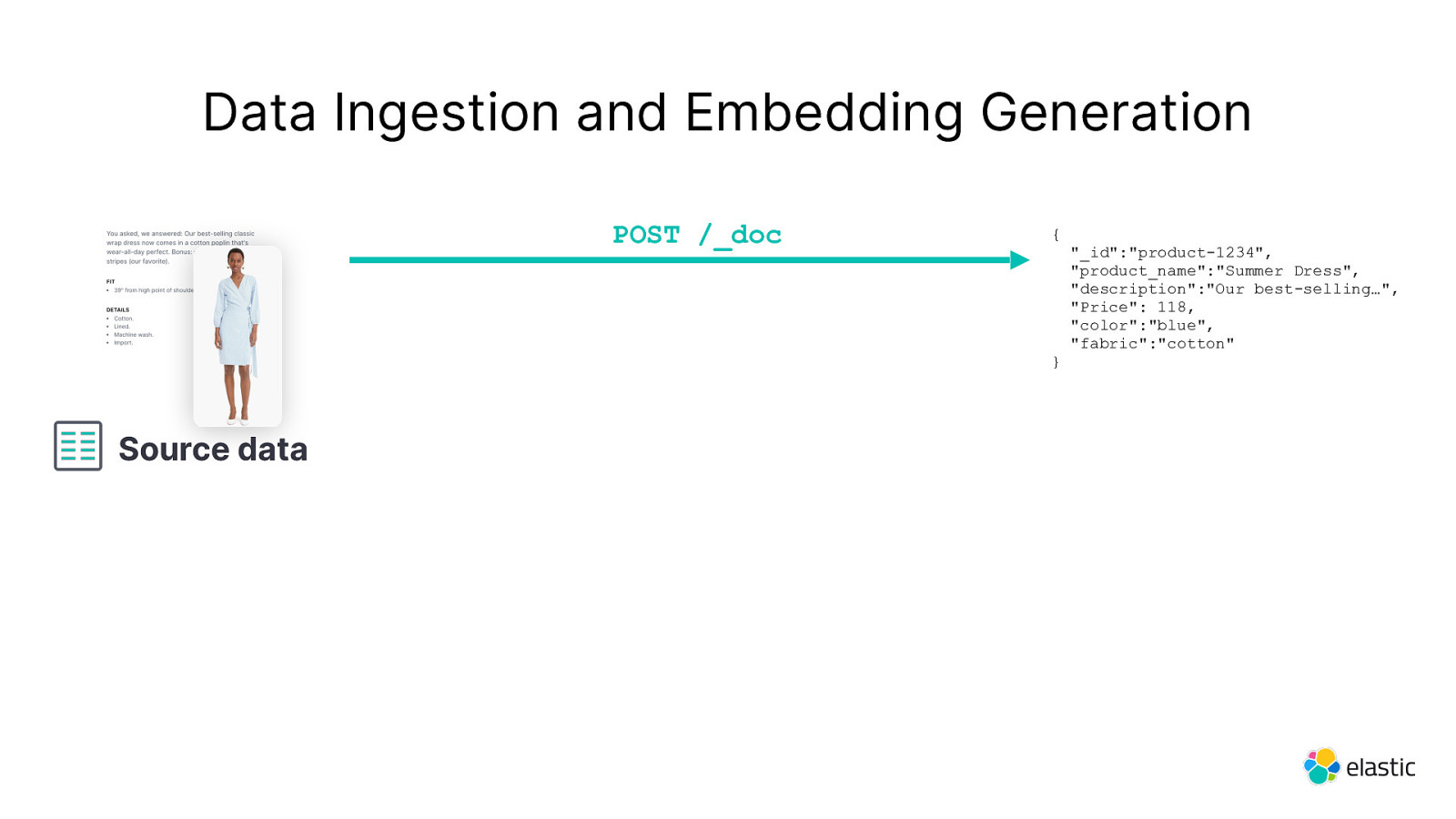
Data Ingestion and Embedding Generation POST /_doc { } Source data “_id”:”product-1234”, “product_name”:”Summer Dress”, “description”:”Our best-selling…”, “Price”: 118, “color”:”blue”, “fabric”:”cotton”
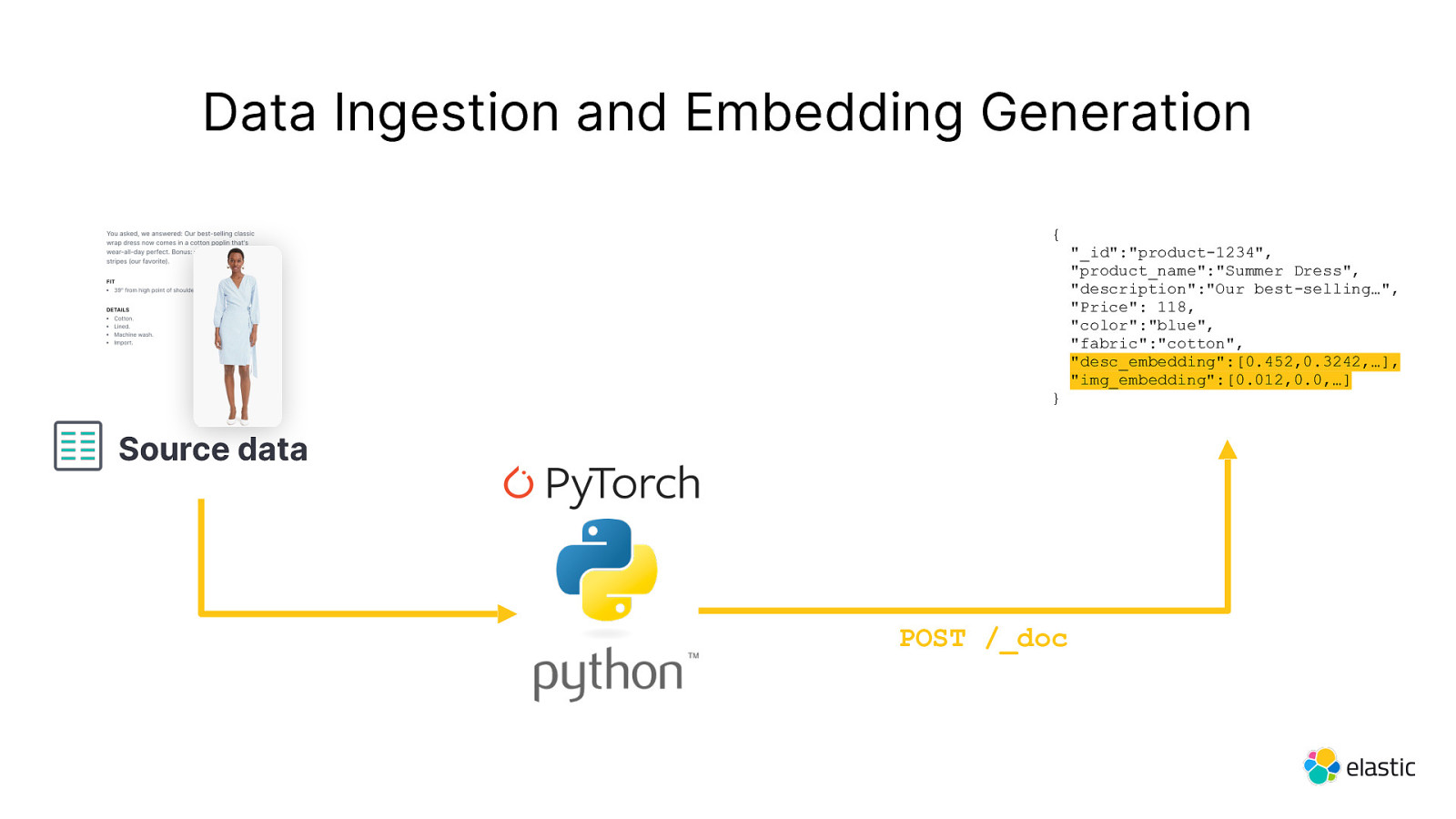
Data Ingestion and Embedding Generation { } Source data POST /_doc “_id”:”product-1234”, “product_name”:”Summer Dress”, “description”:”Our best-selling…”, “Price”: 118, “color”:”blue”, “fabric”:”cotton”, “desc_embedding”:[0.452,0.3242,…], “img_embedding”:[0.012,0.0,…]
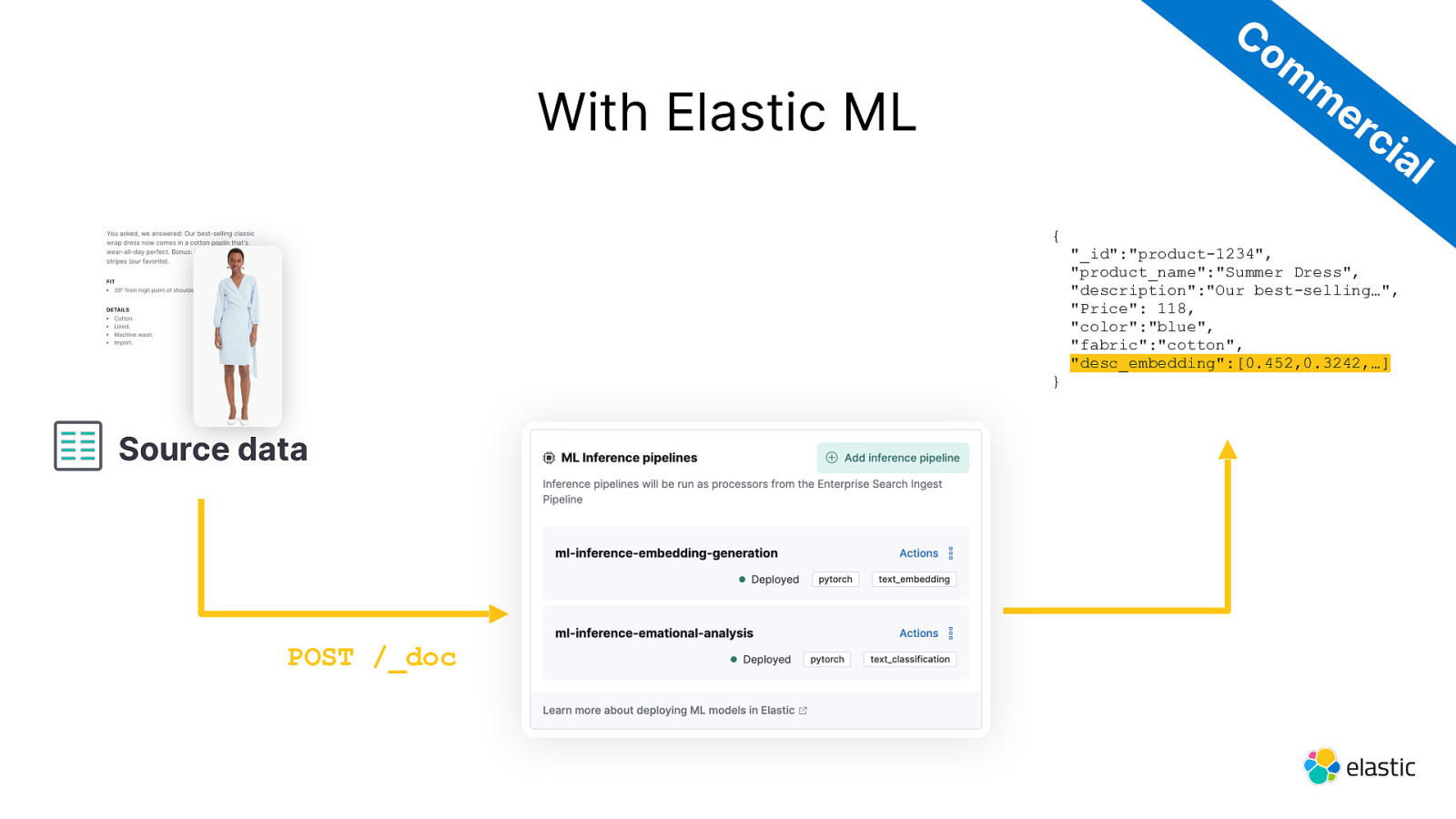
Co m m er ci With Elastic ML al { } Source data POST /_doc “_id”:”product-1234”, “product_name”:”Summer Dress”, “description”:”Our best-selling…”, “Price”: 118, “color”:”blue”, “fabric”:”cotton”, “desc_embedding”:[0.452,0.3242,…]
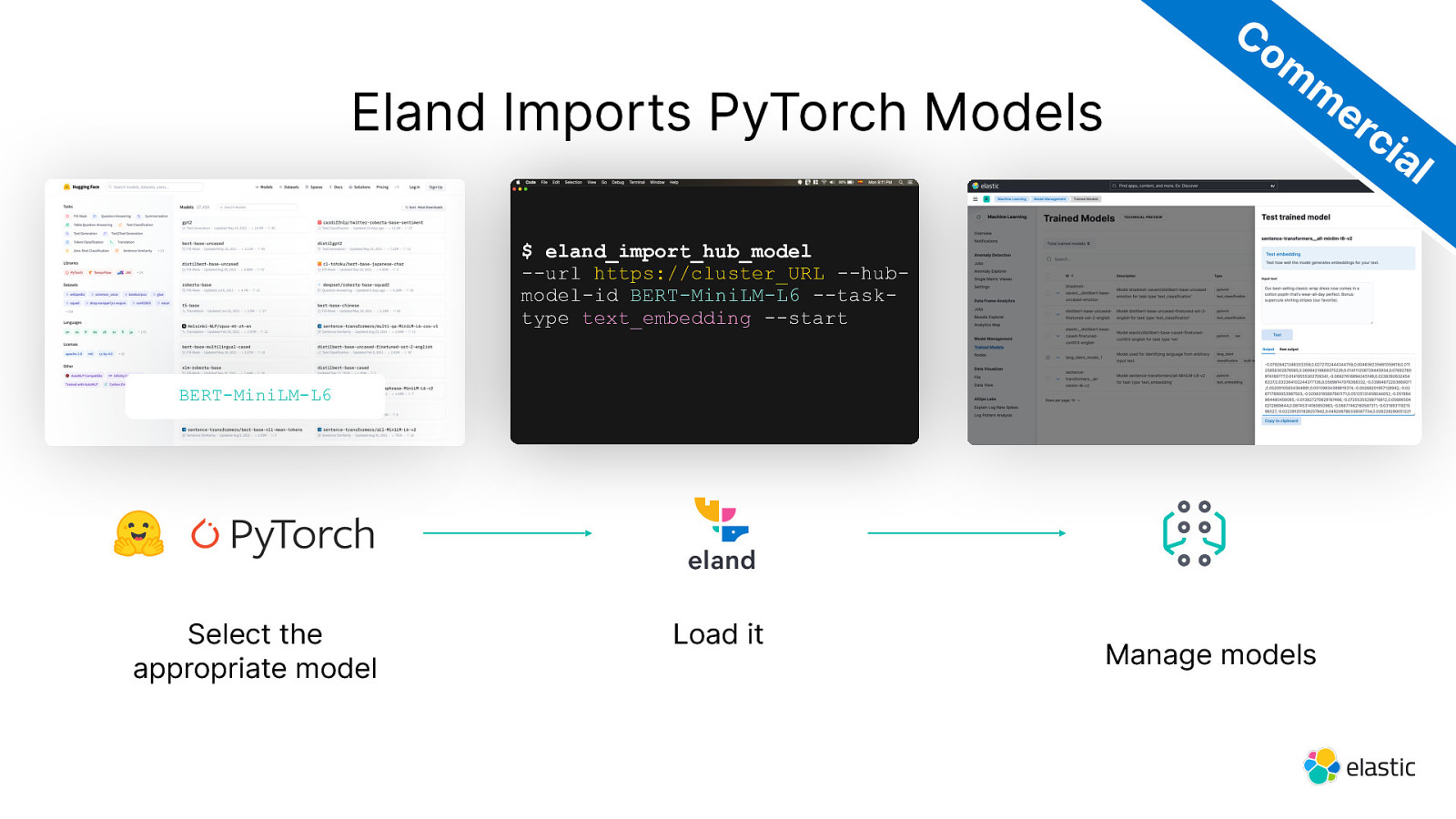
Eland Imports PyTorch Models Co m m er ci al $ eland_import_hub_model —url https://cluster_URL —hubmodel-id BERT-MiniLM-L6 —tasktype text_embedding —start BERT-MiniLM-L6 Select the appropriate model Load it Manage models

Elastic’s range of supported NLP models Co m m er ci ● Fill mask model Mask some of the words in a sentence and predict words that replace masks ● Named entity recognition model NLP method that extracts information from text ● Text embedding model Represent individual words as numerical vectors in a predefined vector space ● Text classification model Assign a set of predefined categories to open-ended text ● Question answering model Model that can answer questions given some or no context ● Zero-shot text classification model Model trained on a set of labeled examples, that is able to classify previously unseen examples Full list at: ela.st/nlp-supported-models al

How do you search vectors ?
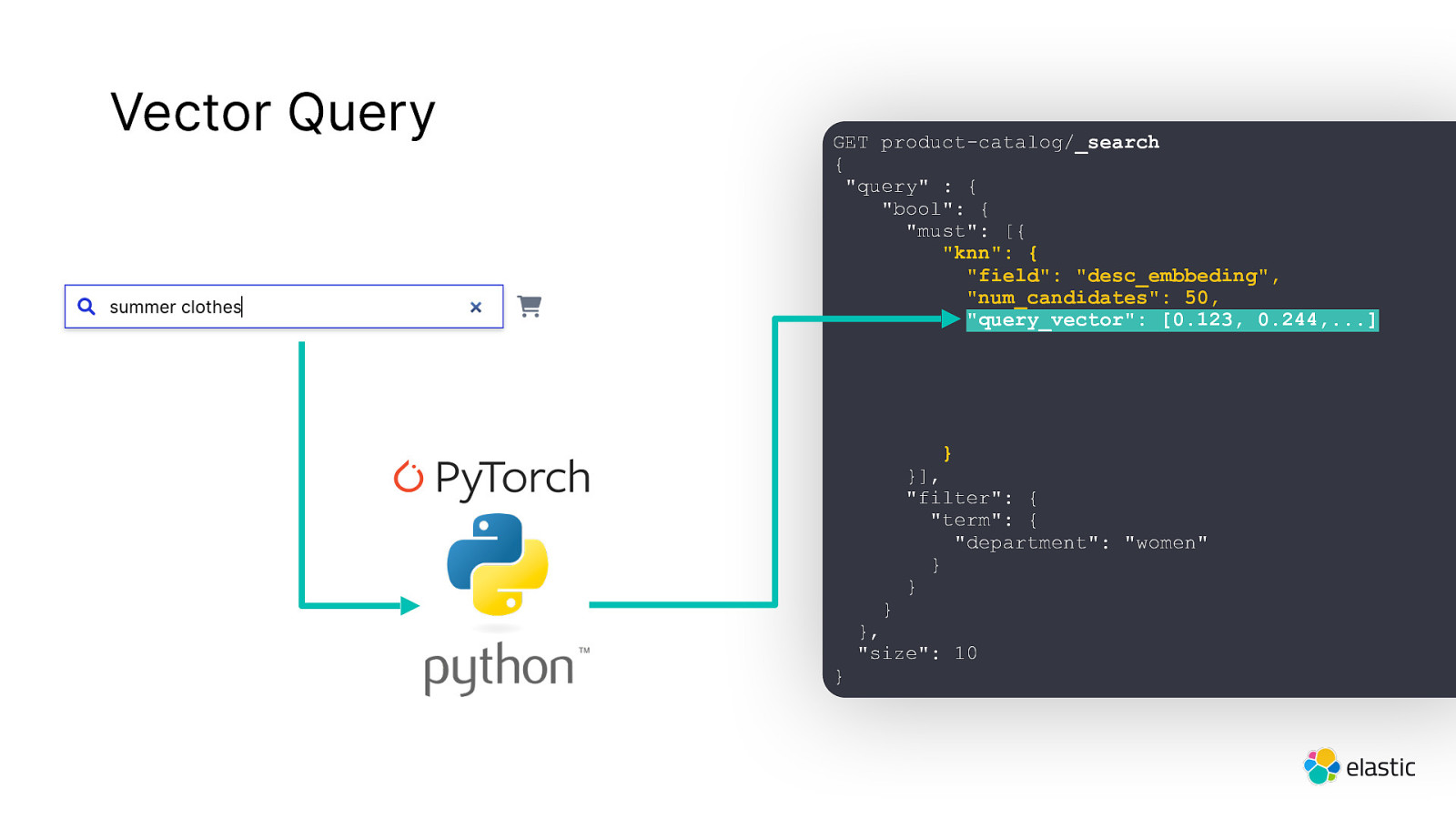
Vector Query GET product-catalog/_search { “query” : { “bool”: { “must”: [{ “knn”: { “field”: “desc_embbeding”, “num_candidates”: 50, “query_vector”: [0.123, 0.244,…] } }], “filter”: { “term”: { “department”: “women” } } } } }, “size”: 10
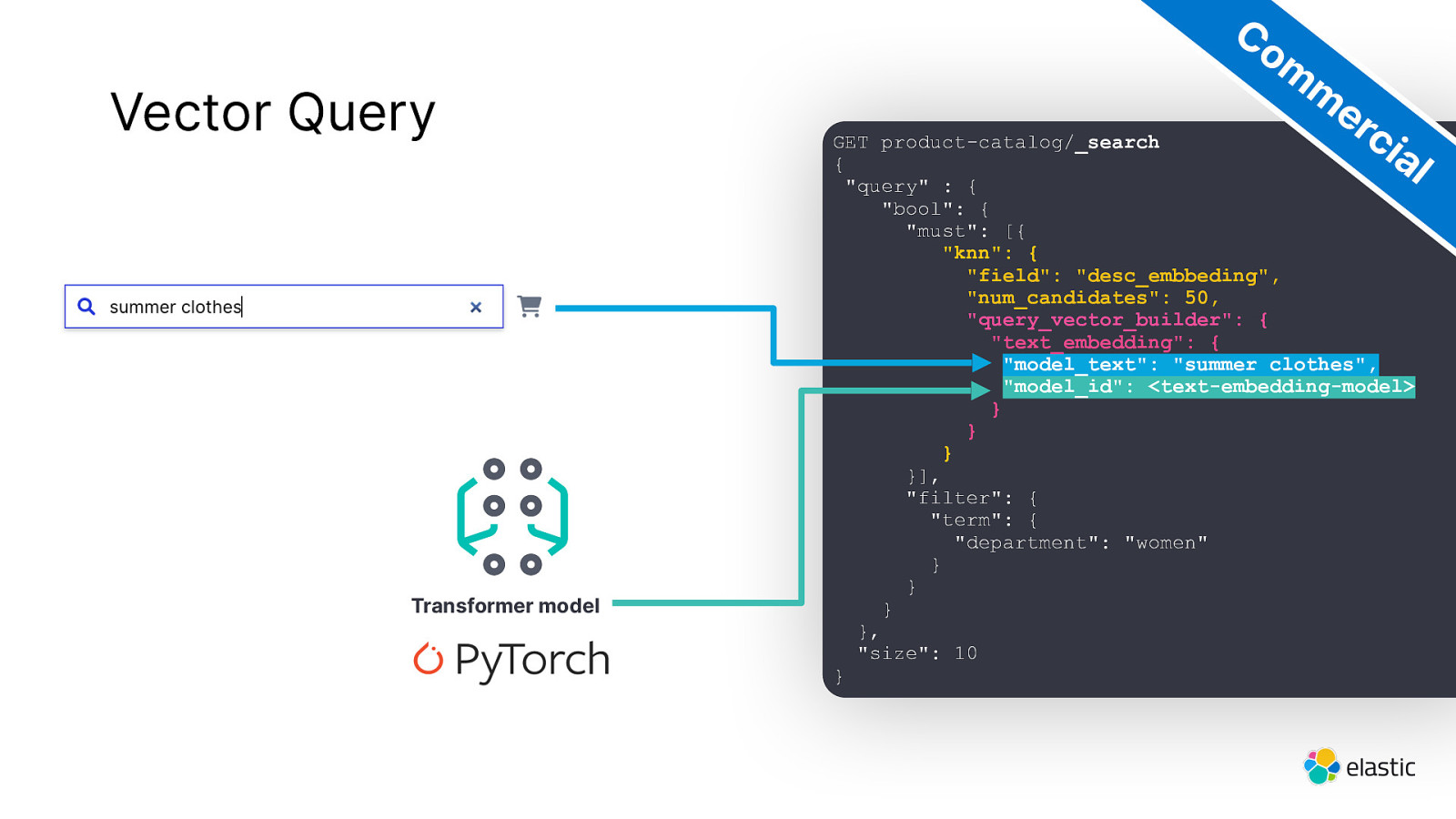
Vector Query Transformer model Co m m er ci al GET product-catalog/_search { “query” : { “bool”: { “must”: [{ “knn”: { “field”: “desc_embbeding”, “num_candidates”: 50, “query_vector_builder”: { “text_embedding”: { “model_text”: “summer clothes”, “model_id”: <text-embedding-model> } } } }], “filter”: { “term”: { “department”: “women” } } } }, “size”: 10 }
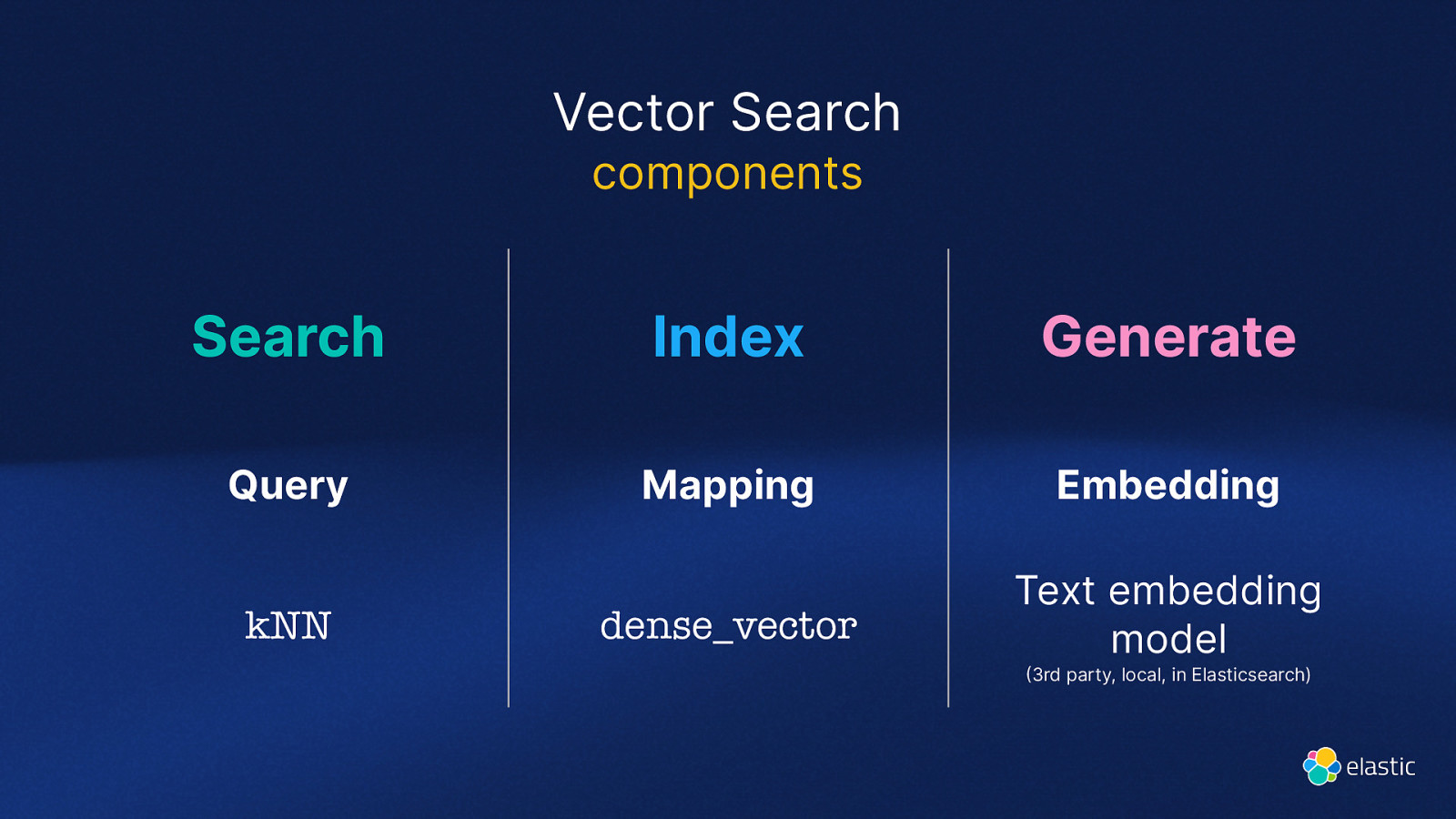
Vector Search components Search Index Generate Query Mapping Embedding dense_vector Text embedding model kNN 3rd party, local, in Elasticsearch)

But how does it really work?
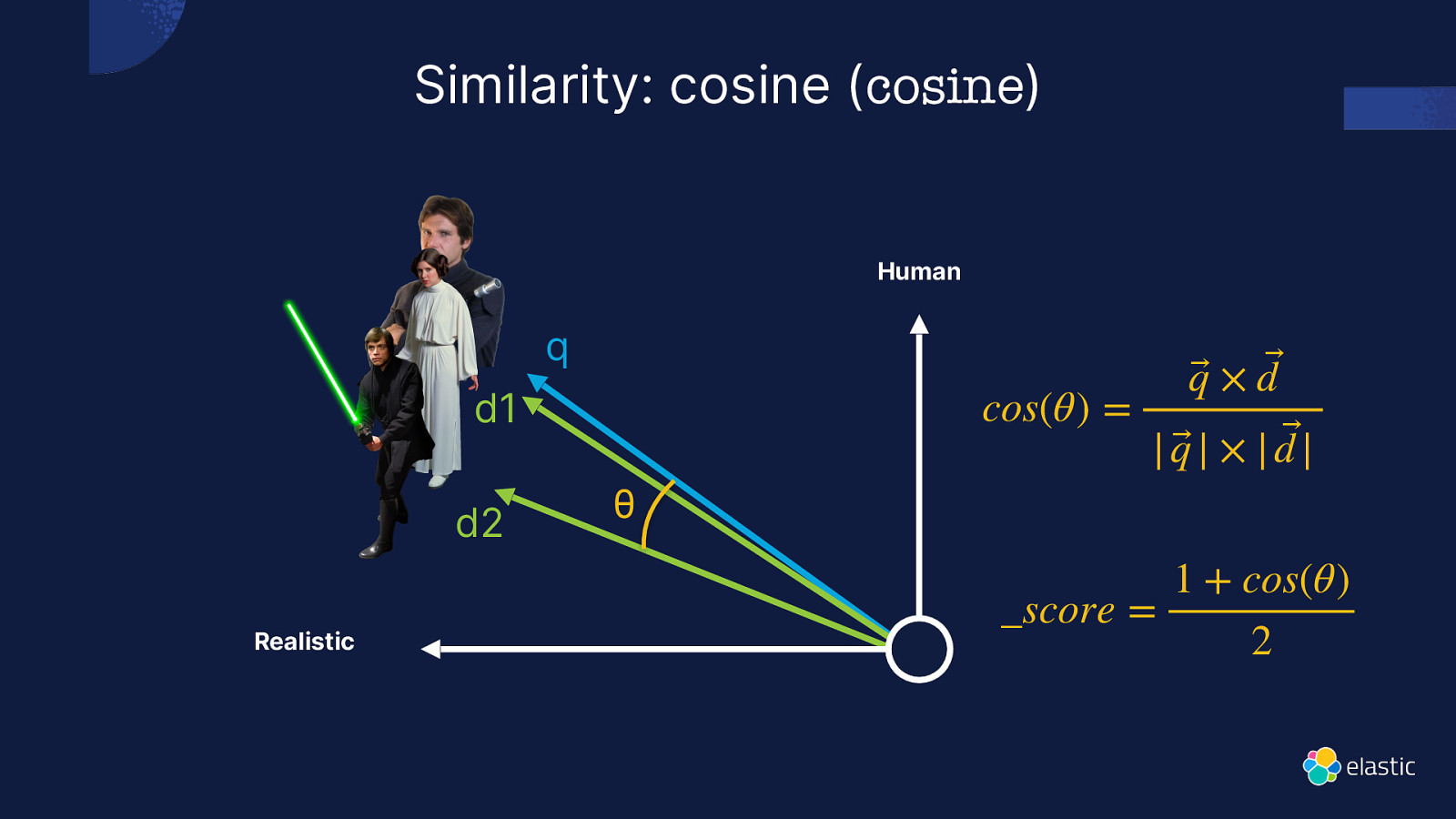
Similarity: cosine (cosine) Human q cos(θ) = d1 d2 Realistic θ q⃗ × d ⃗ | q⃗ | × | d |⃗ _score = 1 + cos(θ) 2
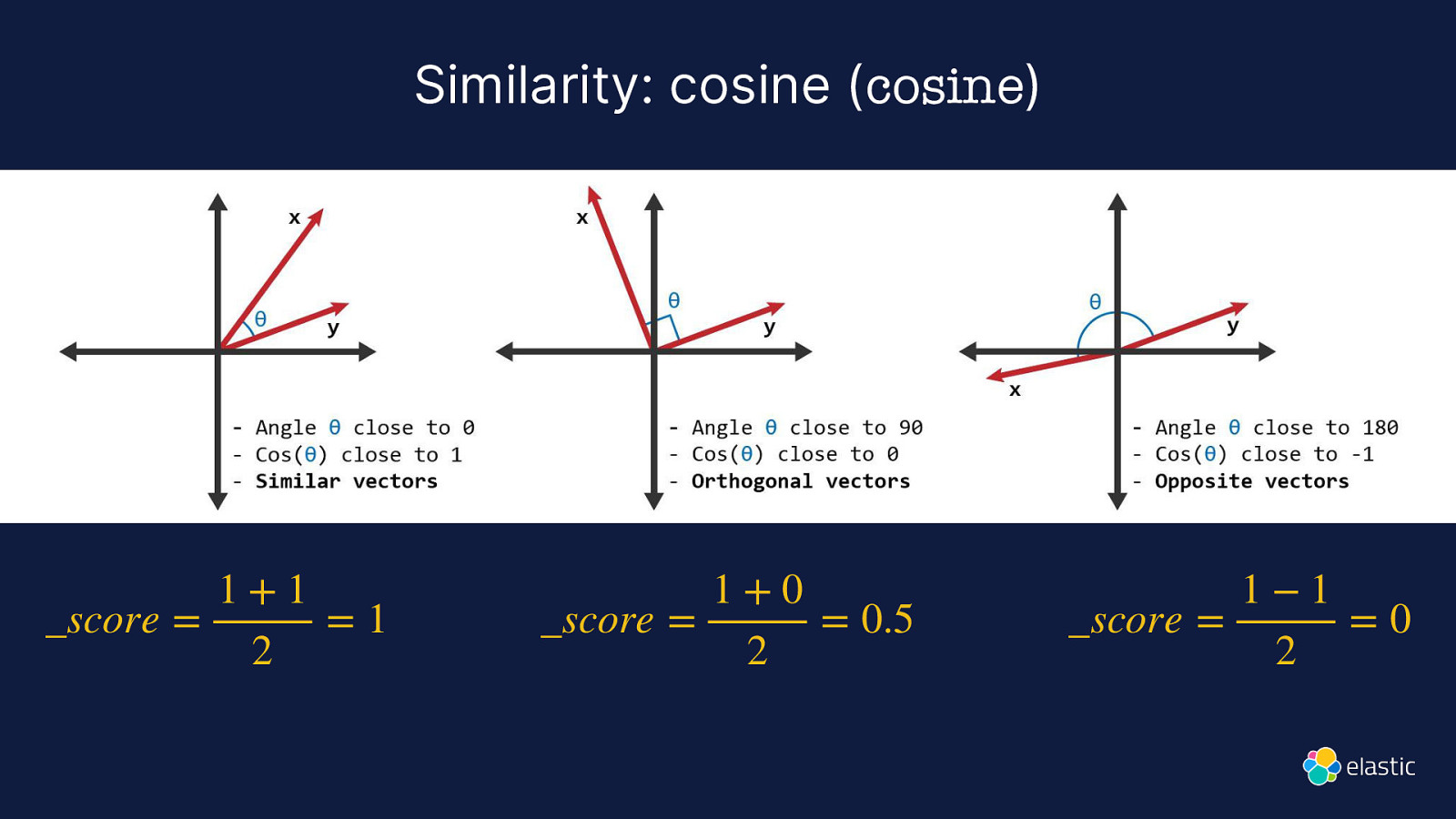
Similarity: cosine (cosine) 1+1 _score = =1 2 1+0 _score = = 0.5 2 1−1 _score = =0 2
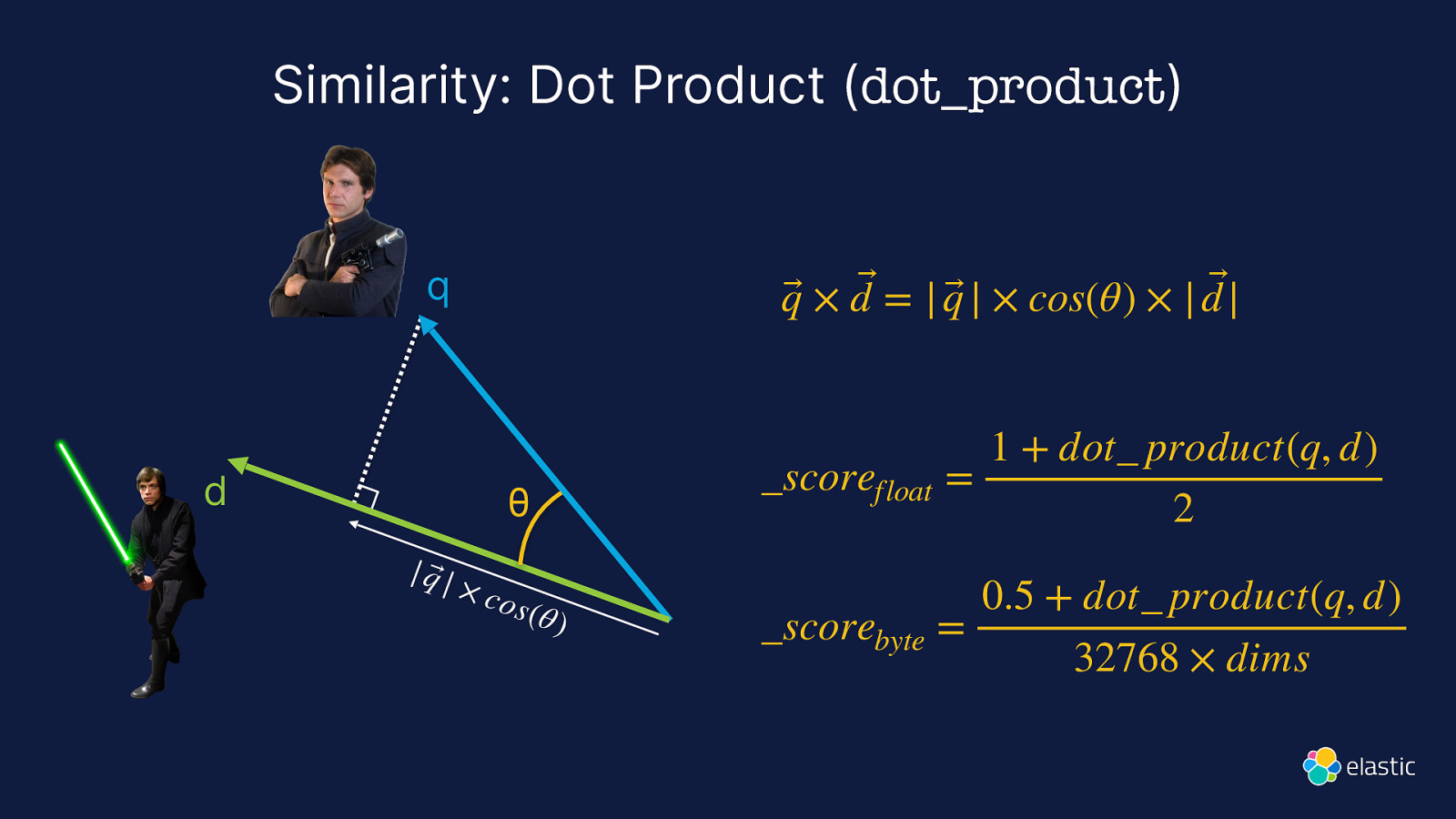
Similarity: Dot Product (dot_product) q d q⃗ × d ⃗ = | q⃗ | × cos(θ) × | d |⃗ θ | q⃗ | × co s (θ ) 1 + dot_ product(q, d) scorefloat = 2 0.5 + dot product(q, d) _scorebyte = 32768 × dims
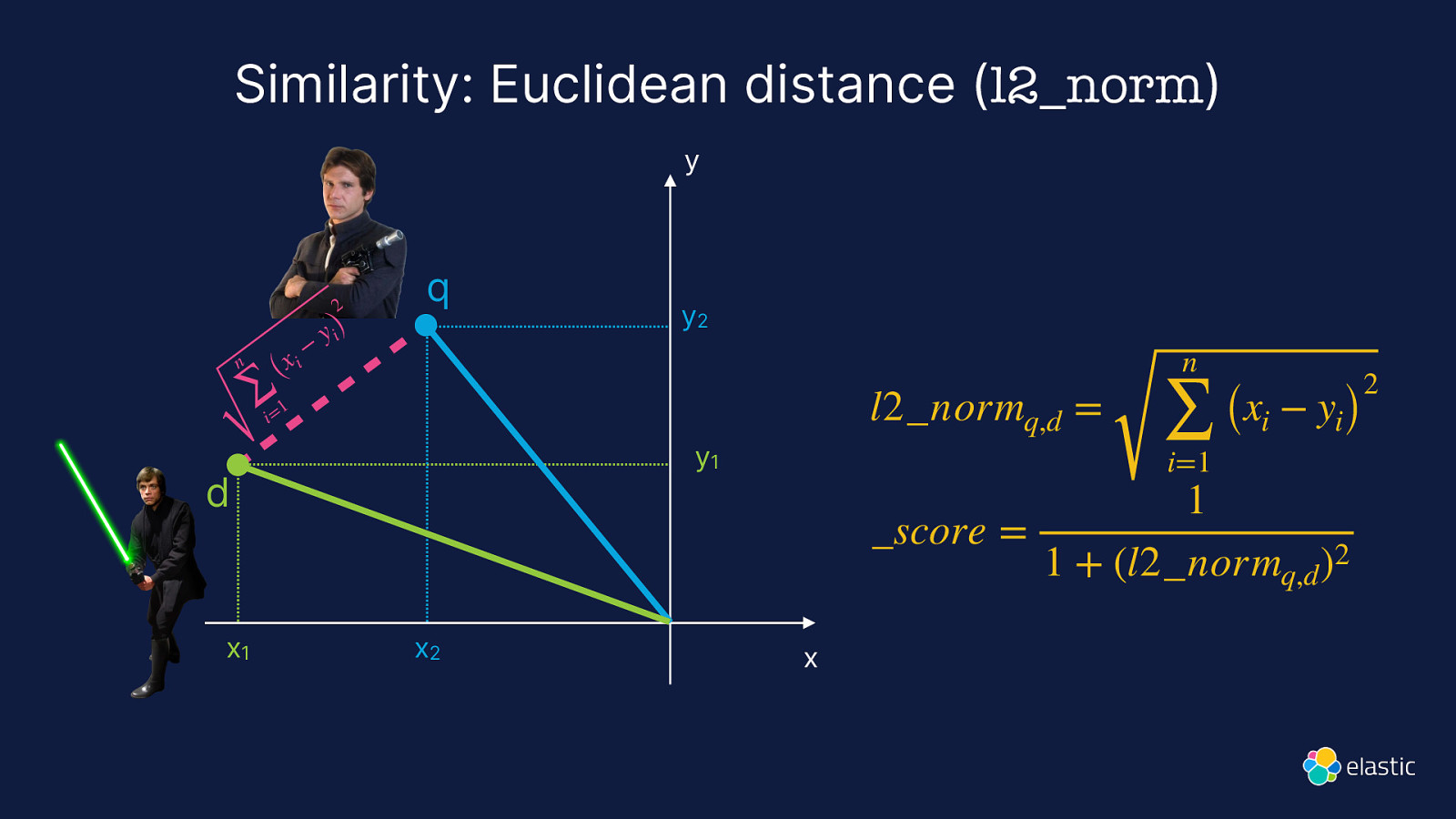
Similarity: Euclidean distance (l2_norm) y 2 n i (x ∑ 1 i= − y i) q l2_normq,d = y1 d x1 y2 x2 n ∑ i=1 (xi − yi) 1 _score = 1 + (l2_normq,d )2 x 2

Brute Force

Hierarchical Navigable Small Worlds (HNSW One popular approach HNSW: a layered approach that simplifies access to the nearest neighbor Tiered: from coarse to fine approximation over a few steps Balance: Bartering a little accuracy for a lot of scalability Speed: Excellent query latency on large scale indices
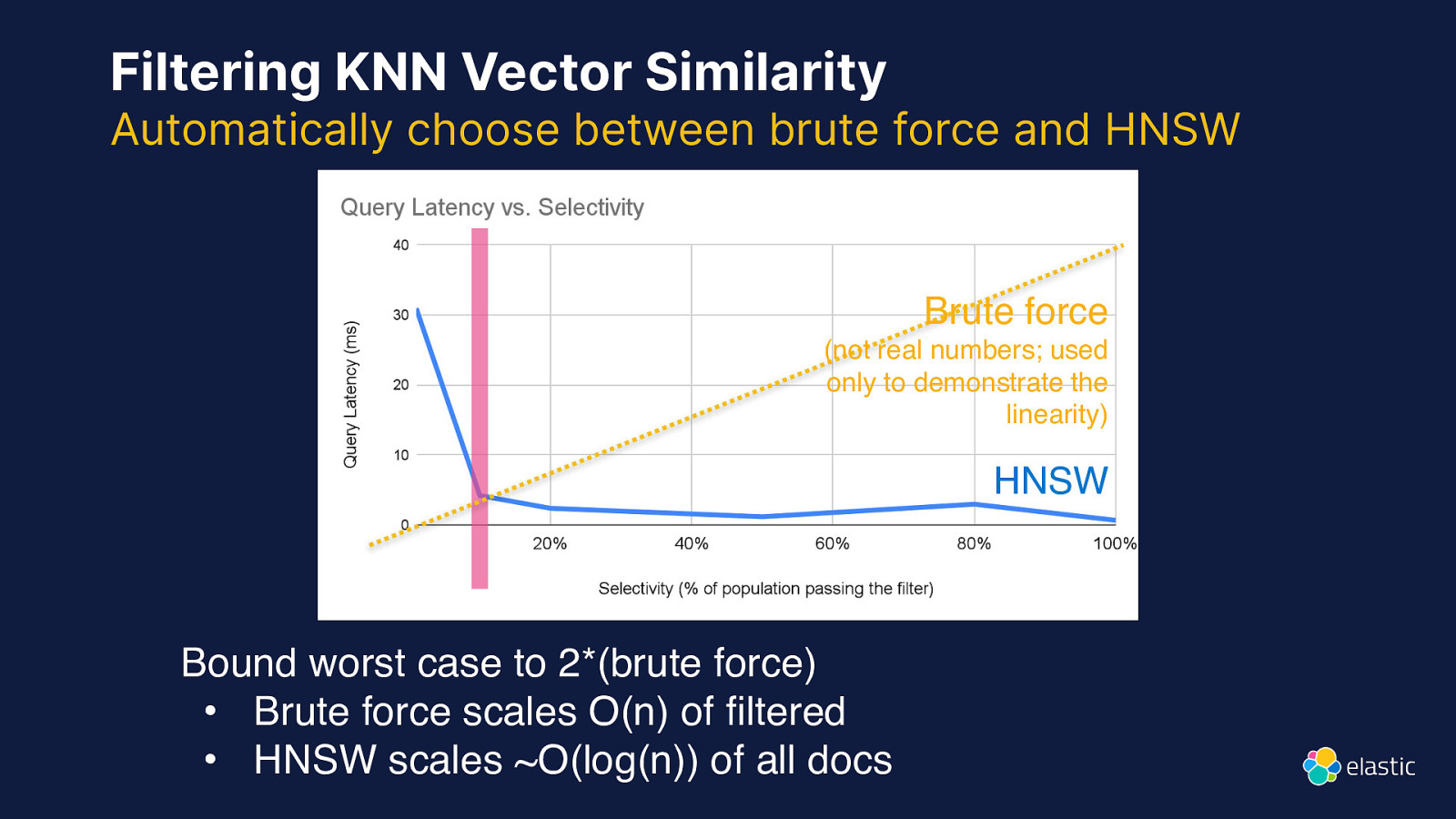
Filtering KNN Vector Similarity Automatically choose between brute force and HNSW Brute force (not real numbers; used only to demonstrate the linearity) HNSW Bound worst case to 2*(brute force) • Brute force scales O(n) of filtered • HNSW scales ~O(log(n)) of all docs
Elasticsearch + Lucene = fast progress ❤

Scaling Vector Search Vector search Best practices
- Needs lots of memory
- Avoid searches during indexing
- Indexing is slower
- Exclude vectors from _source
- Merging is slow
- Reduce vector dimensionality 4. Use byte rather than float
- Continuous improvements in Lucene + Elasticsearch
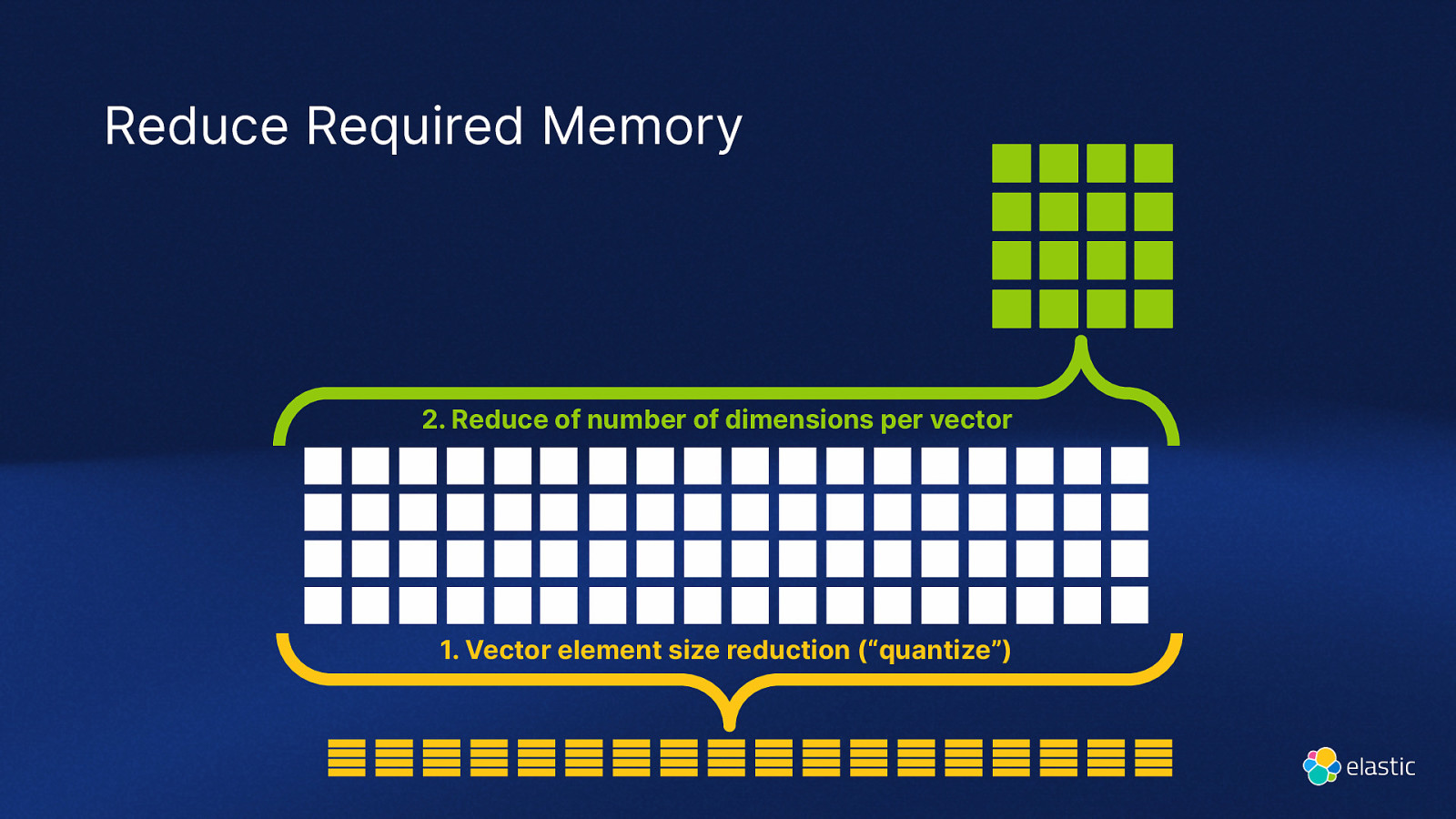
Reduce Required Memory 2. Reduce of number of dimensions per vector
- Vector element size reduction (“quantize”)

Benchmarketing
https://github.com/erikbern/ann-benchmarks

Elasticsearch You Know, for Hybrid Search
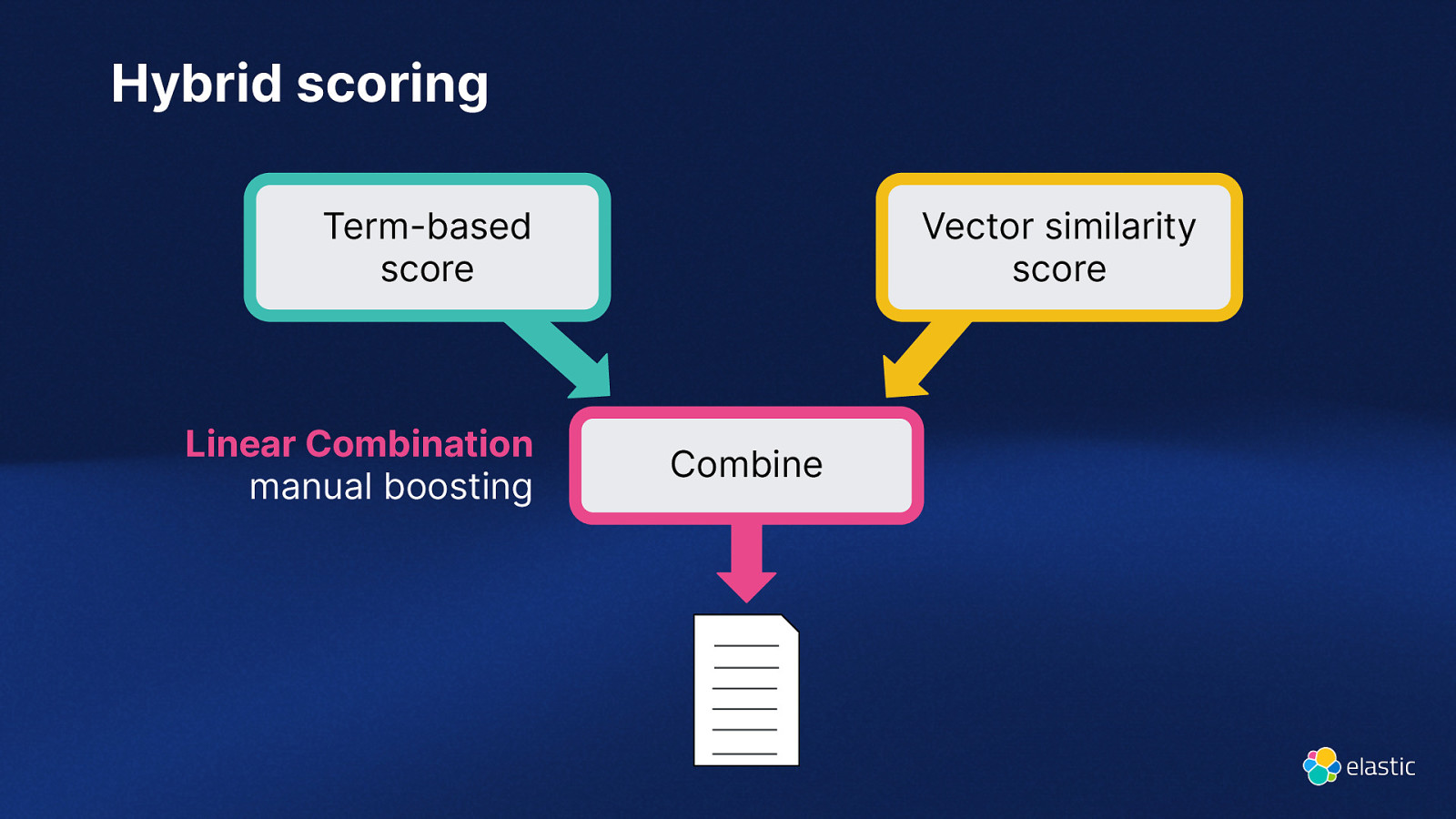
Hybrid scoring Term-based score Linear Combination manual boosting Vector similarity score Combine
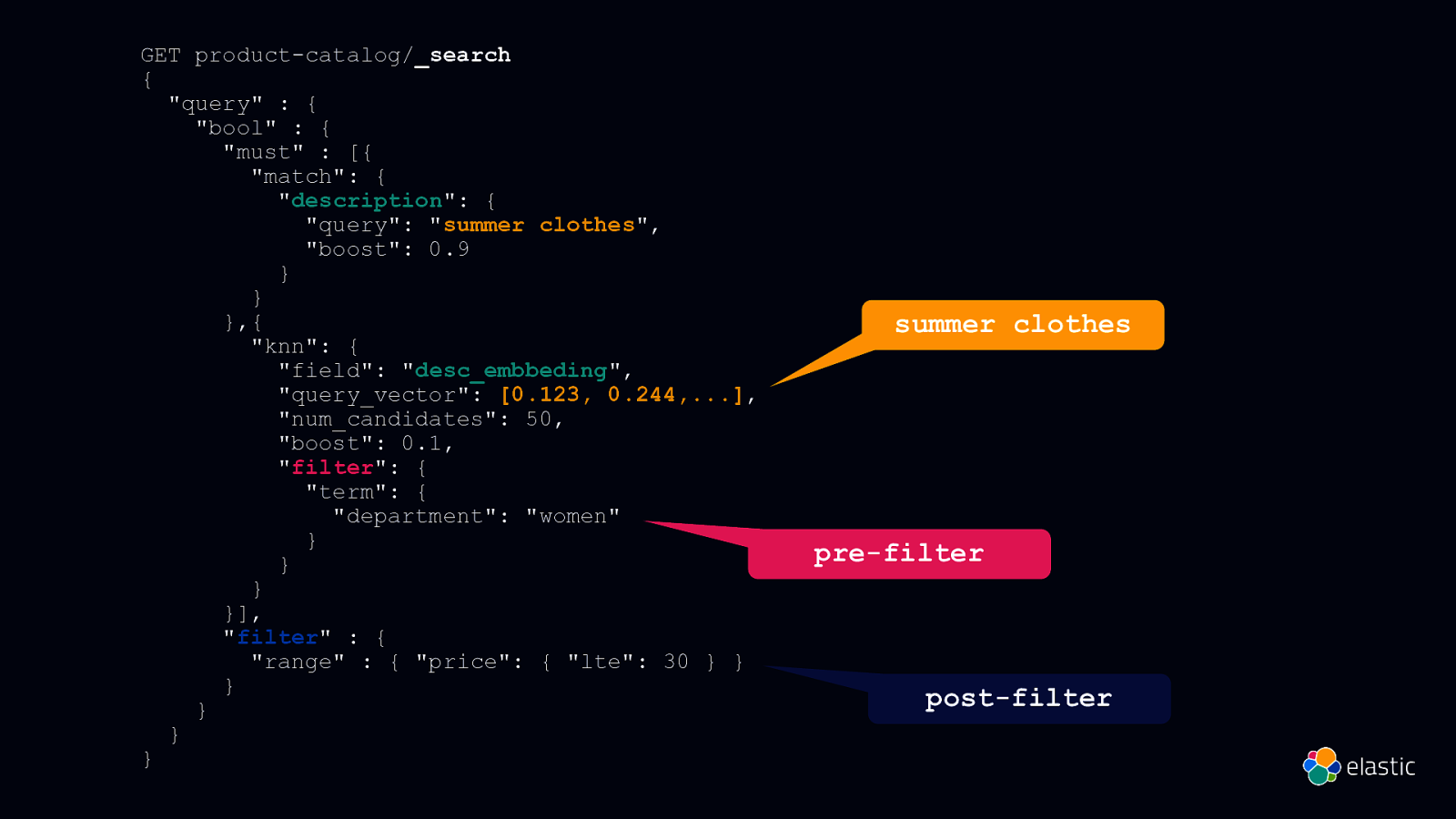
GET product-catalog/_search { “query” : { “bool” : { “must” : [{ “match”: { “description”: { “query”: “summer clothes”, “boost”: 0.9 } } },{ “knn”: { “field”: “desc_embbeding”, “query_vector”: [0.123, 0.244,…], “num_candidates”: 50, “boost”: 0.1, “filter”: { “term”: { “department”: “women” } } } }], “filter” : { “range” : { “price”: { “lte”: 30 } } } } } } summer clothes pre-filter post-filter
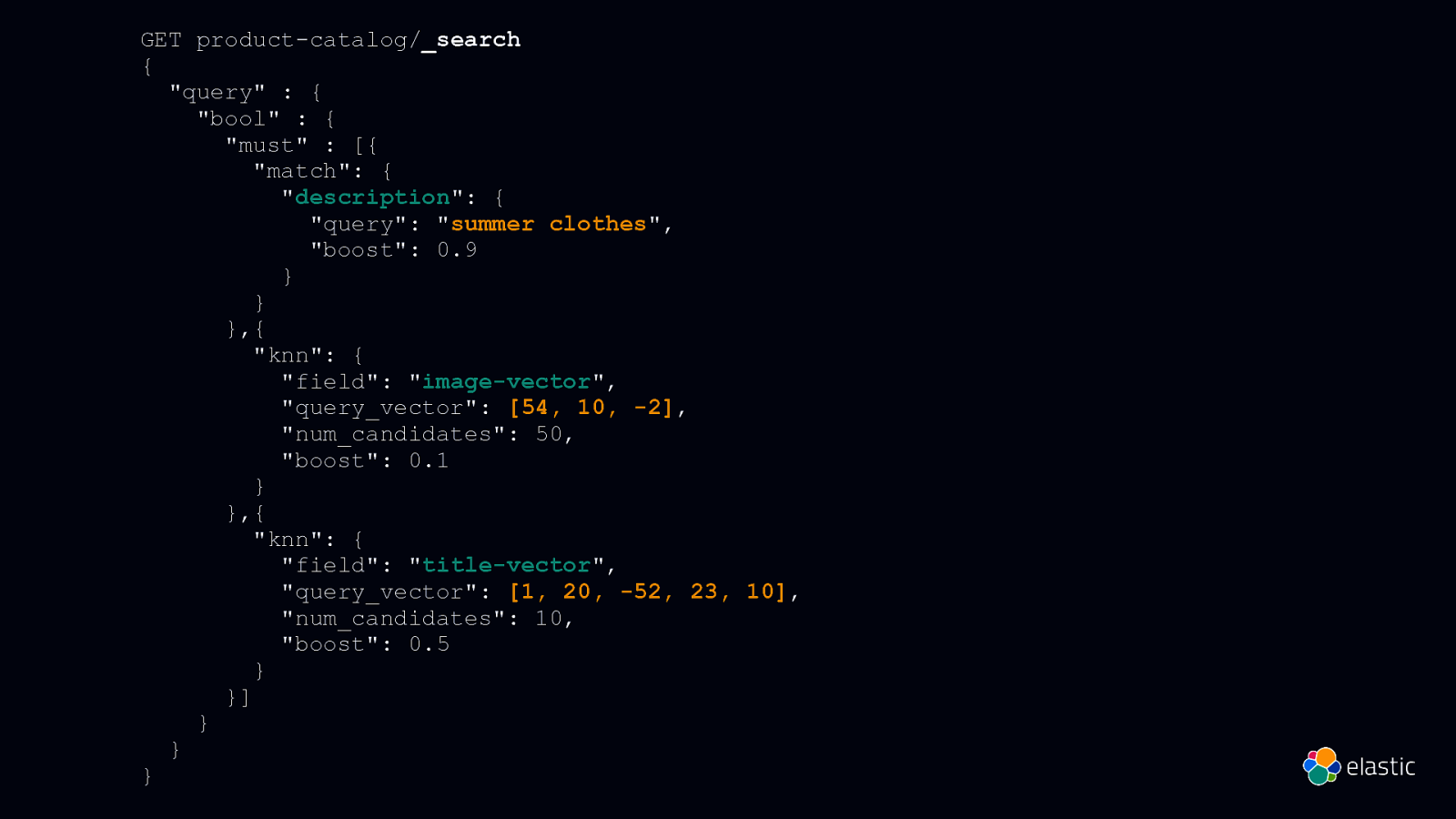
GET product-catalog/_search { “query” : { “bool” : { “must” : [{ “match”: { “description”: { “query”: “summer clothes”, “boost”: 0.9 } } },{ “knn”: { “field”: “image-vector”, “query_vector”: [54, 10, -2], “num_candidates”: 50, “boost”: 0.1 } },{ “knn”: { “field”: “title-vector”, “query_vector”: [1, 20, -52, 23, 10], “num_candidates”: 10, “boost”: 0.5 } }] } } }

ELSER Elastic Learned Sparse EncodER text_expansion Not BM25 or (dense) vector Sparse vector like BM25 Stored as inverted index Co m m er ci al
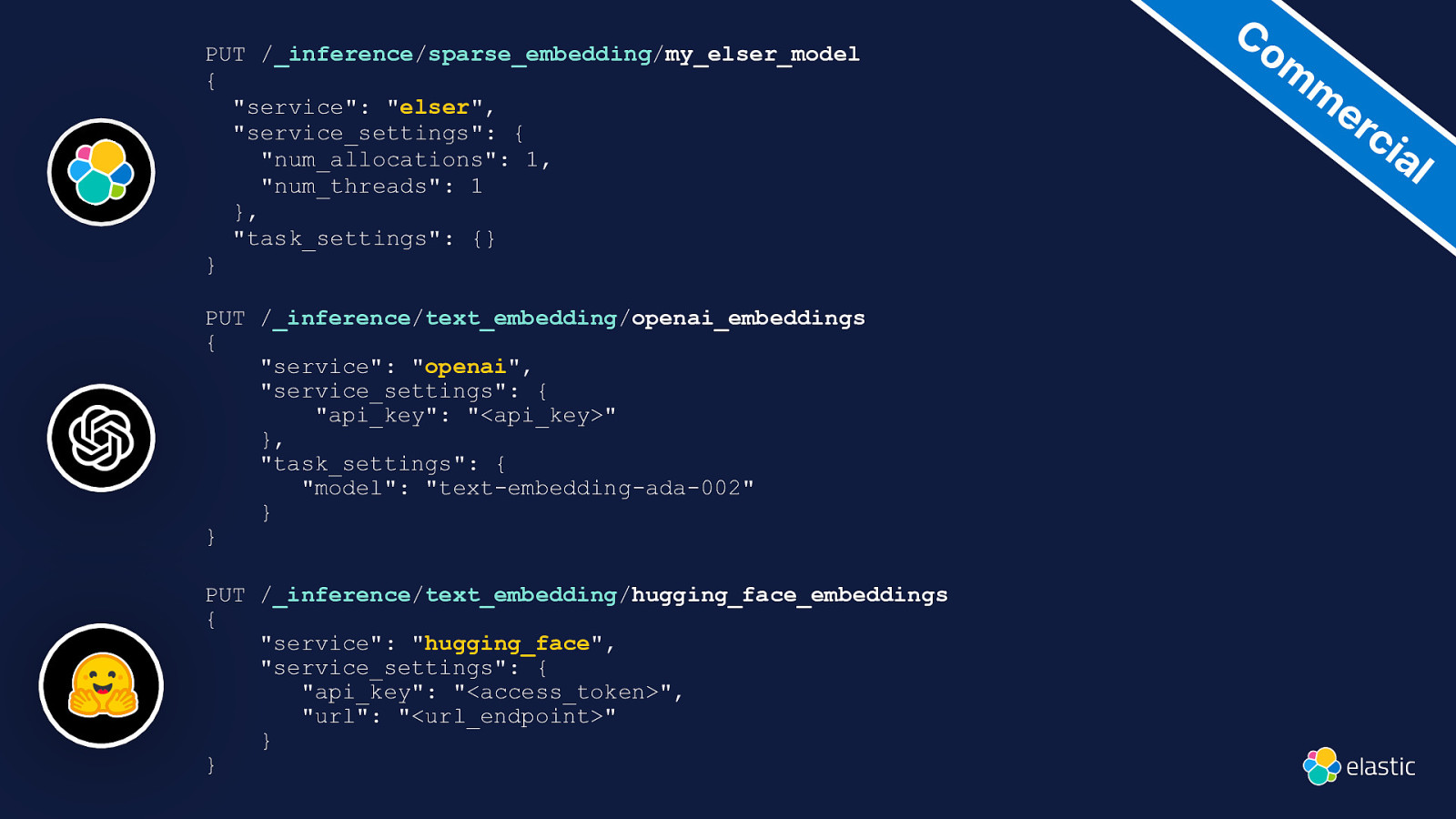
PUT /_inference/sparse_embedding/my_elser_model { “service”: “elser”, “service_settings”: { “num_allocations”: 1, “num_threads”: 1 }, “task_settings”: {} } PUT /_inference/text_embedding/openai_embeddings { “service”: “openai”, “service_settings”: { “api_key”: “<api_key>” }, “task_settings”: { “model”: “text-embedding-ada-002” } } PUT /_inference/text_embedding/hugging_face_embeddings { “service”: “hugging_face”, “service_settings”: { “api_key”: “<access_token>”, “url”: “<url_endpoint>” } } Co m m er ci al
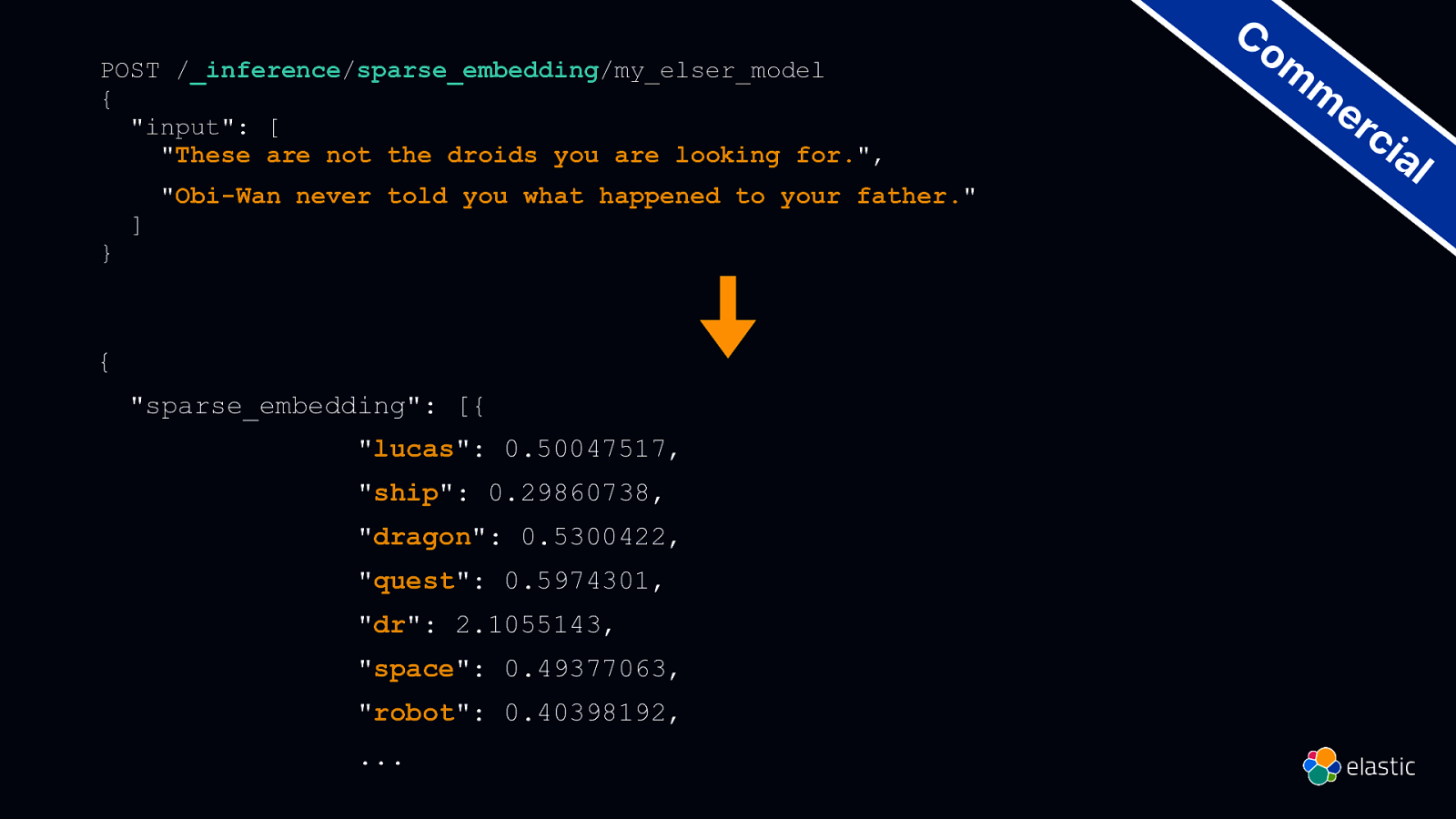
POST /_inference/sparse_embedding/my_elser_model { “input”: [ “These are not the droids you are looking for.”, } ] “Obi-Wan never told you what happened to your father.” { “sparse_embedding”: [{ “lucas”: 0.50047517, “ship”: 0.29860738, “dragon”: 0.5300422, “quest”: 0.5974301, “dr”: 2.1055143, “space”: 0.49377063, “robot”: 0.40398192, … Co m m er ci al
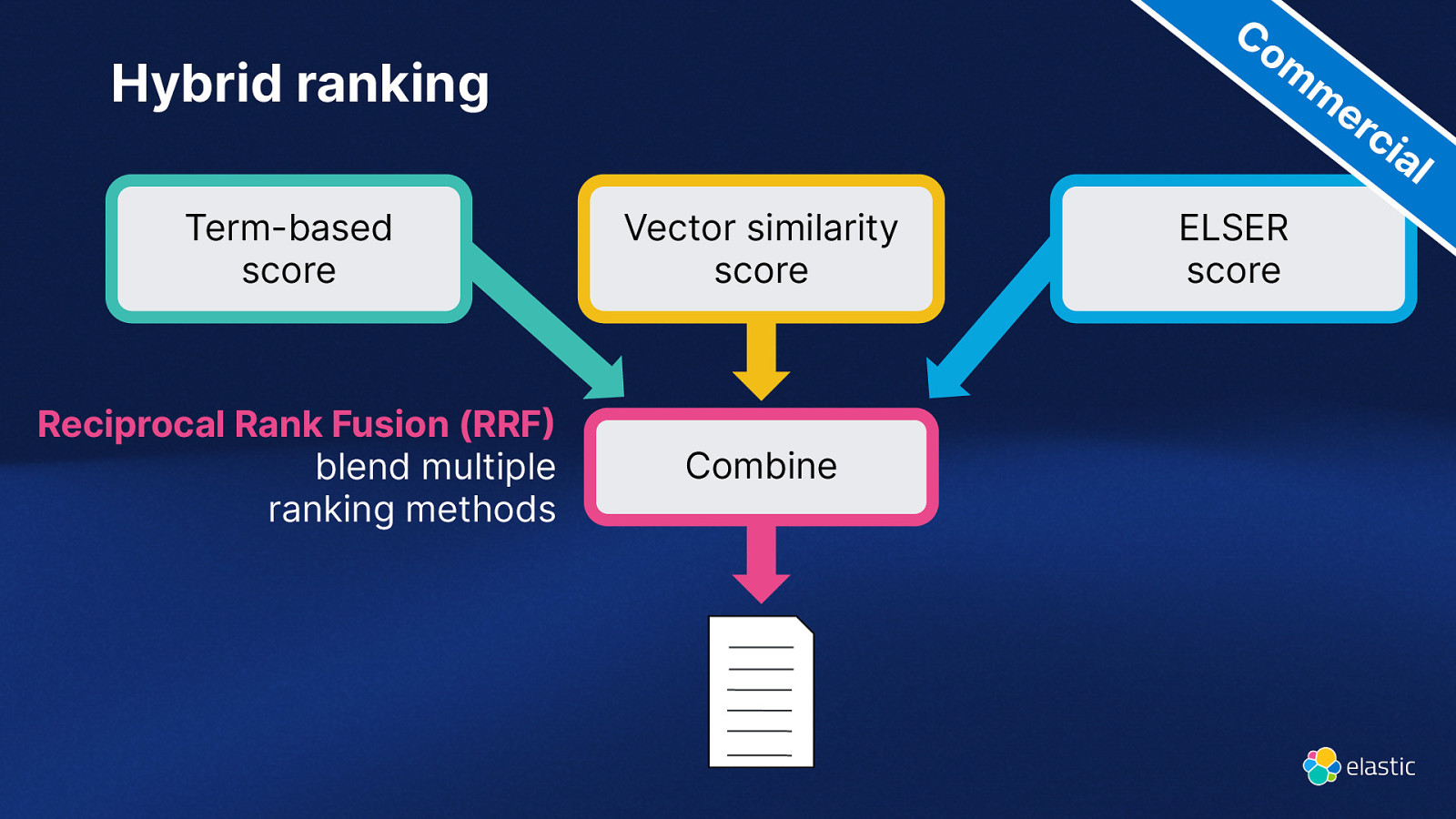
Co m m er ci Hybrid ranking al Term-based score Vector similarity score Reciprocal Rank Fusion (RRF blend multiple ranking methods Combine ELSER score
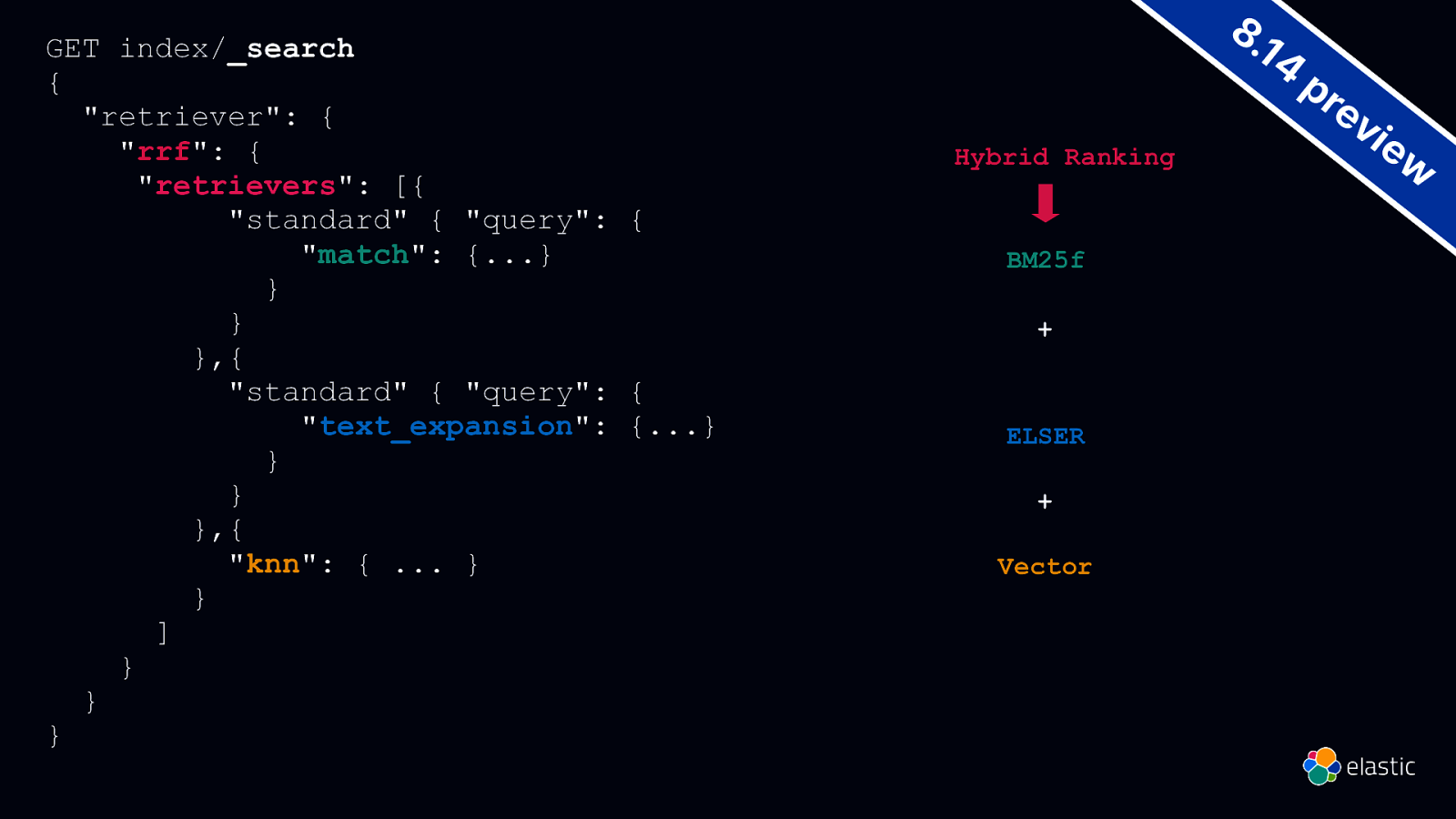
GET index/_search { “retriever”: { “rrf”: { “retrievers”: [{ “standard” { “query”: { “match”: {…} } } },{ “standard” { “query”: { “text_expansion”: {…} } } },{ “knn”: { … } } ] } } } 8. 14 Hybrid Ranking BM25f + ELSER + Vector pr ev ie w

Reciprocal Rank Fusion (RRF D set of docs R set of rankings as permutation on 1..|D| k - typically set to 60 by default Ranking Algorithm 1 Doc Ranking Algorithm 2 Score r(d) k+r(d) A 1 1 B 0.7 C D E Doc Score r(d) k+r(d) 61 C 1,341 1 61 2 62 A 739 2 62 0.5 3 63 F 732 3 63 0.2 4 64 G 192 4 64 0.01 5 65 H 183 5 65 Doc RRF Score A 1/61 1/62 0,0325 C 1/63 1/61 0,0323 B 1/62 0,0161 F 1/63 0,0159 D 1/64 0,0156

https://djdadoo.pilato.fr/
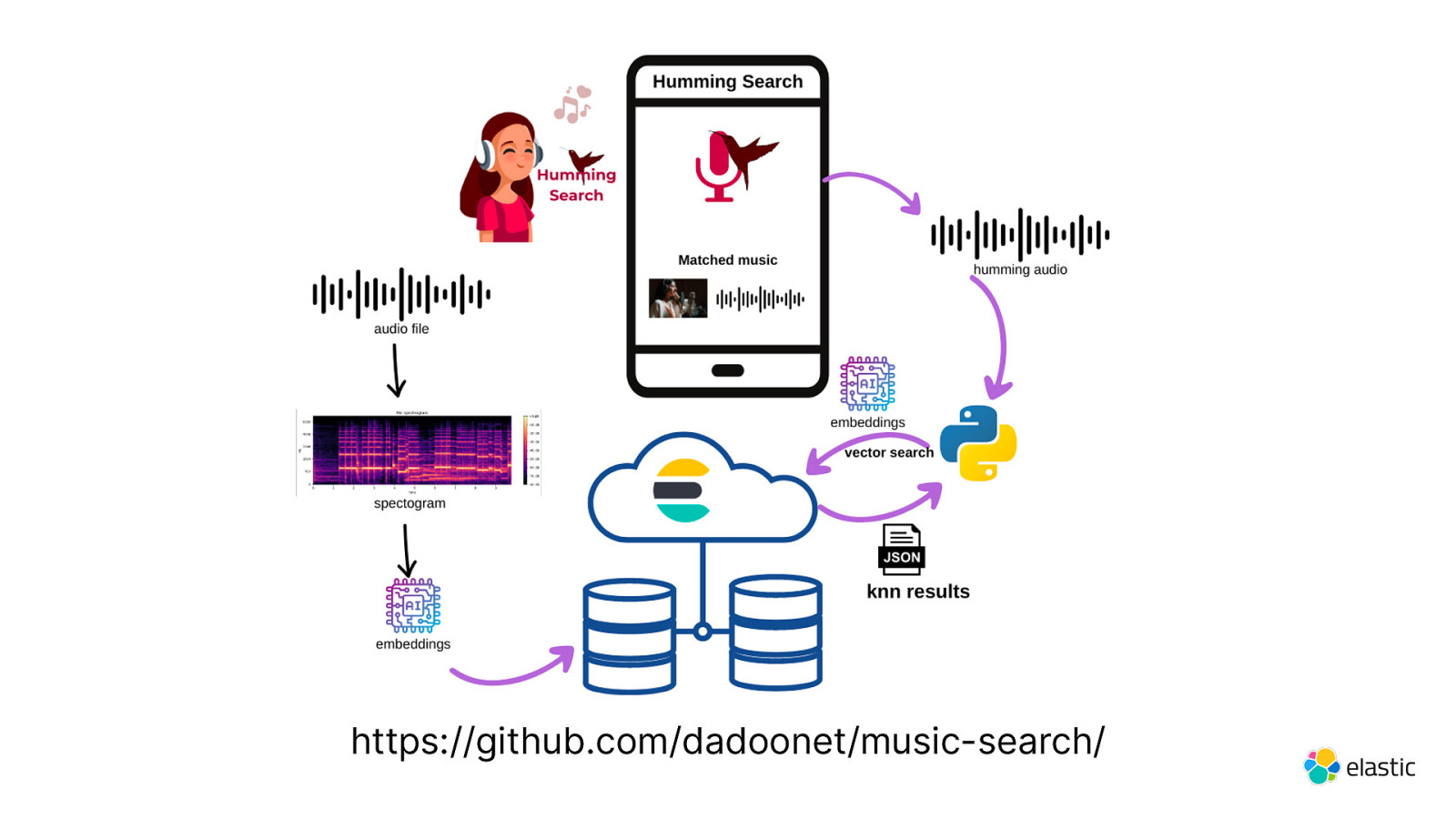
https://github.com/dadoonet/music-search/

ChatGPT Elastic and LLM

Gen AI Search engines
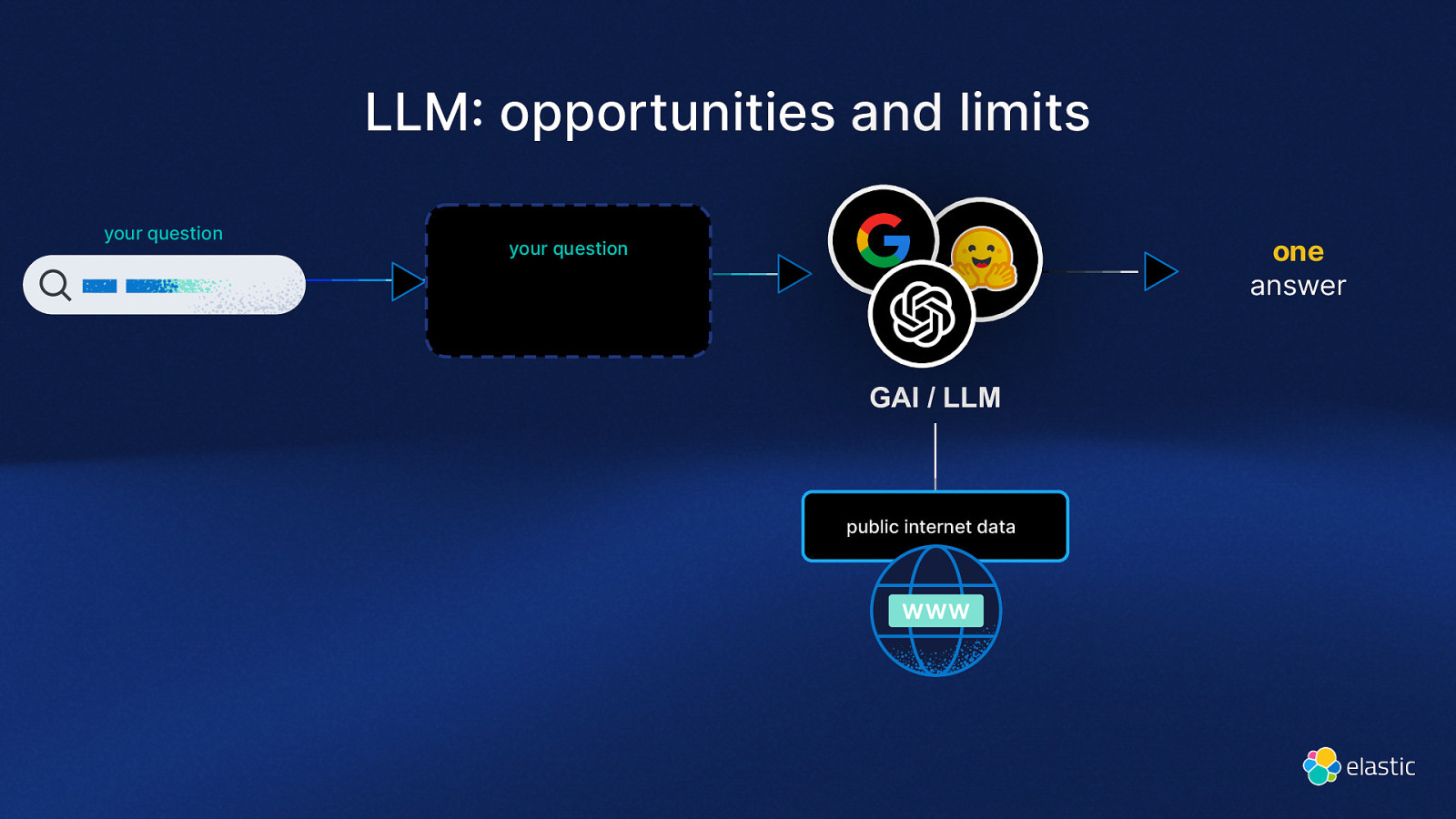
LLM opportunities and limits your question one answer your question GAI / LLM public internet data
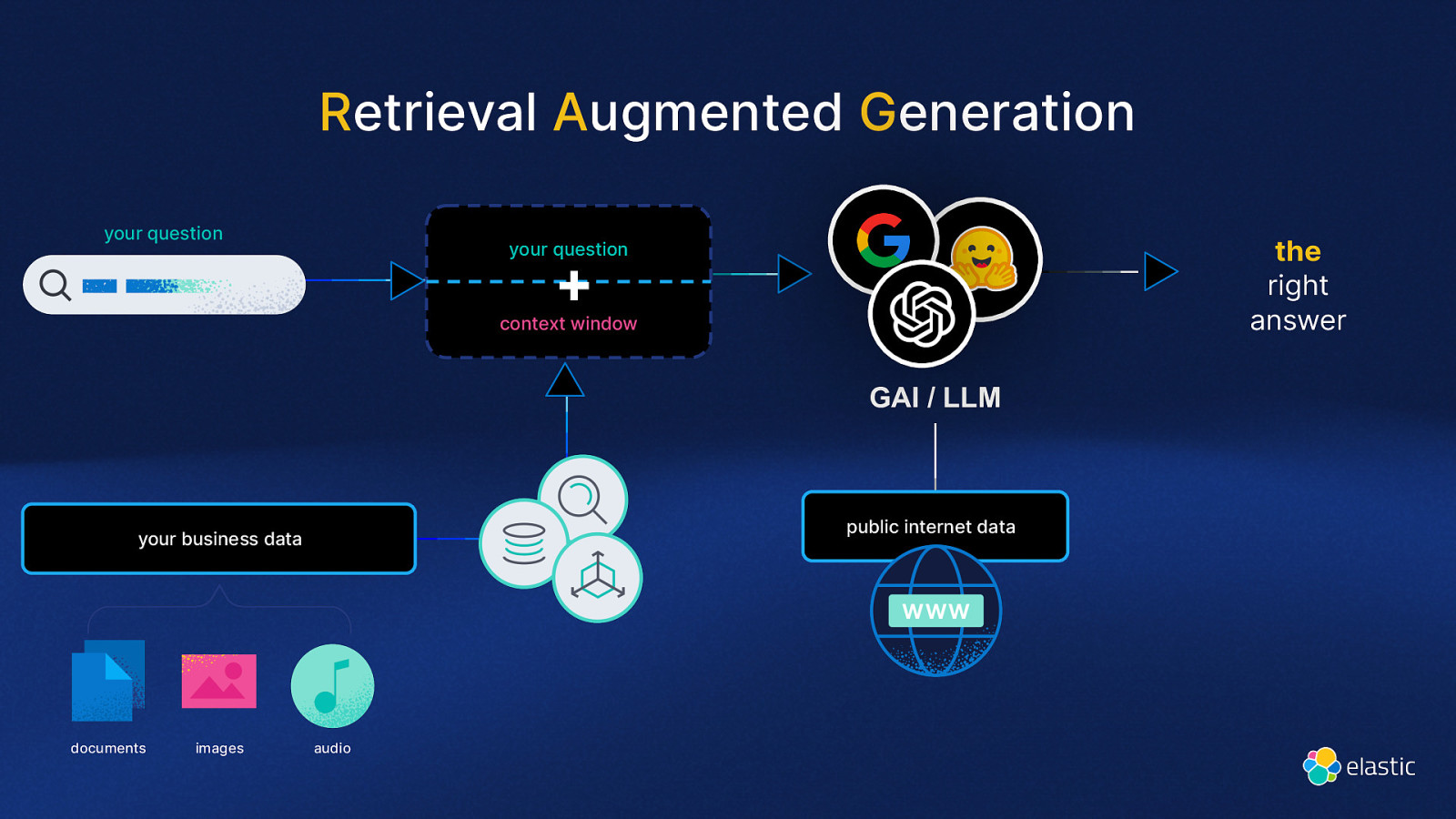
Retrieval Augmented Generation your question the right answer your question + context window GAI / LLM public internet data your business data documents images audio

- 14 Demo Elastic Playground pr ev ie w

Conclusion
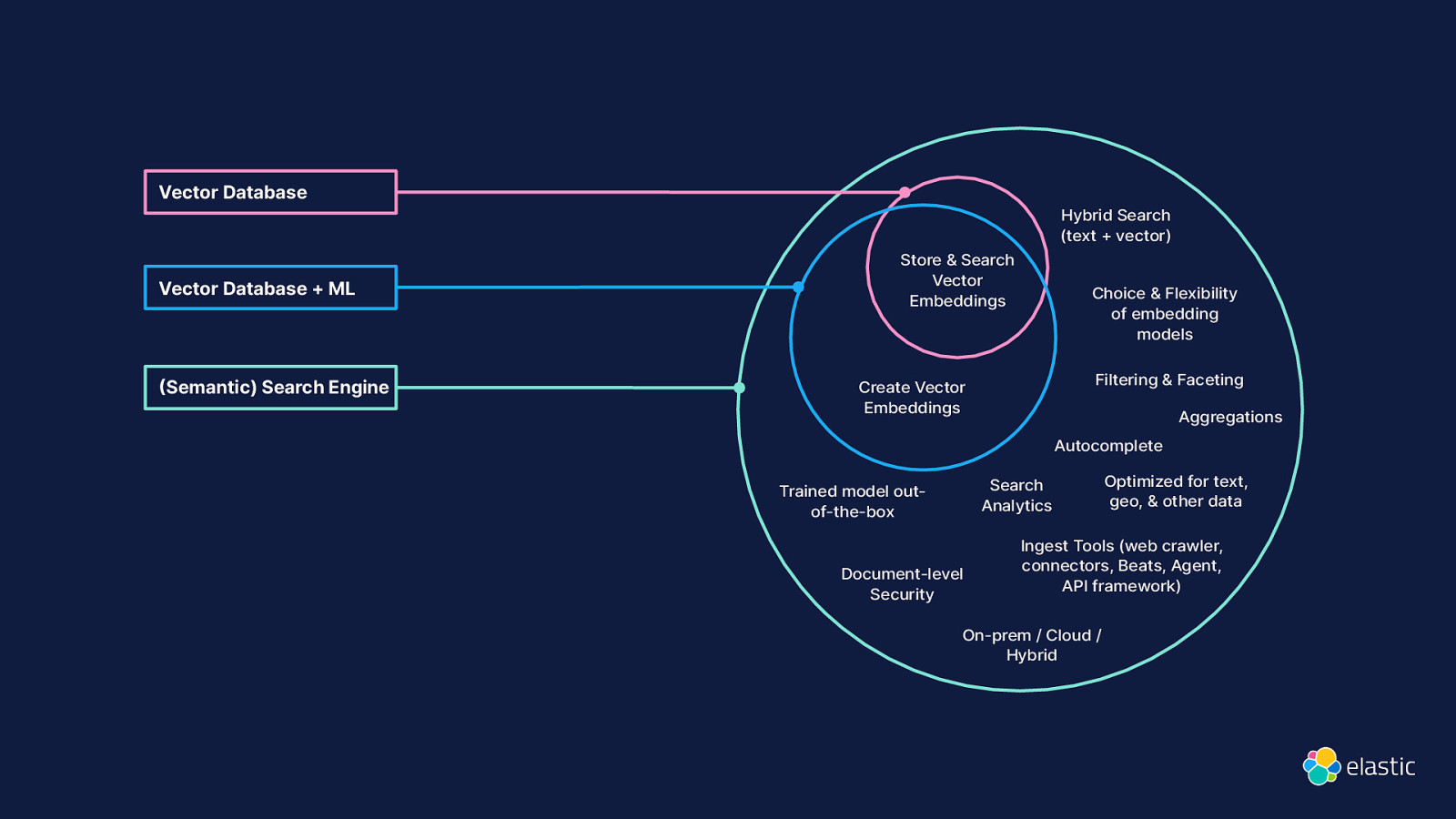
Vector Database Vector Database + ML Semantic) Search Engine Hybrid Search (text + vector) Store & Search Vector Embeddings Choice & Flexibility of embedding models Filtering & Faceting Create Vector Embeddings Aggregations Autocomplete Search Analytics Trained model outof-the-box Document-level Security Optimized for text, geo, & other data Ingest Tools (web crawler, connectors, Beats, Agent, API framework) On-prem / Cloud / Hybrid

Elasticsearch You Know, for Semantic Search

Search & AI a new era David Pilato | @dadoonet

Search is not just traditional TF/IDF any more but the current trend of machine learning and models has opened another dimension for search.
This talk gives an overview of:
- “Classic” search and its limitations
- What is a model and how can you use it
- How to use vector search or hybrid search in Elasticsearch
- Where OpenAI’s ChatGPT or similar LLMs come into play to with Elastic
This talk covers the state of the art in terms of search nowadays: BM25, Vector search, Embeddings, Hybrid Search, Reciprocal Rank Fusion, and OpenAI integration. The main demo covers how to generate embeddings from a piece of music and then use the techniques we learned to propose the most probable version of it when we hum a song.
Resources
The following resources were mentioned during the presentation or are useful additional information.
Buzz and feedback
Here’s what was said about this presentation on social media.